
Всем привет! Несколько месяцев назад мы запустили в продакшн наш новый open-source проект — Grafana-плагин для мониторинга kubernetes, который назвали DevOpsProdigy KubeGraf. Исходный код плагина доступен в публичном репозитории на GitHub. А в этой статье мы хотим поделиться с вами историей о том, как мы создавали плагин, какие инструменты использовали и с какими подводными камнями столкнулись в процессе разработки. Погнали!
Часть 0 — вводная: как мы до этого докатились?
Идея написать свой собственный плагин для Grafan’ы у нас родилась совершенно случайно. Наша компания уже более 10 лет занимается мониторингом web-проектов различного уровня сложности. За это время мы наработали большой багаж экспертизы, интересных кейсов, опыта использования различных систем мониторинга. И в какой-то момент мы задались вопросом: «А существует ли волшебный инструмент для мониторинга Kubernetes, чтобы, как говорится, “поставил и забыл”»?.. Промстандартом для мониторинга k8s, естественно, давно является связка Prometheus + Grafana. И в качестве готовых решений для данного стэка существует большой набор различного рода инструментов: prometheus-operator, набор дашбордов kubernetes-mixin, grafana-kubernetes-app.
И в какой-то момент мы решили: «А не сделать ли нам свое собственное решение?» Наиболее интересным вариантом для нас показался плагин grafana-kubernetes-app, но он не поддерживается уже больше года и, к тому же, не умеет работать с новыми версиями node-exporter’а и kube-state-metrics’а.
Какие идеи мы решили реализовать в своем плагине:
- визуализация «карты приложения»: удобное представление приложений в кластере, сгруппированных по namespace’ам, deployment’ам…;
- визуализация связей вида «deployment — service (+ports)».
- визуализация распределения приложений кластера по nod’ам кластера.
- сбор метрик и информации из нескольких источников: Prometheus и k8s api server.
- мониторинг как инфраструктурной части (использование процессорного времени, памяти, дисковой подсистемы, сети), так и логики приложений — health-status pod’ов, количество доступных реплик, информация о прохождении liveness/readyness-проб.
Часть 1: Что такое «плагин для Grafana»?
С технической точки зрения, плагин для Grafana — это angular-контроллер, который хранится в data-директории Grafan’ы (/var/grafana/plugins/<your_plugin_name>/dist/module.js) и можeт быть загружен как SystemJS-модуль. Также в этой директории должен находиться файл plugin.json, содержащий в себе всю метаинформацию о вашем плагине: название, версия, тип плагина, ссылки на репозиторий/сайт/лицензию, зависимости и так далее.

module.ts

plugin.json
Ибо плагины для Grafana могут быть трех видов: Как видно на скриншоте, мы указали plugin.type = app.
Также в качестве зависимостей могут использоваться плагины других типов (datasource, panel) и различные дашборды. panel: самый распространенный тип плагинов — представляет собой панель для визуализации каких-либо метрик, используется для построения различных дашбордов.
datasource: плагин-коннектор до какого-либо источника данных (например, Prometheus-datasource, ClickHouse-datasource, ElasticSearch-datasource).
app: плагин, позволяющий вам построить свое собственное фронтенд-приложение внутри Grafana, создавать свои собственные html-страницы и вручную обращаться к datasource для визуализации различных данных.

Пример зависимостей плагина с type = app.
Заготовки для hello-world плагинов любого типа вы можете найти по ссылке: в данном репозитории представлено большое количество starter-pack’ов (есть даже экспериментальный пример плагина на React) с предустановленными и настроенными сборщиками. В качестве языка программирования можно использовать как JavaScript, так и TypeScript (мы свой выбор остановили на нем).
Часть 2: подготовка локального окружения
Для работы над плагином нам, естественно, понадобится kubernetes-кластер со всеми предустановленными инструментами: prometheus, node-exporter, kube-state-metrics, grafana. Окружение должно сетапиться быстро, легко и непринужденно, а для обеспечения hot-reload data-директория Grafana должна монтироваться непосредственно с машины разработчика.
Следующим шагом устанавливаем связку Prometheus + Grafana c помощью prometheus-operator. Самым удобным, на наш взгляд, способом локальной работы с kubernetes является minikube. Для включения персистентности необходимо установить параметр persistence: true в файле charts/grafana/values.yaml, добавить свой собственный PV и PVC и указать их в параметре persistence.existingClaim В данной статье подробно описан процесс установки prometheus-operator на minikube.
Итоговый скрипт запуска minikube у нас выглядит вот так:
minikube start --kubernetes-version=v1.13.4 --memory=4096 --bootstrapper=kubeadm --extra-config=scheduler.address=0.0.0.0 --extra-config=controller-manager.address=0.0.0.0
minikube mount /home/sergeisporyshev/Projects/Grafana:/var/grafana --gid=472 --uid=472 --9p-version=9p2000.L
Часть 3: непосредственно разработка
Объектная модель
Каждый из этих классов наследуется от общего класса BaseModel, в котором описаны конструктор, деструктор, методы для обновления и переключения видимости. В качестве подготовки к реализации плагина мы решили описать все базовые сущности Kubernetes, с которыми мы будем работать в виде TypeScript-классов: pod, deployment, daemonset, statefulset, job, cronjob, service, node, namespace. В каждом из классов описаны вложенные отношения с другими сущностями, например, список pod’ов у сущности типа deployment.
import from "./pod";
import {Service} from "./service";
import {BaseModel} from './traits/baseModel'; export class Deployment extends BaseModel{ pods: Array<Pod>; services: Array<Service>; constructor(data: any){ super(data); this.pods = []; this.services = []; }
}
C помощью getter’ов и setter’ов мы можем выводить или устанавливать нужные нам метрики сущностей в удобном и читабельном виде. Например отформатированный вывод allocatable cpu nod’ы:
get cpuAllocatableFormatted(){ let cpu = this.data.status.allocatable.cpu; if(cpu.indexOf('m') > -1){ cpu = parseInt(cpu)/1000; } return cpu;
}
Pages
Список всех страниц нашего плагина изначально описывается в нашем pluing.json в разделе зависимостей:
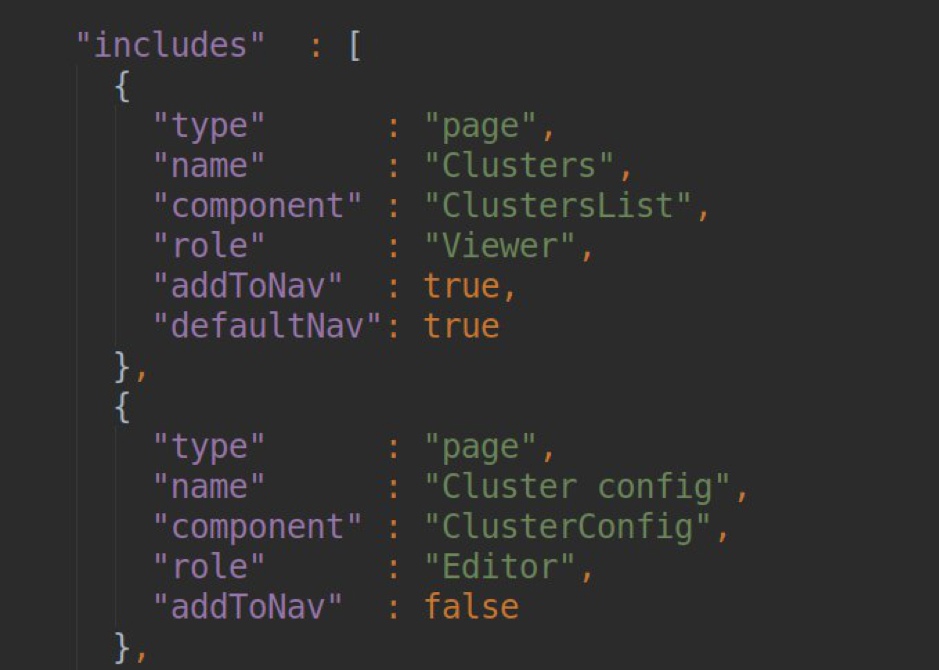
В блоке для каждой страницы мы должны указать НАЗВАНИЕ СТРАНИЦЫ (оно затем будет сконвертировано в slug, по которому эта страница будет доступна); название компонента, отвечающего за работу этой странице (список компонентов экспортится в module.ts); указание роли пользователя, для которого доступна работа с этой страницей и настройки навигации для боковой панели.
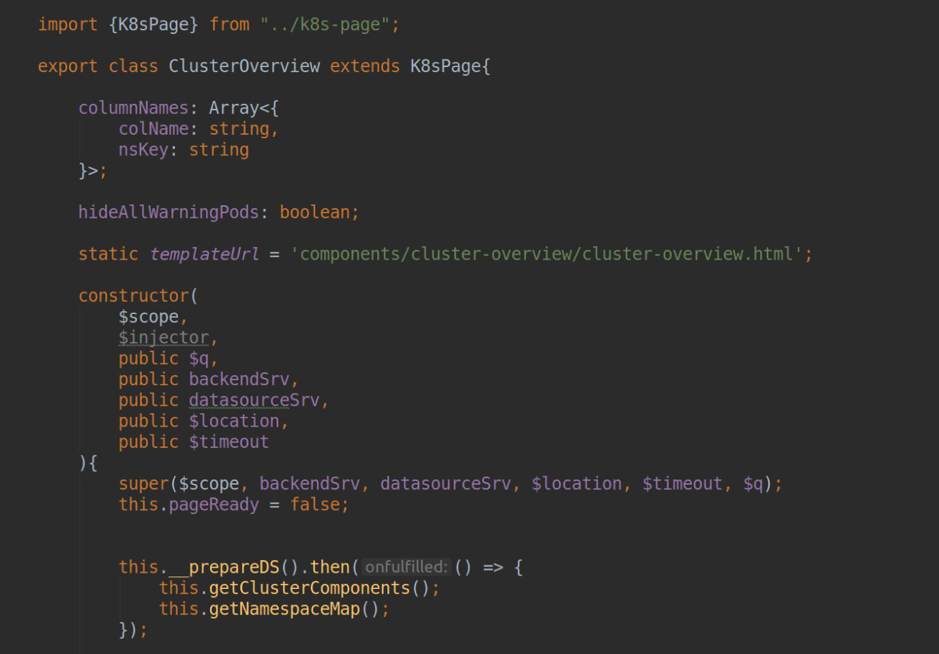
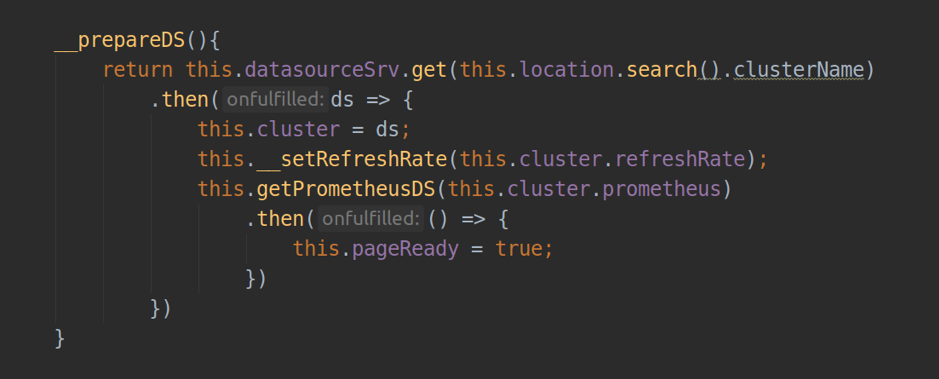
Внутри контроллера, через dependency injection, мы можем получить доступ до 2-х важных angular-сервисов: В компоненте, отвечающем за работу страницы, мы должны установить templateUrl, передав туда путь до html-файла с разметкой.
- backendSrv — сервис, обеспечивающий взаимодействие с api-сервером графаны;
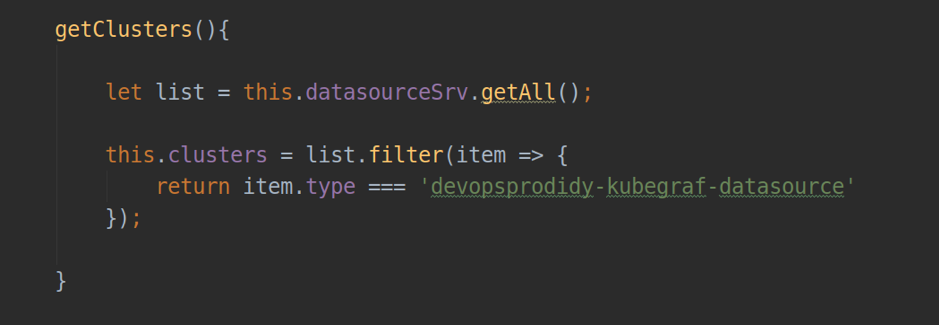
- datasourceSrv — сервис, обеспечивающий локальное взаимодействие со всеми datasource, установленными в вашей Grafana (например, метод .getAll() — возвращает список всех установленных datasource’ов; .get(<nаme>) — возвращает объект-инстанс конкретного datasource.
Часть 4: datasource
С точки зрения Grafana, datasource представляет собой точно такой же плагин, как и все остальные: у него есть своя точка входа module.js, есть файл с метаинформацией plugin.json. При разработке плагина с type = app мы можем взаимодействовать как с уже существующими datasource’ами (например, prometheus-datasource), так и своими собственными, которые мы можем хранить непосредственно в директории плагина (dist/datasource/*) или устанавливать как зависимость. В нашем случае datasource поставляется вместе с кодом плагина. Также обязательно наличие шаблона config.html и контроллера ConfigCtrl, которые будут использоваться для страницы конфигурирования экземпляра datasource’а и контроллера Datasource, в котором реализуется логика работы вашего datasource’а.
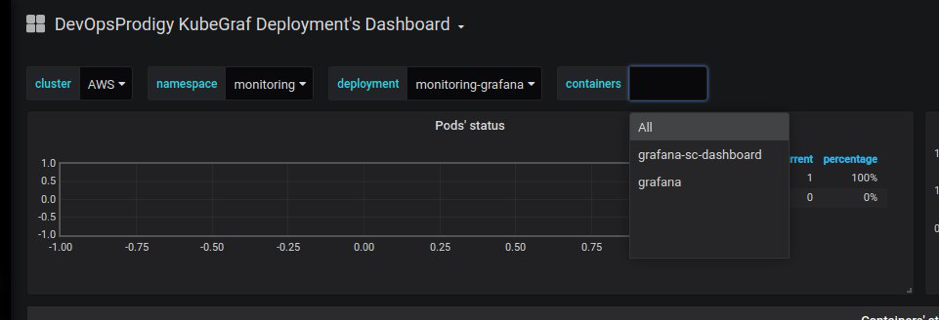
В плагине KubeGraf, с точки зрения пользовательского интерфейса, datasource представляет собой экземпляр kubernetes-кластера, в котором реализованы следующие возможности (исходный код доступен по ссылке):
- забор данных из api-server’а k8s (получение списка namespace’ов, deployment’ов…)
- проксирование запросов в prometheus-datasource (который выбирается в настройках плагина для каждого конкретного кластера) и форматирование ответов для использования данных как в статичных страницах, так и в дашбордах.
- обновление данных на статичных страницах плагина (с установленным временем refresh rate).
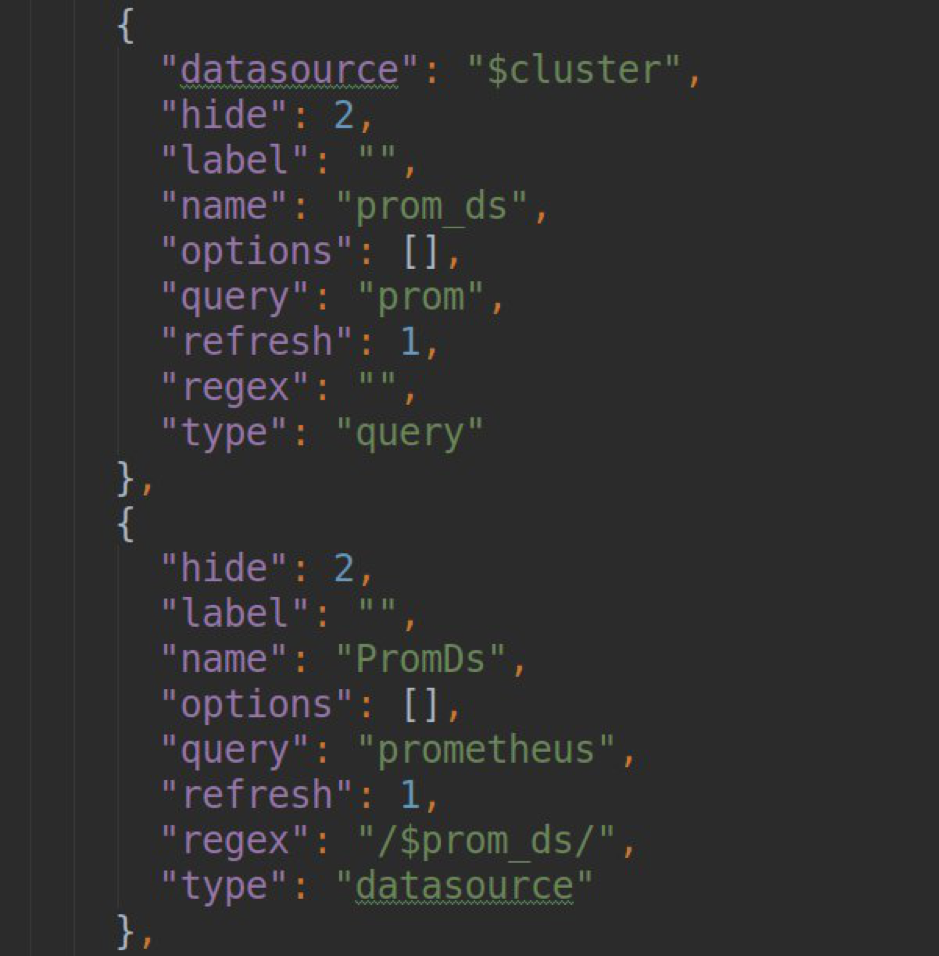
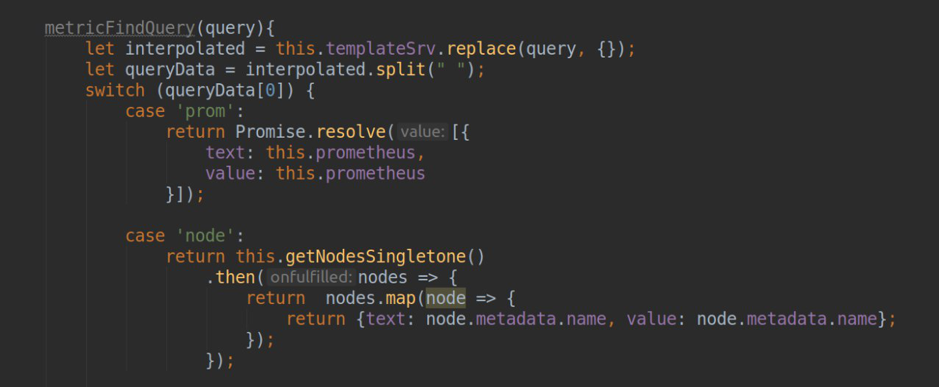
- обработка запросов для формирования template-листа в grafana-dashboards (метод .metriFindQuery())
- тест соединения с конечным k8s-кластером.
testDatasource(){ let url = '/api/v1/namespaces'; let _url = this.url; if(this.accessViaToken) _url += '/__proxy'; _url += url; return this.backendSrv.datasourceRequest({ url: _url, method: "GET", headers: {"Content-Type": 'application/json'} }) .then(response => { if (response.status === 200) { return {status: "success", message: "Data source is OK", title: "Success"}; }else{ return {status: "error", message: "Data source is not OK", title: "Error"}; } }, error => { return {status: "error", message: "Data source is not OK", title: "Error"}; })
}
Отдельным интересным моментом, на наш взгляд, является реализация механизма аутентификации и авторизации для datasource. Как правило, из коробки для конфигурации доступа до конечного источника данных мы можем использовать встроенный компонент Grafana — datasourceHttpSettings. С помощью этого компонента мы можем настроить доступ до http-источника данных, указав url и базовые настройки аутентификации/авторизации: логин-пароль, или client-cert/client-key. Для того чтобы реализовать возможность настройки доступа с помощью bearer-токена (дефакто стандарт для k8s), пришлось немного «похимичить».
В настройках нашего datasource’а мы можем объявить набор правил роутинга, которые будут обрабатываться proxy-сервером grafana. Для решения этой задачи можно использовать встроенный механизм Grafana «Plugin Routes» (подробнее на официальной странице документации). В нашем примере запросы вида /__proxy/api/v1/namespaces будут проксироваться на url вида
<your_k8s_api_url>/api/v1/namespaces с проставлением заголовка Authorization: Bearer . Например, для каждого отдельного endpoint’а существует возможность проставления заголовков или url с возможностью шаблонизирования, данные для которых могут браться из полей jsonData и secureJsonData (для хранения паролей или токенов в шифрованном виде).
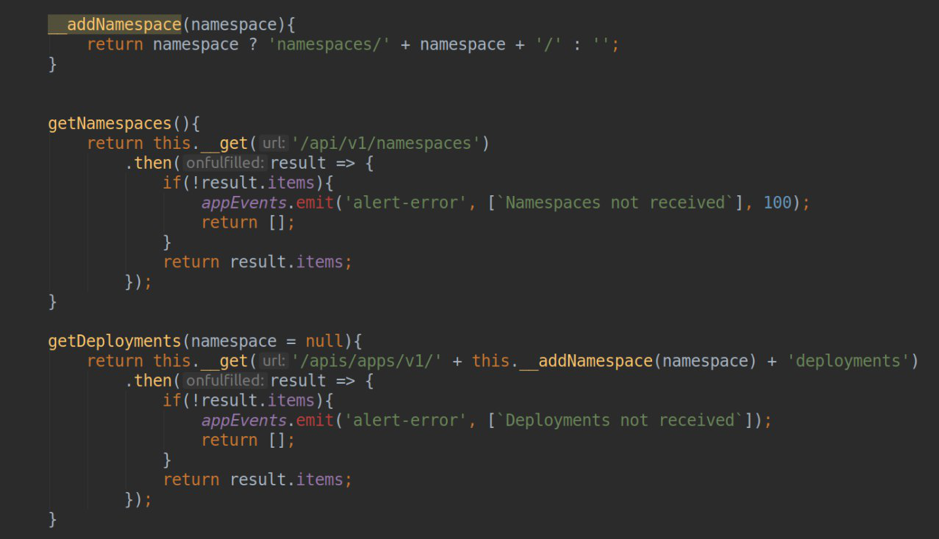
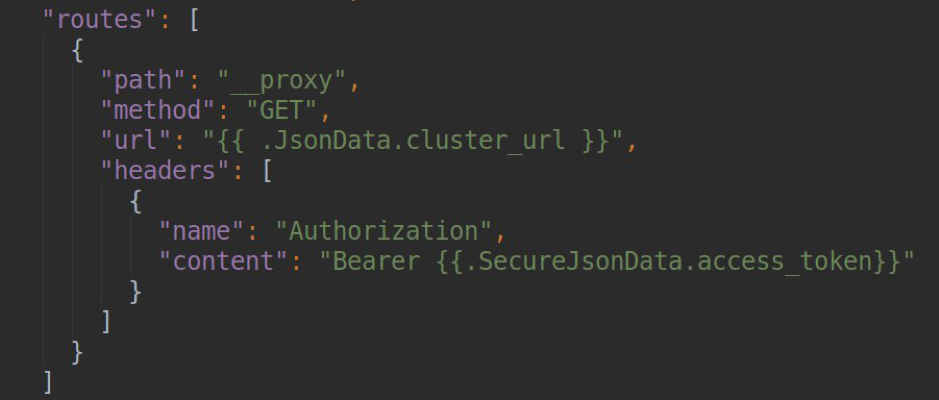
Естественно, для работы с api-сервером k8s нам необходим пользователь с readonly доступами, манифесты для создания которого вы можете также найти в исходном коде плагина.
Часть 5: релиз

В Grafana это библиотека плагинов, доступная по ссылке grafana.com/grafana/plugins После того, как вы напишете свой собственный плагин для Grafana, вам, естественно, захочется выложить его в открытый доступ.
Для того чтобы ваш плагин был доступен в официальном сторе, вам необходимо сделать PR в этот репозиторий, добавив в файл repo.json содержимое вида:
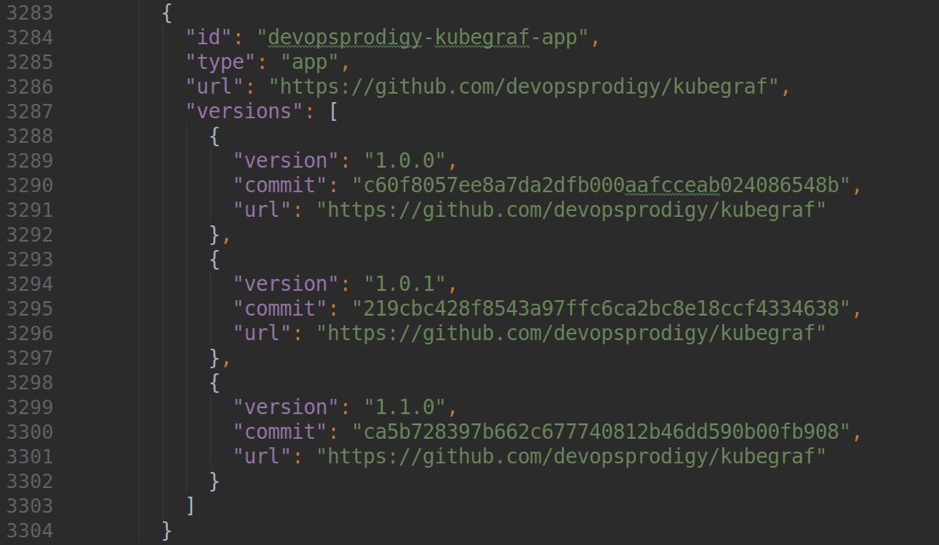
где version — версия вашего плагина, url — ссылка на репозиторий, а commit — hash коммита, по которому будет доступна конкретная версия плагина.
И на выходе вы увидите замечательную картинку вида:
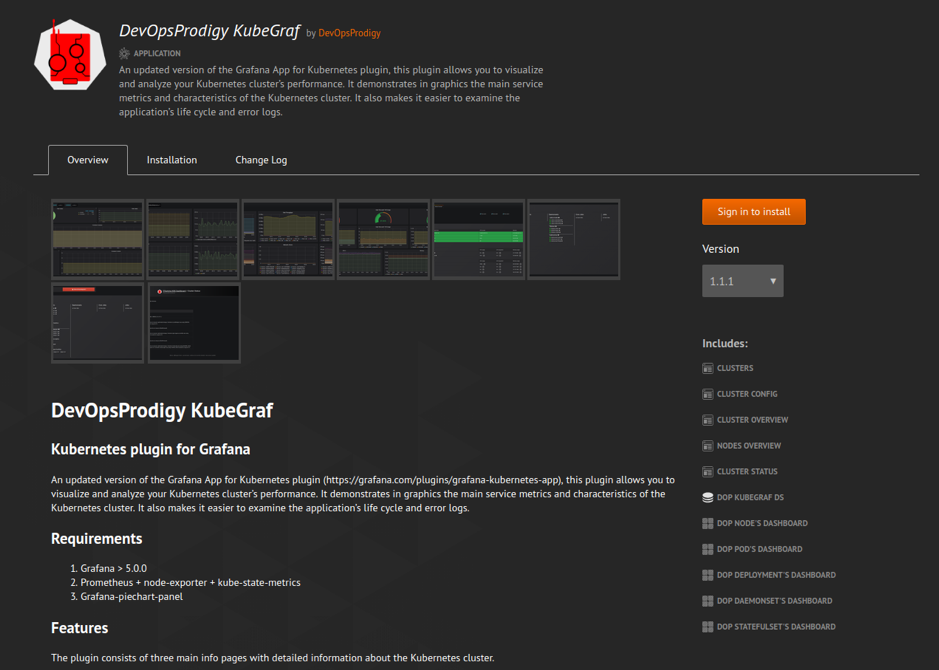
Данные для нее будут автоматически сграблены с вашего Readme.md, Changelog.md и файла plugin.json с описанием плагина.
Часть 6: вместо выводов
Мы не прекратили разработку нашего плагина после релиза. И сейчас работаем над корректным мониторингом использования ресурсов нод кластера, внедрением новых фич для повышения UX, а также разгребаем большое количества фидбека, полученного после установок плагина как нашими клиентами, так и из ишшуев на гитхабе (если вы оставите свое issue или pull request, я буду очень счастлив 🙂 ).
Надеемся что данная статья поможет вам разобраться в таком прекрасном инструменте как Grafana и, возможно, написать свой собственный плагин.
Спасибо!)






