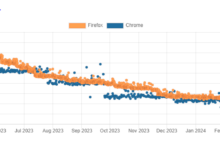
Привет, меня зовут Иван, я делаю Авито Доставку. Тестирую я как-то раз один из наших сервисов на быстродействие. И в метриках pgbouncer’a вижу вот такую печальную картину:

Зелёный — число активных клиентских соединений (cl_active), красные точки — число клиентских соединений, которым не досталось серверного соединения (cl_waiting, правая шкала)
Расследуя этот график, удалось выйти на занятный баг, снять блокер по переезду на четвёртую версию pgx, а также немного разобраться в устройстве pgx и pgbouncer’a.
Чем же так печальна эта картина
На графиках видно, что по мере роста нагрузки растёт число активных соединений и достигает ограничения в 10 штук — тут всё логично. Но дальше с ростом нагрузки cl_active неожиданно падает, а число cl_waiting быстро растёт почти до 60. Как сервис умудрился создать 60 соединений, если размер его пула — 10? Заметим, что сервис при этом заваливается и почти никакой полезной работы не выполняет:

Сверху — входная нагрузка в RPS, посередине — время отклика в миллисекундах по перцентилям, внизу — число успешных и неуспешных ответов
Устройство сервиса

Стрелки показывают, кто о ком «знает»
Сервис на Go развёрнут в k8s, в нескольких небольших подах. PostgreSQL развёрнута в LXC контейнере, рядом с ней живёт pgbouncer.
Всё очень просто: на входе HTTP-запрос, сервис формирует SQL-запрос, шлёт его в базу, затем сериализует результат и отвечает пользователю. Основная работа происходит в базе, она же является узким местом по производительности.
Сервис подключается к pgbouncer с помощью pgx/v4. Пул клиентских соединений ограничен со стороны сервиса (до 10) и со стороны pgbouncer (до 100 по умолчанию). Между pgbouncer и базой тоже свой пул в 10 серверных соединений.
Расследование
Вообще, ситуация выглядит знакомой. Оказывается, другая команда в Авито уже наступала на эти грабли. Довольно быстро находится подходящий инцидент:
LSR-1223: лёг item-storage.
Куча 500-х ошибок.
Из-за уменьшения кэша пошёл трафик в базу, из-за нагрузки база стала медленнее отвечать, из-за медленных ответов сервис стал килить коннекты к базе. Килл происходит через отдельные соединения, и из-за этого все коннекты в баунсере заполнились и новые перестали проходить.
В item-storage обновили pgx на четвёртую версию, где нельзя отключить cancelContext.
Страшная вещь эти архивы. И полезная. У нас, похоже, происходит то же самое: растёт нагрузка, начинаются отмены запросов, создаются соединения на их отмену и забивают пул pgbouncer. Размер пула у нас 100. Максимум мы видели ~60 соединений, но это, скорее всего, неточность метрики, ведь она снимается всего лишь дважды в минуту.
В качестве временного решения предлагается откатиться на третью версию pgx и отключить отмену запросов. Вообще, идея, что нужно отключать отмену запросов при работе через pgbouncer, широко распространена. Обычно это объясняют тем, что есть опасность отменить чужой запрос:
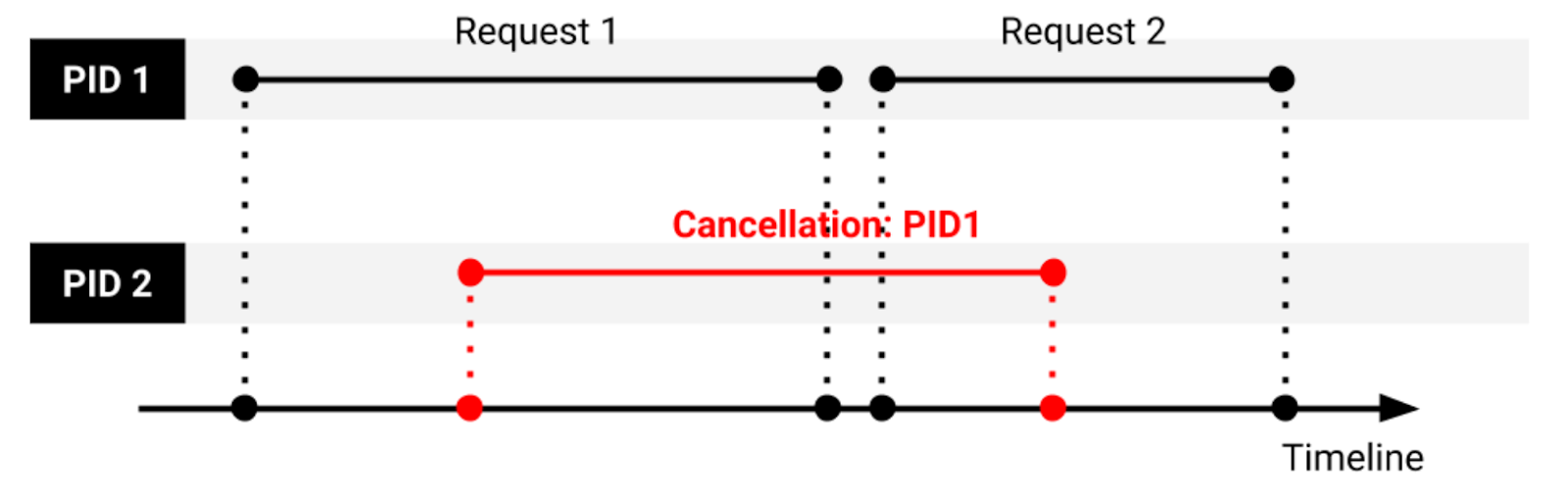
«Postgres выполнит команду и отменит текущий запрос в заданном процессе. Но текущим запросом будет уже не тот, который мы хотели отменить изначально. Из-за такого поведения при работе с Postgres вместе с PgBouncer безопаснее будет не отменять запрос на уровне драйвера. Для этого можно задать функцию CustomCancel, которая не будет отменять запрос, даже если используется context. Context.»
А вот здесь просят @jackc, автора pgx, вернуть в четвёртую версию CustomCancel, который позволяет запретить отмену. Мотивируют, опять же, опасностью отменить не тот запрос:
Джек оказался достаточно дотошным программистом: написал тест, попытался подтвердить наличие проблемы, но это у него не вышло.

Соответственно, вернуть CustomCancel он отказался до появления тест-кейса.
Его отказ создал нашей компании блокер для переезда на pgx/v4 и заставил искать обходные пути. В качестве решений, в частности, предлагалось:
- форкнуть pgx;
- форкнуть pgbouncer;
- написать демон, перезапускающий pgbouncer при переполнении пула.
Понятно, что хорошего решения тут нет. Надо разбираться и искать аргументы для @jackc, чтобы внести правки в апстрим.
Отмена запросов в PostgreSQL и pgbouncer
Как вообще происходит отмена запросов в PostgreSQL?
Каждому соединению PostgreSQL выдаёт уникальный cancel_key. Чтобы отменить запрос, нужно создать новое соединение со специальным стартовым сообщением (CancelRequest вместо StartupMessage) и отправить в него cancel_key от соединения, на котором исполняется запрос. Подробнее — в документации.
Pgbouncer знает о концепции отмены запросов. Создавая соединение к базе, он запоминает выданный Постгресом cancel_key, но не отдаёт его клиенту. Вместо этого для каждого клиентского соединения он сам генерирует уникальный cancel_key:
/* give each client its own cancel key */get_random_bytes(client->cancel_key, 8);
То есть клиент знает cancel_key от соединения к pgbouncer, но не знает cancel_key от соединения к базе, и не может его отменить. Когда клиент пытается отменить запрос, он посылает pgbouncer’у cancel_key от клиентского соединения. Если это соединение в данный момент подключено к серверному, то есть активно, то pgbouncer возьмёт cancel_key от серверного соединения и отменит запрос в нём по стандартной процедуре:
/* remember server key */server = main_client->link;memcpy(req->cancel_key, server->cancel_key, 8); /* attach to target pool */req->pool = pool;change_client_state(req, CL_CANCEL); /* need fresh connection */launch_new_connection(pool);
Если же клиентское соединение неактивно, pgbouncer просто проигнорирует запрос на отмену и закроет клиентское соединение:
/* not linked client, just drop it then */if (!main_client->link)
Похоже, всё-таки отменить чужой запрос при работе через pgbouncer невозможно, что и объясняет, почему @jackc не смог этого добиться в своём тесте.
Остается ещё один вариант отменить не тот запрос, который хотели. Представим ситуацию:
- Посылаем запрос.
- Пытаемся его отменить.
- Пока запрос на отмену добирается до базы, исходный запрос успевает завершиться, и соединение освобождается.
- Посылаем в то же соединение второй запрос.
- В этот момент до базы добирается запрос на отмену, убивая второй запрос.
Отменить запрос в чужом соединении так не получится: мы не знаем cancel_key от него. А своё соединение нам подконтрольно. Мы всегда знаем, какой запрос хотим отменить, и можем не посылать новые запросы в это же соединение (шаг 4). Кстати, pgx/v4 так и делает: при отмене запроса pgx всегда закрывает соединение.
Выходит, отменять запросы в связке pgx/v4 + pgbouncer + PostgreSQL можно. Но проблема остаётся: пул соединений переполняется. Чтобы найти причину, нужно заглянуть в pgx.
Отмена запросов и управление пулом в pgx/v4
Библиотека pgx состоит из модулей, из отдельных библиотек, каждая из которых инкапсулирует свой кусочек функциональности. В частности:
- Pgconn отвечает за низкоуровневое управление соединением. Именно она заведует отменой запросов и знает всё про протокол Постгреса. А вот про пул соединений она не знает ничего.
- Pgxpool отвечает за управление пулом соединений. Делает она это на уровне пула объектов PgConn из библиотеки pgconn. Про отмену запросов она ничего не знает, а если случится таймаут, просто «уничтожает» объект PgConn.
Дело во взаимодействии между этими библиотеками. Когда под нагрузкой запрос не успевает отработать и отменяется по таймауту, происходит вот что:
- Закрывается контекст (context.Context).
- Происходит ошибка соединения.
- Объект PgConn уничтожается и при этом запускает асинхронную отмену запроса.
- Pgxpool видит, что в пуле освободилось место, и создаёт новый PgConn, который, в свою очередь, создаёт новое соединение.
- «Уничтоженный» PgConn тоже создаёт соединение, чтобы отменить запрос. А своё основное соединение он закроет только после отмены. При этом про ограничение на размер пула он не знает и создаёт соединения сверх лимита.
То есть вместо того чтобы закрыть соединение, мы создали два новых: одно на отмену запроса и одно новое, так как место в пуле освободилось.
Под нагрузкой запросы отменяются часто, новые соединения создаются быстро, и очень скоро пул соединений pgbouncer’а оказывается полностью забит. Почти все соединения в нём — это соединения на отмену запросов.
Теперь мы знаем, что проблема именно в pgx, а точнее, во взаимодействии её модулей и в асинхронной обработке отмены контекста. Можно писать тест кейс, но сначала отвлечёмся на одно интересное решение из pgx.
Обработка отмены контекста в pgx
Pgx обрабатывает отмену контекста довольно хитро. Вместо того чтобы везде делать select:
select {case <-ctx.Done()://...}
она создаёт объект, наблюдающий за отменой запроса:
pgConn.contextWatcher = ctxwatch.NewContextWatcher( func() { pgConn.conn.SetDeadline(time.Date(1, 1, 1, 1, 1, 1, 1, time.UTC)) }, func() { pgConn.conn.SetDeadline(time.Time{}) },)
Внутри этот объект создаёт горутину, которая делает обычный select, а при отмене контекста вызывает коллбек и устанавливает давно пропущенный дедлайн прямо на нижележащем соединении net. Conn:
pgConn.conn.SetDeadline(time.Date(1, 1, 1, 1, 1, 1, 1, time.UTC))
Дедлайн, в свою очередь, вызывает ошибки во всех методах, которые работают с этим соединением в данный момент. В итоге pgx перекладывает обработку таймаута на рантайм и упрощает себе обработку ошибок. Например:
n, err := pgConn.conn.Write(buf)if err != nil { pgConn.asyncClose() return &writeError{err: err, safeToRetry: n == 0}}
При закрытии контекста Write() немедленно вернёт ошибку. Решение с select было бы куда более многословным.
Конечно, этот метод имеет свои ограничения: работа должна строиться вокруг соединения и нужно создавать горутину. Но мне кажется, он мог бы быть полезен и применяться чаще.
Тест-кейс для @jackc
Мы выяснили, что проблема проявляется не в неожиданной отмене не тех запросов, а в переполнении пула соединений сверх лимита в условиях, когда многие запросы отменяются.
Тест-кейс на это может быть простым: будем обстреливать базу из нескольких воркеров, посылая запросы, которые всегда отменяются. Замерять будем число соединений на pgbouncer’е. Наша цель — превысить лимит пула сервиса, а ещё лучше, забить пул соединений pgbouncer.
Нам потребуется три докер контейнера: сервис, обстреливающий базу, pgbouncer и Postgres. Урезанный docker-compose.yml (полная версия):
services: web: build: . pgbouncer: image: pgbouncer/pgbouncer postgres: image: postgres
В сервисе всё тоже просто. Создадим 100 воркеров, обстреливающих базу в цикле:
ctx, cancel := context.WithTimeout(ctx, 10 * time.Millisecond)defer cancel() q := `select pg_sleep(10)`rows, _ := db.Query(ctx, q)defer rows.Close()
Запрос выполняется 10 секунд, а контекст закрывается через 10 милллисекунд, то есть запрос всегда отменяется.
Метрики снимаем с помощью команды show pools pgbouncer’а:
echo "show pools;" | psql -h localhost -p 6432 -U postgres pgbouncer
Получаем такой результат:
- cl_active: 2
- cl_waiting: 97
- sv_login: 1
- активных серверных соединений — ни одного
Пул соединений сервиса у нас ограничен до 10, пул pgbouncer — до 100. Видим, что весь пул pgbouncer’а забит, практически никакой полезной работы база не делает.
Всё плохо. То есть хорошо, ведь мы же этого и хотели. Пора идти к Джеку.
Фикс
Джек, увидев наши находки, смог подтвердить проблему и ответил очень быстро. И сразу предложил простое и элегантное решение.
Он ввёл синхронизацию (diff) между pgxpool и pgconn. Теперь pgxpool ждёт, пока pgconn отменит запрос и закроет соединение. И только потом создается новый объект PgConn и новое соединение.
Организовано это с помощью канала PgConn. CleanupDone(). PgConn его закрывает, уведомляя pgxpool о том, что место в пуле действительно освободилось.
Прогон тест-кейса подтвердил, что число соединений остаётся в пределах размера пула сервиса:
- cl_active: 1
- cl_waiting: 8
Обновляем pgx в сервисе до пропатченной версии, нагружаем:

Входная нагрузка в RPS, время отклика в мс, число ответов
Исходная конфигурация сервиса и железа на момент выхода фикса уже была недоступна, и тестировать пришлось на более продвинутой конфигурации, которая работает намного быстрее (об этом в следующей статье). Но главное, что проблема с переполнением пула больше не проявляется:
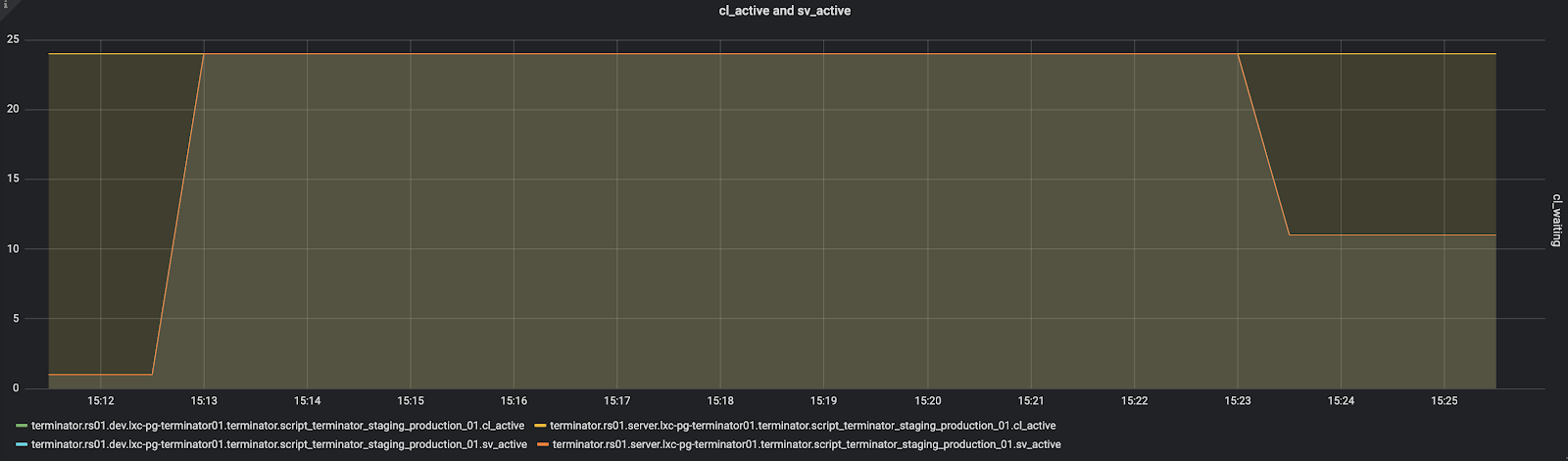
cl_active держится на уровне 24 (это максимальный размер пула сервиса), cl_waiting не появляется
Если подать на сервис нагрузку вдвое больше максимальной, то cl_waiting появляются:
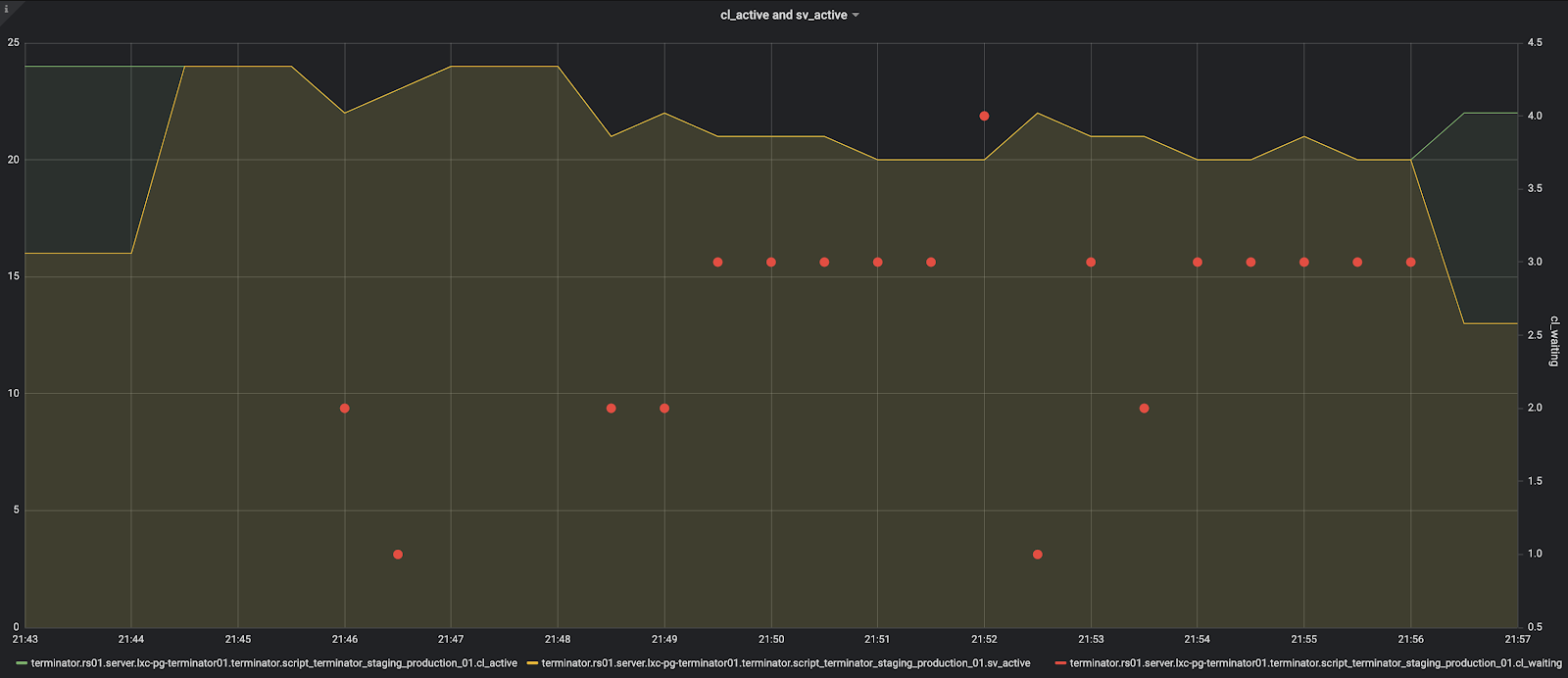
Но их число не превышает 4, а общее число соединений не превышает ограничения на размер пула. Это позволяет сервису удовлетворительно справляться с нагрузкой.
Теперь можно переезжать на 4 версию pgx, обходные решения не понадобятся. Если работаете с pgx под нагрузкой, вас это тоже касается.
TL;DR, или выводы
- Сняли блокер по переезду на pgx/v4 для Авито, да и для всех, кто использует pgx под нагрузкой. До релиза фикса использовать pgx/v4 вместе с pgxpool — опасно.
- Отменять SQL-запросы при работе через pgbouncer — можно.
- Правильно подобранные аргументы могут многое.
Благодарности
Екатерине Семеновой — за LSR’ы и системную работу с инцидентами.
Джеку Кристенсену — за оперативное исправление бага.
Анне Лесных и Дмитрию Назаркову — за помощь в подготовке статьи.