

перев.: Автор статьи — Reuven Harrison — имеет более 20 лет опыта в разработке программного обеспечения, а на сегодняшний день является техническим директором и соучредителем компании Tufin, создающей решения для управления политиками безопасности. Прим. Данный материал (довольно объёмный) призван улучшить осведомлённость специалистов в этом вопросе и помочь им в создании необходимых конфигураций. Рассматривая сетевые политики Kubernetes как достаточно мощное средство для сегментации сети в кластере, он в то же время считает, что они не так просты в применении на практике.
Интерес к этому ПО настолько высок, что некоторые называют Kubernetes «новой операционной системой для центров обработки данных». Сегодня многие компании все чаще выбирают Kubernetes для запуска своих приложений. Постепенно Kubernetes (или k8s) начинает восприниматься как критически важная часть бизнеса, которая требует организации зрелых бизнес-процессов, в том числе обеспечения сетевой безопасности.
Для специалистов по безопасности, которых озадачили работой с Kubernetes, настоящим открытием может стать политика этой платформы по умолчанию: разрешить всё.
Также будет рассказано о некоторых подводных камнях и будут даны рекомендации, которые помогут защитить приложения в Kubernetes. Это руководство поможет разобраться во внутреннем устройстве сетевых политик; понять, чем они отличаются от правил для обычных брандмауэров.
Сетевые политики Kubernetes
Механизм сетевых политик Kubernetes позволяет управлять взаимодействием развернутых на платформе приложений на сетевом уровне (третьем в модели OSI). Сетевые политики лишены некоторых передовых функций современных брандмауэров, таких как контроль на 7 уровне OSI и обнаружение угроз, однако они обеспечивают базовый уровень сетевой безопасности, выступающий неплохой отправной точкой.
Сетевые политики контролируют коммуникации между pod'ами
Рабочие нагрузки в Kubernetes распределяются по pod’ам, которые состоят из одного или нескольких контейнеров, развернутых совместно. Kubernetes присваивает каждому pod’у IP-адрес, доступный из других pod'ов. Сетевые политики Kubernetes задают права доступа для групп pod'ов таким же образом, как группы безопасности в облаке используются для управления доступом к экземплярам виртуальных машин.
Определение сетевых политик
Как и остальные ресурсы Kubernetes, сетевые политики задаются на языке YAML. В приведенном ниже примере приложению balance открывается доступ к postgres:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres namespace: default
spec: podSelector: matchLabels: app: postgres ingress: - from: - podSelector: matchLabels: app: balance policyTypes: - Ingress

перев.: этот скриншот, как и все последующие аналогичные, создан не родными средствами Kubernetes, а с помощью инструмента Tufin Orca, за разработкой которого стоит компания автора оригинальной статьи и который упоминается в конце материала.) (Прим.
Этот язык основан на отступах (задаваемых пробелами, а не табуляцией). Для определения собственной сетевой политики потребуются базовые знания YAML. Новый элемент списка начинается с дефиса, все остальные элементы имеют вид ключ-значение. Элемент с отступом принадлежит ближайшему элементу с отступом над ним.
Описав политику на YAML, используйте kubectl, чтобы создать ее в кластере:
kubectl create -f policy.yaml
Спецификация сетевой политики
Спецификация сетевой политики Kubernetes включает в себя четыре элемента:
podSelector: определяет pod'ы, затрагиваемые этой политикой (цели) — обязательный;policyTypes: указывает, какие типы политик включены в данную: ingress и/или egress — необязательный, однако я рекомендую его явно прописывать во всех случаях;ingress: определяет разрешенный входящий трафик в целевые pod'ы — необязательный;egress: определяет разрешенный исходящий трафик из целевых pod'ов — необязательный.
Пример, позаимствованный с сайта Kubernetes (я заменил role на app), показывает, как используются все четыре элемента:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: test-network-policy namespace: default
spec: podSelector: # <<< matchLabels: app: db policyTypes: # <<< - Ingress - Egress ingress: # <<< - from: - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: # <<< - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978


Обязательным является только podSelector, остальные параметры можно использовать по желанию. Обратите внимание, что все четыре элемента включать необязательно.
Если опустить policyTypes, политика будет интерпретироваться следующим образом:
- По умолчанию предполагается, что она определяет ingress-сторону. Если явных указаний на этот счет в политике не содержится, система будет считать, что весь трафик запрещен.
- Поведение на egress-стороне будет определяться наличием или отсутствием соответствующего egress-параметра.
Чтобы избежать ошибок, я рекомендую всегда явно указывать policyTypes.
«Правило зачистки» ниже). В соответствии с приведенной выше логикой в случае, если параметры ingress и/или egress опущены, политика будет запрещать весь трафик (см.
Политика по умолчанию — разрешить
Если политики не определены, Kubernetes по умолчанию разрешает весь трафик. Все pod'ы свободно могут обмениваться информацией между собой. С точки зрения безопасности это может показаться нелогичным, но вспомните о том, что Kubernetes изначально создавался разработчиками с целью обеспечить взаимодействие приложений. Сетевые политики были добавлены позже.
Пространства имен
Пространства имен (Namespaces) — механизм коллективной работы Kubernetes. Они предназначены для изолирования логических окружений друг от друга, при этом обмен данными между пространствами по умолчанию разрешен.
В блоке metadata можно прописать, какому именно пространству принадлежит политика: Как и большинство компонентов Kubernetes, сетевые политики обитают в определенном пространстве имен.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: test-network-policy namespace: my-namespace # <<<
spec:
...
Если пространство имен в метаданных явно не прописано, система будет использовать namespace, указанное в kubectl (по умолчанию namespace=default):
kubectl apply -n my-namespace -f namespace.yaml
Я рекомендую явно указывать namespace, если только вы не пишете политику, предназначенную сразу для нескольких пространств имен.
Основной элемент podSelector в политике будет выбирать pod’ы из пространства имен, к которому принадлежит политика (он лишен доступа к pod'ам из другого пространства имён).
Аналогичным образом podSelector'ы в блоках ingress и egress могут выбирать pod’ы только из своего пространства имен, если, конечно, вы не объедините их с помощью namespaceSelector (об этом пойдет речь в разделе «Фильтр по пространствам имен и pod'ам»).
Правила именования политик
Названия политик уникальны в рамках одного пространства имен. Двух политик с одинаковым названием в одном пространстве быть не может, но могут быть политики с одинаковыми названиями в разных пространствах. Это удобно, когда вы хотите повторно применить одну и ту же политику на нескольких пространствах.
Он состоит в том, чтобы объединять название пространства имен с целевыми pod’ами. Мне особенно нравится один из способов именования. Например:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres # <<< namespace: default
spec: podSelector: matchLabels: app: postgres ingress: - from: - podSelector: matchLabels: app: admin policyTypes: - Ingress

Лейблы
К объектам Kubernetes, таким как pod’ы и пространства имен, можно прикреплять пользовательские лейблы. Лейблы (labels — метки) являются эквивалентом тегов в облаке. Сетевые политики Kubernetes используют лейблы для выбора pod'ов, к которым они применяются:
podSelector: matchLabels: role: db
… или пространств имен, к которым они применяются. В этом примере выбираются все pod'ы в пространствах имен с соответствующими лейблами:
namespaceSelector: matchLabels: project: myproject
Одно предостережение: при использовании namespaceSelector убедитесь, что выбираемые пространства имен содержат в себе нужный лейбл. Имейте в виду, что встроенные пространства имен, такие как default и kube-system, по умолчанию не содержат в себе лейблов.
Добавить лейбл к пространству можно следующим образом:
kubectl label namespace default namespace=default
При этом namespace в разделе metadata должен ссылаться на фактическое имя пространства, а не на лейбл:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: test-network-policy namespace: default # <<<
spec:
...
Источник и адресат
Политики для брандмауэров состоят из правил с источниками и адресатами. Сетевые политики Kubernetes определяются для цели — набора из pod'ов, к которым они применяются, а затем устанавливают правила для входящего (ingress) и/или исходящего (egress) трафика. В нашем примере целью политики будут все pod’ы в пространстве имен default с лейблом с ключом app и значением db:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: test-network-policy namespace: default
spec: podSelector: matchLabels: app: db # <<< policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978
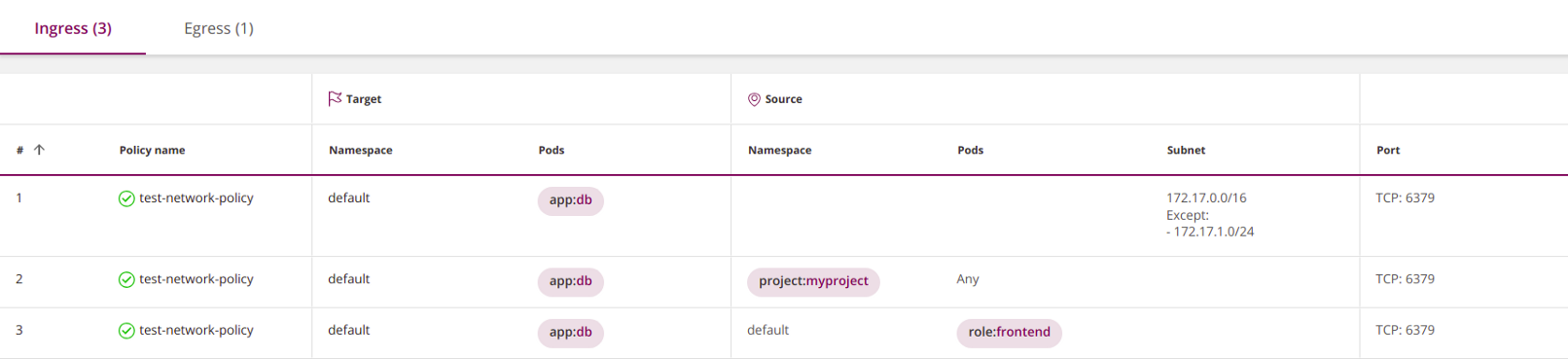

Другими словами, ingress выступает источником, а цель — соответствующим адресатом. Подраздел ingress в этой политике открывает входящий трафик к целевым pod’ам. Аналогичным образом egress является адресатом, а цель — его источником.
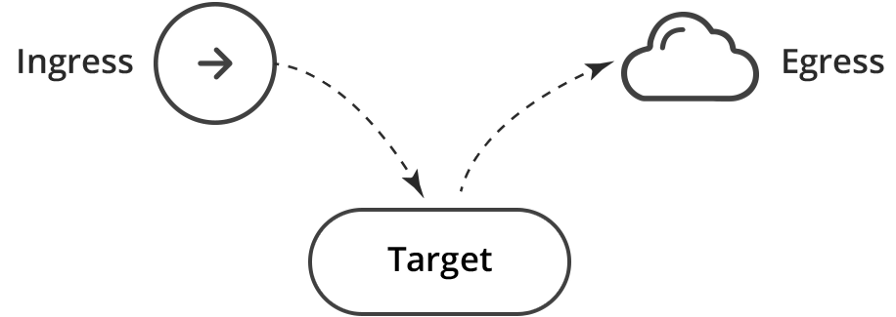
Это эквивалентно двум правилам для брандмауэра: Ingress → Цель; Цель → Egress.
Egress и DNS (важно!)
Ограничивая исходящий трафик, особое внимание обратите на DNS — Kubernetes использует эту службу для сопоставления сервисов с IP-адресами. Например, следующая политика не сработает, поскольку вы не разрешили приложению balance обращаться к DNS:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.balance namespace: default
spec: podSelector: matchLabels: app: balance egress: - to: - podSelector: matchLabels: app: postgres policyTypes: - Egress

Исправить ее можно, открыв доступ к сервису DNS:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.balance namespace: default
spec: podSelector: matchLabels: app: balance egress: - to: - podSelector: matchLabels: app: postgres - to: # <<< ports: # <<< - protocol: UDP # <<< port: 53 # <<< policyTypes: - Egress

Последний элемент to — пустой, и поэтому он косвенно выбирает все pod'ы во всех пространствах имен, позволяя balance посылать DNS-запросы в соответствующую службу Kubernetes (обычно она работает в пространстве kube-system).
Этот подход работает, однако он чрезмерно разрешающий и небезопасный, поскольку позволяет направлять DNS-запросы за пределы кластера.
Улучшить его можно тремя последовательными шагами.
Разрешить DNS-запросы только внутри кластера, добавив namespaceSelector: 1.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.balance namespace: default
spec: podSelector: matchLabels: app: balance egress: - to: - podSelector: matchLabels: app: postgres - to: - namespaceSelector: # <<< ports: - protocol: UDP port: 53 policyTypes: - Egress

Разрешить DNS-запросы только в пространстве имен kube-system. 2.
Для этого нужно добавить лейбл в пространство имен kube-system: kubectl label namespace kube-system namespace=kube-system — и прописать ее в политике с помощью namespaceSelector:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.balance namespace: default
spec: podSelector: matchLabels: app: balance egress: - to: - podSelector: matchLabels: app: postgres - to: - namespaceSelector: # <<< matchLabels: # <<< namespace: kube-system # <<< ports: - protocol: UDP port: 53 policyTypes: - Egress

Параноики могут пойти еще дальше и ограничить DNS-запросы определенной DNS-службой в kube-system. 3. В разделе «Фильтр по пространствам имен И pod'ам» будет рассказано, как этого добиться.
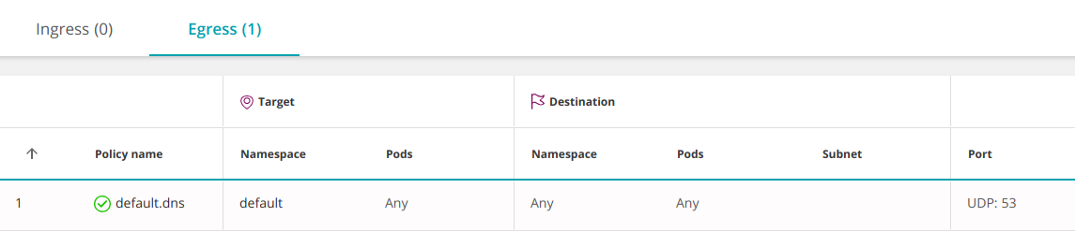
В этом случае его не нужно будет открывать для каждой службы: Другой вариант — разрешить DNS на уровне пространства имен.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.dns namespace: default
spec: podSelector: {} # <<< egress: - to: - namespaceSelector: {} ports: - protocol: UDP port: 53 policyTypes: - Egress
Пустой podSelector выбирает все pod’ы в пространстве имен.
Первое соответствие и порядок правил
В обычных брандмауэрах действие («Разрешить» или «Запретить») в отношении пакета определяется первым правилом, которому он удовлетворяет. В Kubernetes порядок политик не имеет никакого значения.
Как только вы начинаете формулировать политики, каждый pod, затронутый хотя бы одной из них, становится изолированным в соответствии с дизъюнкцией (логическим ИЛИ) всех политик, которые его выбрали. По умолчанию, когда политики не заданы, коммуникации между pod'ами разрешены и они могут свободно обмениваться информацией. Pod’ы, не затронутые какой-либо политикой, остаются открытыми.
Изменить подобное поведение можно с помощью правила зачистки.
Правило зачистки («Запретить»)
Политики брандмауэров обычно запрещают любой явным образом не разрешенный трафик.
В Kubernetes нет действия «запретить» (deny), однако аналогичного эффекта можно добиться с обычной (разрешающей) политикой, выбрав пустую группу pod'ов-источников (ingress):
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: deny-all namespace: default
spec: podSelector: {} policyTypes: - Ingress
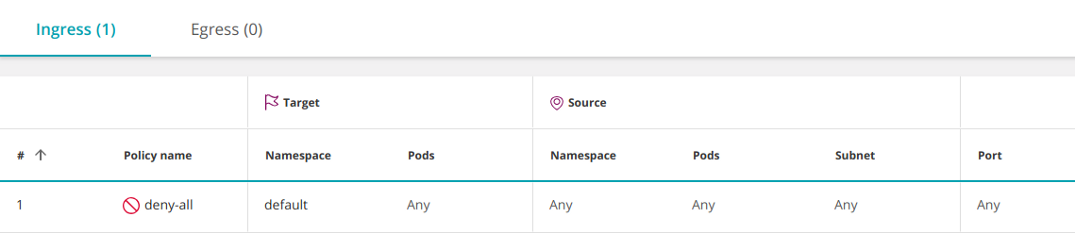
Эта политика выбирает все pod'ы в пространстве имен и оставляет ingress неопределенным, запрещая весь входящий трафик.
Похожим образом можно ограничить весь исходящий трафик из пространства имен:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: deny-all-egress namespace: default
spec: podSelector: {} policyTypes: - Egress
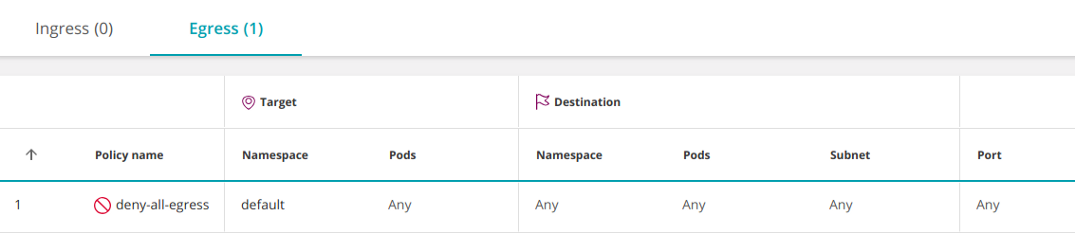
Учтите, что любые дополнительные политики, разрешающие трафик к pod'ам в пространстве имен, будут иметь приоритет над этим правилом (аналогично добавлению разрешающего правила перед запрещающим в конфигурации брандмауэра).
Разрешить все (Any-Any-Any-Allow)
Чтобы создать политику «Разрешить все», необходимо дополнить приведенную выше запретительную политику пустым элементом ingress:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: allow-all namespace: default
spec: podSelector: {} ingress: # <<< - {} # <<< policyTypes: - Ingress
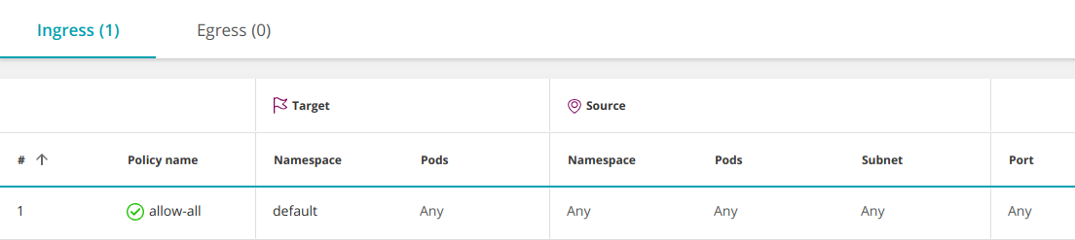
Подобное поведение включено по умолчанию, поэтому обычно его не нужно определять дополнительно. Она открывает доступ со всех pod'ов во всех пространствах имен (и всех IP) к любому pod’у в пространстве имен default. Однако иногда может потребоваться временно отключить некоторые конкретные разрешения для диагностики проблемы.
Правило можно сузить и разрешить доступ только к определенному набору pod'ов (app:balance) в пространстве имен default:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: allow-all-to-balance namespace: default
spec: podSelector: matchLabels: app: balance ingress: - {} policyTypes: - Ingress
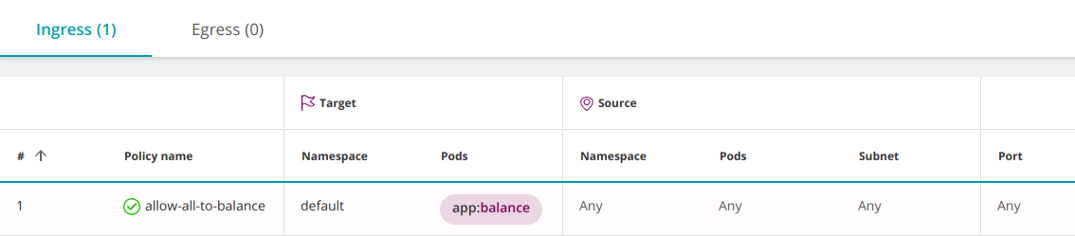
Следующая политика разрешает весь входящий (ingress) И исходящий (egress) трафик, включая доступ к любому IP за пределами кластера:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: allow-all
spec: podSelector: {} ingress: - {} egress: - {} policyTypes: - Ingress - Egress
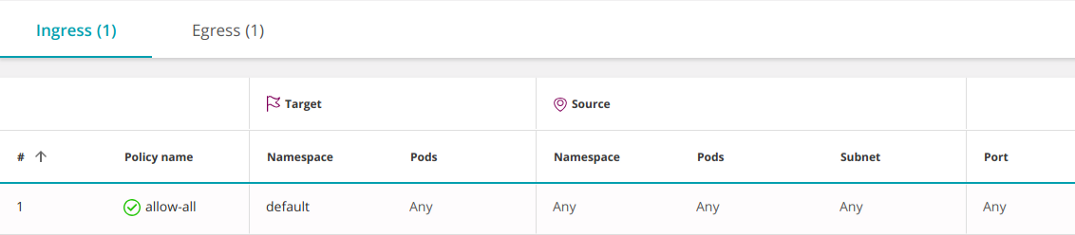
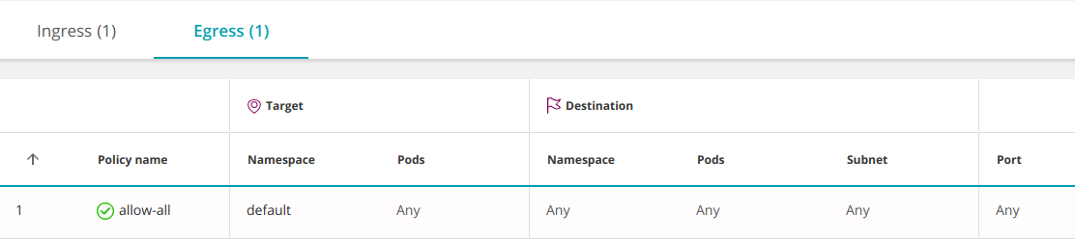
Объединение нескольких политик
Политики объединяются с помощью логического ИЛИ на трех уровнях; разрешения каждого pod'а устанавливаются в соответствии с дизъюнкцией всех политик, которые его затрагивают:
В полях from и to можно определить три типа элементов (все они комбинируются с помощью ИЛИ): 1.
namespaceSelector— выбирает пространство имен целиком;podSelector— выбирает pod’ы;ipBlock— выбирает подсеть.
При этом количество элементов (даже одинаковых) в подразделах from/to не ограничено. Все они будут объединены логическим ИЛИ.
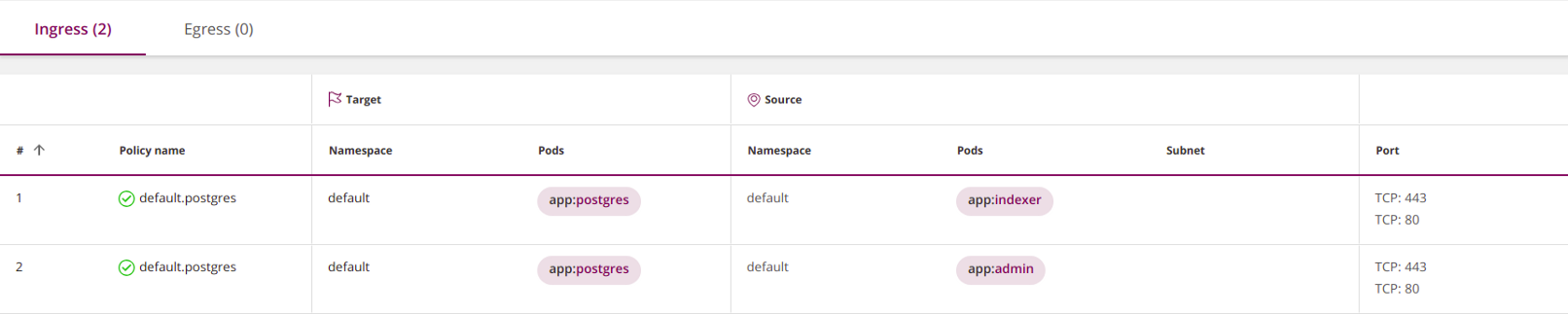
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres namespace: default
spec: ingress: - from: - podSelector: matchLabels: app: indexer - podSelector: matchLabels: app: admin podSelector: matchLabels: app: postgres policyTypes: - Ingress

Внутри политики раздел ingress может иметь множество элементов from (объединяются логическим ИЛИ). 2. Аналогичным образом раздел egress может включать множество элементов to (также объединяются дизъюнкцией):
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres namespace: default
spec: ingress: - from: - podSelector: matchLabels: app: indexer - from: - podSelector: matchLabels: app: admin podSelector: matchLabels: app: postgres policyTypes: - Ingress

Различные политики также объединяются логическим ИЛИ 3.
Политики, определяющие ingress (или egress), перезапишут друг друга. Но при их объединении существует одно ограничение, на которое указал Chris Cooney: Kubernetes может комбинировать политики только с различными policyTypes (Ingress или Egress).
Связь между пространствами имен
По умолчанию обмен информацией между пространствами имен разрешен. Изменить это можно с помощью запретительной политики, которая ограничит исходящий и/или входящий трафик в пространство имен (см. «Правило зачистки» выше).
«Правило зачистки» выше), вы можете внести исключения в запретительную политику, разрешив подключения с определенного пространства имен с помощью namespaceSelector: Заблокировав доступ в пространство имен (см.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: database.postgres namespace: database
spec: podSelector: matchLabels: app: postgres ingress: - from: - namespaceSelector: # <<< matchLabels: namespace: default policyTypes: - Ingress
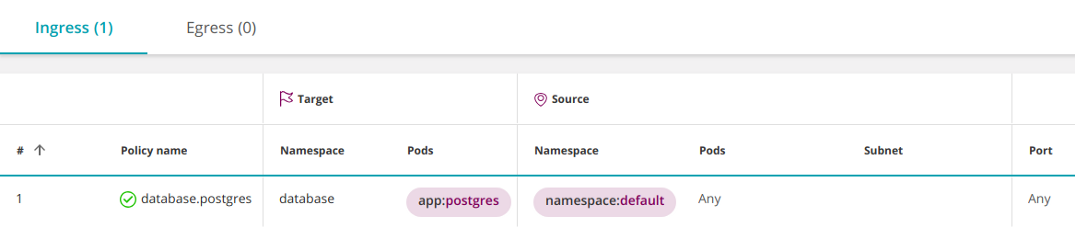
Но что, если вы хотите открыть доступ к postgres только конкретным pod'ам в пространстве имен default? В результате все pod’ы в пространстве имен default получат доступ к pod'ам postgres в пространстве имен database.
Фильтр по пространствам имен И pod'ам
Kubernetes версии 1.11 и выше позволяет комбинировать операторы namespaceSelector и podSelector с помощью логического И. Выглядит это следующим образом:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: database.postgres namespace: database
spec: podSelector: matchLabels: app: postgres ingress: - from: - namespaceSelector: matchLabels: namespace: default podSelector: # <<< matchLabels: app: admin policyTypes: - Ingress
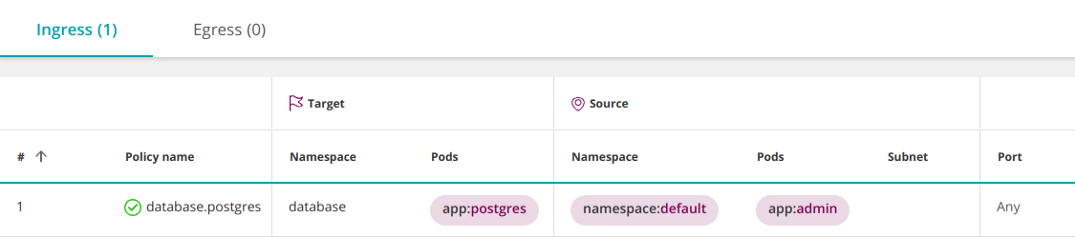
Почему это трактуется как И вместо привычного ИЛИ?
В YAML это означает, что podSelector и стоящий перед ним namespaceSelector относятся к одному и тому же элементу списка. Обратите внимание, что podSelector не начинается с дефиса. Поэтому они объединяются логическим И.
Добавление дефиса перед podSelector приведет к возникновению нового элемента списка, который будет комбинироваться с предшествующим namespaceSelector с помощью логического ИЛИ.
Чтобы выбрать pod'ы с определенным лейблом во всех пространствах имен, впишите пустой namespaceSelector:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: database.postgres namespace: database
spec: podSelector: matchLabels: app: postgres ingress: - from: - namespaceSelector: {} podSelector: matchLabels: app: admin policyTypes: - Ingress

Множественные лейблы объединяются с И
Правила для брандмауэра со множеством объектов (хостами, сетями, группами) комбинируются с помощью логического ИЛИ. Следующее правило сработает, если источник пакета совпадает с Host_1 ИЛИ Host_2:
| Source | Destination | Service | Action |
| ----------------------------------------|
| Host_1 | Subnet_A | HTTPS | Allow |
| Host_2 | | | |
| ----------------------------------------|
Наоборот, в Kubernetes различные лейблы в podSelector или namespaceSelector объединяются логическим И. Например, следующее правило выберет pod’ы, обладающие обеими лейблами, role=db И version=v2:
podSelector: matchLabels: role: db version: v2
Та же логика применяется ко всем типам операторов: селекторам целей политики, селекторам pod'ов и селекторам пространств имен.
Подсети и IP-адреса (IPBlocks)
Для сегментирования сети брандмауэры используют VLAN, IP-адреса и подсети.
В Kubernetes IP-адреса присваиваются pod'ам автоматически и могут часто меняться, поэтому для выбора pod'ов и пространств имен в сетевых политиках используются лейблы.
К примеру, эта политика открывает всем pod'ам из пространства имен default доступ к DNS-сервису Google: Подсети (ipBlocks) используются при управлении входящими (ingress) или исходящими (egress) внешними (North-South) подключениями.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: egress-dns namespace: default
spec: podSelector: {} policyTypes: - Egress egress: - to: - ipBlock: cidr: 8.8.8.8/32 ports: - protocol: UDP port: 53

Пустой селектор pod'ов в этом примере означает «выбрать все pod’ы в пространстве имен».
8. Данная политика открывает доступ только к 8. 8; доступ к любому другому IP запрещен. 8. Если вы все же хотите его открыть, укажите это явно. Таким образом, по сути, вы заблокировали доступ к внутренней службе DNS Kubernetes.
Указав внутренние IP pod'ов, вы фактически разрешите подключения к/от pod'ов с этими адресами. Обычно ipBlocks и podSelectors являются взаимоисключающими, поскольку внутренние IP-адреса pod'ов не используются в ipBlocks. На практике вы не будете знать, какой IP-адрес использовать, именно поэтому их не стоит применять для выбора pod'ов.
В качестве контр-примера следующая политика включает все IP и, следовательно, разрешает доступ ко всем другим pod'ам:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: egress-any namespace: default
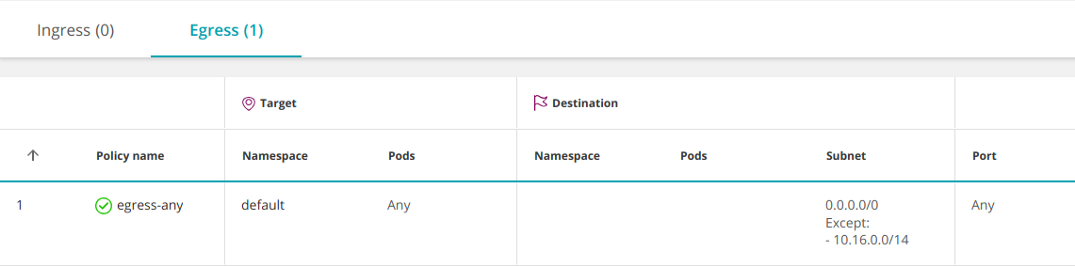
spec: podSelector: {} policyTypes: - Egress egress: - to: - ipBlock: cidr: 0.0.0.0/0
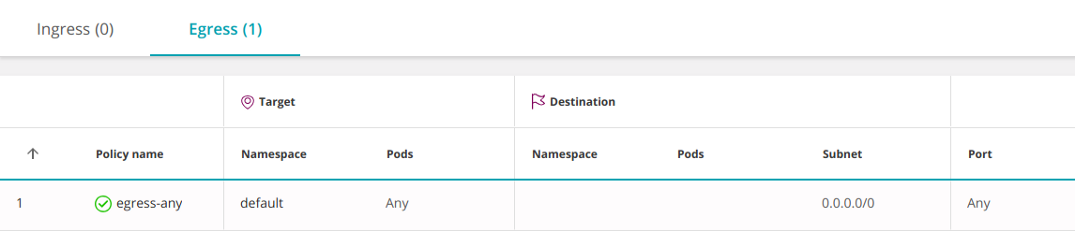
Например, если подсеть вашего pod'а 10. Можно открыть доступ только к внешним IP, исключив внутренние IP-адреса pod'ов. 0. 16. 0/14:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: egress-any namespace: default
spec: podSelector: {} policyTypes: - Egress egress: - to: - ipBlock: cidr: 0.0.0.0/0 except: - 10.16.0.0/14
Порты и протоколы
Обычно pod'ы слушают один порт. Это означает, что можно просто не указывать номера портов в политиках и оставить все по умолчанию. Впрочем, политики рекомендуется делать максимально ограничительными, поэтому в некоторых случаях все же можно указывать порты:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres namespace: default
spec: ingress: - from: - podSelector: matchLabels: app: indexer - podSelector: matchLabels: app: admin ports: # <<< - port: 443 # <<< protocol: TCP # <<< - port: 80 # <<< protocol: TCP # <<< podSelector: matchLabels: app: postgres policyTypes: - Ingress
Чтобы указать разные порты для различных наборов элементов, разбейте ingress или egress на несколько подразделов с to или from и в каждом пропишите свои порты: Заметьте, что селектор ports применяется ко всем элементам в блоке to или from, в котором содержится.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata: name: default.postgres namespace: default
spec: ingress: - from: - podSelector: matchLabels: app: indexer ports: # <<< - port: 443 # <<< protocol: TCP # <<< - from: - podSelector: matchLabels: app: admin ports: # <<< - port: 80 # <<< protocol: TCP # <<< podSelector: matchLabels: app: postgres policyTypes: - Ingress

Работа портов по умолчанию:
- Если вы полностью опускаете определение портов (
ports), это означает все протоколы и все порты; - Если вы опускаете определение протокола (
protocol), это означает TCP; - Если вы опускаете определение порта (
port), это означает все порты.
Лучшая практика: не полагайтесь на значения по умолчанию, указывайте нужное вам явно.
Обратите внимание, что необходимо использовать порты pod'ов, а не сервисов (подробнее об этом в следующем параграфе).
Политики определены для pod'ов или сервисов?
Обычно pod’ы в Kubernetes обращаются друг к другу через сервис — виртуальный балансировщик нагрузки, перенаправляющий трафик к pod'ам, реализующим сервис. Можно подумать, что сетевые политики контролируют доступ к сервисам, но это не так. Сетевые политики Kubernetes работают с портами pod'ов, а не сервисов.
Например, если сервис слушает 80-й порт, но перенаправляет трафик на порт 8080 своих pod'ов, в сетевой политике необходимо указать именно 8080.
Подобный механизм следует признать неоптимальным: при изменении внутреннего устройства сервиса (порты которого слушают pod'ы) придется обновлять сетевые политики.
про Istio ниже — прим. Новый архитектурный подход с использованием Service Mesh (например, см. перев.) позволяет справиться с этой проблемой.
Необходимо ли прописывать как Ingress, так и Egress?
Короткий ответ — да, чтобы pod А мог связаться с pod’ом В, необходимо разрешить ему создавать исходящее соединение (для этого следует настроить egress-политику), а pod В должен иметь возможность принимать входящее соединение (для этого, соответственно, нужна ingress-политика).
Однако на практике можно положиться на политику по умолчанию, разрешающую соединения в одном или обоих направлениях.
В этом случае потребуется явно разрешить подключение к pod’у-адресату. Если некий pod-источник будет выбран одной или несколькими egress-политиками, накладываемые на него ограничения будут определяться их дизъюнкцией. Если pod не выбран какой-либо политикой, его исходящий (egress) трафик разрешен по умолчанию.
В этом случае необходимо явно разрешить ему получать трафик от pod'а-источника. Аналогичным образом судьба pod'а-адресата, выбранного одной или несколькими ingress-политиками, будет определяться их дизъюнкцией. Если pod не выбран какой-либо политикой, весь входящий (ingress) трафик для него разрешен по умолчанию.
пункт «Stateful или Stateless» ниже. См.
Логи
Сетевые политики Kubernetes не умеют журналировать трафик. Это затрудняет определение того, работает ли политика должным образом, и сильно осложняет анализ в области безопасности.
Контроль за трафиком к внешним сервисам
Сетевые политики Kubernetes не позволяют указывать полноценное доменное имя (DNS) в разделах egress. Этот факт приводит к значительному неудобству при попытке ограничить трафик к внешним адресатам, лишенным фиксированного IP-адреса (таким как aws.com).
Проверка политики
Брандмауэры предупредят вас или даже откажутся принять ошибочную политику. Kubernetes тоже проводит некоторую верификацию. При задании сетевой политики через kubectl Kubernetes может заявить, что она неверна, и отказаться ее принять. В других случаях Kubernetes примет политику и дополнит ее недостающими деталями. Их можно увидеть с помощью команды:
kubernetes get networkpolicy <policy-name> -o yaml
Имейте в виду, что система проверки Kubernetes не непогрешима и может пропускать некоторые типы ошибок.
Исполнение
Kubernetes не занимается реализацией сетевых политик самостоятельно, а является лишь API-шлюзом, возлагающим обременительную работу по контролю на нижележащую систему, называемую Container Networking Interface (CNI). Задание политик в кластере Kubernetes без назначения соответствующего CNI аналогично созданию политик на сервере управления брандмауэром без их последующей установки в брандмауэры. Вы сами должны убедиться в наличии достойного CNI или, в случае платформ Kubernetes, размещенных в облаке (со списком провайдеров можно ознакомиться здесь — прим. пер.), задействовать сетевые политики, которые установят CNI для вас.
Обратите внимание, что Kubernetes не предупредит вас, если вы зададите сетевую политику без соответствующего вспомогательного CNI.
Stateful или Stateless?
Все CNI Kubernetes, с которыми мне доводилось сталкиваться, хранят состояния (например, Calico использует Linux conntrack). Это позволяет pod’у получать ответы по инициированному им TCP-соединению без необходимости устанавливать его заново. При этом мне неизвестно о стандарте Kubernetes, который гарантировал бы хранение состояния (statefulness).
Продвинутое управление политикой безопасности
Вот несколько способов повысить эффективность исполнения политики безопасности в Kubernetes:
- Архитектурный паттерн Service Mesh использует sidecar-контейнеры для обеспечения подробной телеметрии и контроля за трафиком на уровне сервисов. В качестве примера можно взять Istio.
- Некоторые из поставщиков CNI дополнили свои инструменты, чтобы те вышли за рамки сетевых политик Kubernetes.
- Tufin Orca обеспечивает прозрачность и автоматизацию сетевых политик Kubernetes.
Пакет Tufin Orca управляет сетевыми политиками Kubernetes (и служит источником скриншотов, приведенных выше).
Дополнительная информация
Заключение
Сетевые политики Kubernetes предлагают неплохой набор инструментов для сегментации кластеров, однако они интуитивно непонятны и имеют множество тонкостей. Я считаю, что из-за этой сложности политики многих существующих кластеров содержат ошибки. Возможными решениями этой проблемы являются автоматизация определений политик или применение других средств сегментации.
Надеюсь, что это руководство поможет прояснить некоторые вопросы и решить проблемы, с которыми вы можете столкнуться.
P.S. от переводчика
Читайте также в нашем блоге:



![Фото [Перевод] Реверс-инжиниринг сигнала автомобильного брелка](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-revers-inzhiniring-signala-avtomobilnogo-brelka-390x220.png.pagespeed.ic.yjZrApk_zL.jpg)
![Фото [Перевод] Реверс-инжиниринг сигнала автомобильного брелка](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-revers-inzhiniring-signala-avtomobilnogo-brelka-220x150.png.pagespeed.ic.bXlORcGXMk.jpg)

