

Но перед ней небольшое вступление. Это статья-перевод Стэнфордского семинара. Каждый попадал в ситуацию, когда хочется подтянуть друга или коллегу до своего уровня, а не получается. Как образуются зомби? Думать неприятно и больно. Причём «не получается» не столько у тебя, сколько у него: на одной чаше весов находится нормальная зарплата, задачи и так далее, а на другой — необходимость думать. Ты представляешь, насколько много сил нужно потратить, чтобы преодолеть барьер выученной беспомощности, и просто не делаешь этого. Он быстро сдаётся и продолжает писать код, совершенно не включая мозг. Так образуются зомби, которых вроде бы можно вылечить, но вроде бы и никто этим заниматься не станет.
На всякий случай, Лесли — всемирно известный учёный, автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Когда я увидел, что Лесли Лэмпорт (да-да, тот самый товарищ из учебников) приезжает в Россию и делает не доклад, а сессию вопросов-ответов, я немного насторожился. Решил посмотреть, что там Лэмпорт вещает — и это великолепно! Вторым настораживающим фактором является его требование: каждый, кто придёт, должен (совершенно бесплатно) заранее прослушать пару его докладов, придумать по ним минимум один вопрос и только тогда уже приходить. Предупреждаю: от текста может знатно подгореть у любителей сверхгибких методологий и нелюбителей тестировать написанное. Это в точности та штука, волшебная ссылка-таблетка для лечения зомбятины.
Приятного чтения! После хаброката, собственно, начинается перевод семинара.
За какое бы задание вы ни взялись, вам всегда нужно пройти три шага:
- определиться, какой цели вы хотите достичь;
- решить, как именно вы будете добиваться своей цели;
- прийти к своей цели.
Когда мы пишем код, нам необходимо: Это касается и программирования.
- решить, что именно должна делать программа;
- определить, как именно она должна выполнять свою задачу;
- написать соответствующий код.
Вместо этого мы обсудим первые два. Последний шаг, конечно, очень важен, но о нем я говорить сегодня не буду. Вы не садитесь писать, если не решили, что именно пишете: браузер или базу данных. Их выполняет каждый программист прежде, чем начать работать. И вы обязательно продумываете, что именно программа будет делать, а не пишете кое-как в надежде, что код сам как-нибудь превратится в браузер. Определенное представление о цели обязательно должно присутствовать.
Сколько усилий нам следует на это тратить? Как именно происходит это предварительное продумывание кода? Предположим, мы хотим написать отказоустойчивую распределенную систему. Все зависит от того, насколько сложную проблему мы решаем. А если нам просто нужно увеличить целочисленную переменную на 1? В этом случае нам следует обдумать все как следует, прежде чем садиться за код. Поэтому, даже для того, чтобы понять, простая проблема или сложная — вначале нужно подумать. На первый взгляд, здесь все тривиально, и никаких размышлений не нужно, но потом мы вспоминаем, что может произойти переполнение.
Но для этого нужно, чтобы ваше мышление было ясным. Если предварительно продумать возможные решения проблемы, можно избежать ошибок. Мне очень нравится цитата Дика Гиндона: «Когда вы пишете, природа демонстрирует вам, насколько неряшливо ваше мышление». Чтобы этого добиться, нужно записывать свои мысли. А записывать свои мысли нужно в форме спецификаций. Если вы не пишете, вам только кажется, что вы мыслите.
Но я буду говорить только об одной из них: они помогают нам ясно мыслить. Спецификации выполняют множество функций, в особенности в крупных проектах. На каком языке нам следует писать спецификации? Ясно мыслить очень важно и довольно трудно, поэтому здесь нам нужно любое подспорье. Одного правильного ответа на него нет: проблемы, которые мы решаем, слишком многообразные. Это вообще всегда первый вопрос для программистов: на каком языке мы будем писать. Для других удобнее пользоваться китайским. Для некоторых полезен TLA+ — это язык спецификаций, который я разработал. Все зависит от ситуации.
Ответ: мы должны мыслить как ученые. Более важен другой вопрос: как добиться более ясного мышления? В науке мы строим математические модели реальности. Это способ мышления, который отлично зарекомендовал себя за последние 500 лет. В математической модели, используемой в астрономии, небесные тела предстают как точки с массой, положением и импульсом, хотя в реальности они являются крайне сложными объектами с горами и океанами, приливами и отливами. Астрономия была, пожалуй, первой наукой в строгом смысле этого слова. Она отлично подходит для того, чтобы определить, куда нужно направить телескоп, если нужно найти планету. Эта модель, как и любая другая, создана для решения определенных задач. Но если вы хотите предсказать погоду на этой планете, эта модель не подойдет.
А наука показывает, как эти свойства соотносятся с реальностью. Математика позволяет нам определить свойства модели. Реальность, с которой мы работаем — это вычислительные системы самых разных видов: процессоры, игровые консоли, компьютеры, выполняющие программы и так далее. Поговорим о нашей науке, computer science. В нашей науке мы используем множество различных моделей: машина Тьюринга, частично упорядоченные множества событий и многие другие. Я буду говорить о выполнении программы на компьютере, но, по большому счету, все эти выводы применимы к любой вычислительной системе.
Это любой код, который можно рассматривать самостоятельно. Что такое программа? Мы выполняем три задачи: проектируем представление программы для пользователя, затем пишем высокоуровневую схему программы, и, наконец, пишем код. Предположим, нам нужно написать браузер. Здесь нам опять нужно решить три задачи: определить, какой текст это средство будет возвращать; выбрать алгоритм для форматирования; написать код. По ходу написания кода мы понимаем, что нам нужно написать средство для форматирования текста. Эту подзадачу мы тоже решаем в три шага — как видим, они повторяются на многих уровнях. У этой задачи своя подзадача: правильно вставлять дефис в слова.
Здесь мы чаще всего моделируем программу как функцию, которая получает некоторые входные данные и дает некоторые данные на выходе. Рассмотрим более подробно первый шаг: какую задачу решает программа. Например, функция возведения в квадрат для натуральных чисел описывается как множество . В математике функция обычно описывается как упорядоченное множество пар. Чтобы определить функцию, нам нужно указать ее область определения и формулу. Область определения такой функции — множество первых элементов каждой пары, то есть натуральные числа.
Математика значительно проще. Но функции в математике — это не то же, что функции в языках программирования. В спецификации этого метода мы напишем: вычисляет GCD(M,N) для аргументов M и N, где GCD(M,N) — функция, область определения которой — множество пар целых чисел, а возвращаемое значение — наибольшее целое число, на которое делится M и N. Поскольку на сложные примеры у меня времени нет, рассмотрим простой: функция в языке С или статический метод в Java, возвращающий наибольший общий делитель двух целых чисел. Модель оперирует с целыми числами, а в C или Java мы имеем 32-битный int. Как с этой моделью соотносится реальность? Для этого потребовалась бы более сложная модель, на которую нет времени. Эта модель позволяет нам решить, правилен ли алгоритм GCD, но она не предотвратит ошибки переполнения.
Работа некоторых программ (например, операционных систем) не сводится к тому, чтобы вернуть определенное значение для определенных аргументов, они могут выполняться непрерывно. Поговорим об ограничениях функции как модели. Быстрая сортировка и сортировка пузырьком вычисляют одну и ту же функцию, но это совершенно разные алгоритмы. Кроме того, функция как модель плохо подходит для второго шага: планирования способа решения задачи. Программа в ней представлена как множество всех допустимых поведений, каждое из которых, в свою очередь, является последовательностью состояний, а состояние — это присвоение значений переменным. Поэтому для описания способа достижения цели программы я использую другую модель, назовем ее стандартная поведенческая модель.
Нам нужно вычислить GCD(M, N). Давайте посмотрим, как будет выглядеть второй шаг для алгоритма Евклида. Например, если M = 12, а N = 18, мы можем описать следующее поведение: Мы инициализируем M как x, а N как y, затем повторно отнимаем меньшую из этих переменных от большей до тех пор, пока они не будут равны.
[x = 12, y = 18] → [x = 12, y = 6] → [x = 6, y = 6]
Ноль делится на все числа, поэтому наибольшего делителя в этом случае нет. А если M = 0 и N = 0? Если в этом нет необходимости, то нужно просто изменить спецификацию. В этой ситуации нам нужно вернуться к первому шагу и спросить: действительно ли нам нужно вычислять НОД для неположительных чисел?
Её часто измеряют в количестве строк кода, написанных за день. Здесь следует сделать небольшое отступление о продуктивности. И избавляться от кода проще всего именно на первом шаге. Но ваш труд значительно полезнее, если вы избавились от определенного количества строк, потому что у вас стало меньше места для багов. Самый быстрый способ упростить программу и сэкономить время — не делать вещи, которые не стоит делать. Вполне возможно, что вам просто не нужны все те навороты, которые вы пытаетесь реализовать. Если вы измеряете продуктивность в количестве написанных строк, то продумывание способа выполнения задачи сделает вас менее продуктивными, поскольку вы сможете решить ту же задачу меньшим объемом кода. Второй шаг — на втором месте по потенциалу для экономии времени. И эксперимент тут тоже не поставить, потому что в эксперименте мы не имеем права выполнить первый шаг, задание определено заранее. Точную статистику я здесь привести не могу, поскольку у меня нет способа посчитать то количество строк, которые я не написал благодаря тому, что потратил время на спецификацию, то есть на первый и второй шаги.
Ничего сложного в написании строгих спецификаций для функций нет, обсуждать это я не буду. В неформальных спецификациях легко не учесть многие трудности. Есть теорема, которая гласит, что любое множество поведений можно описать с помощью свойства безопасности (safety) и свойства живучести (liveness). Вместо этого мы поговорим о написании строгих спецификаций для стандартных поведенческих моделей. Живучесть означает, что рано или поздно произойдет что-то хорошее, т. Безопасность означает, что ничего плохого не произойдет, программа не выдаст неверный ответ. программа рано или поздно даст правильный ответ. е. Поэтому для экономии времени я не буду говорить об живучести, хотя она, конечно, тоже важна. Как правило, безопасность является более важным показателем, ошибки чаще всего возникают именно здесь.
И, во-вторых, отношения со всеми возможными следующими состояниями для каждого состояния. Мы добиваемся безопасности, прописывая, во-первых, множество возможных исходных состояний. Набор исходных состояний описывается формулой, например, в случае алгоритма Евклида: (x = M) ∧ (y = N). Будем вести себя как ученые и определим состояния математически. Отношение со следующим состоянием описывается формулой, в которой переменные следующего состояния записываются со штрихом, а текущего состояния — без штриха. Для определенных значений M и N существует только одно исходное состояние. В случае с алгоритмом Евклида мы будем иметь дело с дизъюнкцией двух формул, в одной из которых x является наибольшим значением, а во второй — y:

Во втором случае мы делаем наоборот. В первом случае новое значение y равно прежнему значению y, а новое значение x мы получаем, отняв от большей переменной меньшую.
Предположим вновь, что M = 12, N = 18. Вернемся к алгоритму Евклида. Затем мы подставляем эти значения в формулу выше и получаем: Это определяет единственное исходное состояние, (x = 12) ∧ (y = 18).

Точно так же мы можем описать все состояния в нашем поведении: [x = 12, y = 18] → [x = 12, y = 6] → [x = 6, y = 6]. Здесь единственное возможное решение: x' = 18 - 12 ∧ y' = 12, и мы получаем поведение: [x = 12, y = 18].
Итак, мы имеем полную спецификацию второго шага — как видим, это вполне обычная математика, как у инженеров и ученых, а не странная, как в computer science. В последнем состоянии [x = 6, y = 6] обе части выражения будут ложны, следовательно, следующего состояния у него нет.
Она элегантна и объяснить ее нетрудно, но на неё сейчас нет времени. Эти две формулы можно объединить в одну формулу темпоральной логики. Темпоральная логика как таковая не нравится, это не вполне обычная математика, но в случае с живостью она является необходимым злом. Темпоральная логика нам может понадобиться только для свойства живости, для безопасности она не нужна.
Другими словами, алгоритм Евклида детерминированный. В алгоритме Евклида для каждого значения x и y есть уникальные значения x' и y', которые делают отношение со следующим состоянием истинным. Это несложно сделать, но сейчас приводить примеры я не буду. Чтобы смоделировать недетерминированный алгоритм, нужно, чтобы у текущего состояния было несколько возможных будущих состояний, и чтобы у каждого значения переменной без штриха было несколько значений переменной со штрихом, при которых отношение со следующим состоянием является истинным.
Как сделать спецификацию формальной? Чтобы сделать работающий инструмент, нужна формальная математика. Спецификация алгоритма Евклида будет на этом языке выглядеть следующим образом: Для этого нам понадобится формальный язык, например, TLA+.

В сущности, спецификация — это определение, в нашем случае два определения. Символ знака равенства с треугольником означает, что значение слева от знака определено как равное значению справа от знака. В ASCII это будет выглядеть так: К спецификации в TLA+ нужно добавить объявления и некоторый синтаксис, как на слайде выше.

Спецификацию на TLA+ можно проверить, т. Как видим, ничего сложного. обойти все возможные поведения в небольшой модели. е. Это очень эффективный и простой способ проверки, который целиком выполняется автоматически. В нашем случае этой моделью будут определенные значения M и N. Кроме того, можно написать формальные доказательства истинности и проверить их механически, но для этого нужно много времени, поэтому так почти никто не делает.
На первый взгляд это звучит как шутка, но, к сожалению, я говорю это на полном серьезе. Главный недостаток TLA+ в том, что это математика, а программисты и computer scientists боятся математики. Как только на экране появились формулы, у них сразу же сделались стеклянные глаза. Мой коллега только что рассказывал мне, как он пытался объяснить TLA+ нескольким разработчикам. Выражение в PlusCal может быть любым выражением TLA+, то есть, по большому счету, любым математическим выражением. Так что если TLA+ пугает, можно использовать PlusCal, это своего рода игрушечный язык программирования. Благодаря тому, что в PlusCal можно записать любое выражение TLA+, он является значительно более выразительным любого реального языка программирования. Кроме того, в PlusCal есть синтаксис для недетерминистичных алгоритмов. Это не значит, конечно, что сложная спецификация PlusCal превратится в простую на TLA+ — просто соответствие между ними очевидное, не появится дополнительной сложности. Далее, PlusCal компилируется в легко читаемую спецификацию TLA+. В общем, PlusCal может помочь преодолеть фобию математики, его легко понять даже программистам и computer scientists. Наконец, эту спецификацию можно будет проверить инструментами TLA+. В прошлом я какое-то время (около 10 лет) публиковал на нем алгоритмы.
На практике же нужен реальный язык с типами, процедурами, объектами и так далее. Возможно, кто-то возразит, что TLA+ и PlusCal — это математика, а математика работает только на придуманных примерах. Вот, что пишет Крис Ньюкомб, работавший в Amazon: «Мы использовали TLA+ в десяти крупных проектах, и в каждом случае его использование вносило значительный вклад в разработку, потому что мы смогли отловить опасные баги до попадания в продакшн, и потому что он дал нам понимание и уверенность, необходимые для агрессивных оптимизаций производительности, не влияющих на истинность программы». Это не так. Кроме того, бытует мнение, что менеджеров невозможно убедить в необходимости формальных методов, даже если программисты убеждены в их полезности. Часто можно услышать, что при использовании формальных методов мы получаем неэффективный код — на практике же все ровно наоборот. Так что когда менеджеры видят, что TLA+ работает, они с радостью его принимают. А Ньюкомб пишет: «Менеджеры теперь всячески подталкивают к тому, чтобы писать спецификации на TLA+, и специально выделяют на это время». Другой пример относится к проектированию XBox 360. Крис Ньюкомб написал это где-то шесть месяцев тому назад (в октябре 2014 года), сейчас же, насколько я знаю, TLA+ используется в 14 проектах, а не 10. Благодаря этой спецификации был найден баг, который иначе был бы не замечен, и из-за которого каждая XBox 360 падала бы после четырех часов использования. К Чарльзу Текеру пришел стажер и написал спецификацию для системы памяти. Инженеры из IBM подтвердили, что их тесты не обнаружили бы этот баг.
Нам редко приходится писать программы, которые вычисляют наименьший общий делитель и тому подобное. Более подробно про TLA+ вы можете почитать в интернете, а сейчас давайте поговорим о неформальных спецификациях. После самой простой обработки код на TLA+ выглядел бы следующим образом: Значительно чаще мы пишем программы вроде инструмента структурной распечатки (pretty-printer), который я написал для TLA+.

Так что правильное форматирование выглядело бы скорее так: Но в приведенном примере пользователь скорее всего хотел, чтобы знаки конъюнкции и равенства были выравнены.
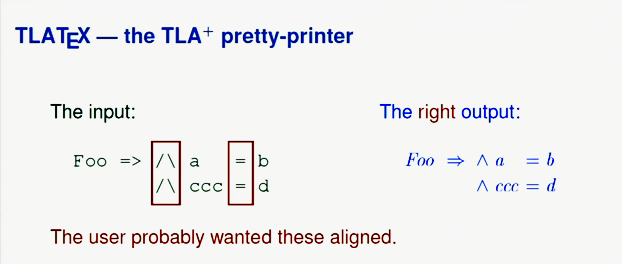
Рассмотрим другой пример:

В общем, точного математического определения верного форматирования нет, потому что «правильное» в данном случае значит «такое, какое хочет пользователь», а это математически определить нельзя. Здесь, наоборот, выравнивание знаков равенства, сложения и умножения в источнике было случайным, поэтому самой простой обработки вполне достаточно.
Но это не так. Казалось бы, если у нас нет определения истинности, то спецификация бесполезна. Спецификация здесь особенно важна. Если мы не знаем, что именно программа должна сделать, это не значит, что нам не нужно продумывать ее работу — наоборот, мы должны потратить на это еще больше усилий. В итоге я написал спецификацию из шести правил с определениями в форме комментариев в Java-файле. Определить оптимальную программу для структурной распечатки невозможно, но это не значит, что мы не должны за нее браться вообще, а писать код как поток сознания — это не дело. Это правило написано на, скажем так, математическом английском: LeftComment aligned, left-comment и covering token — термины с определениями. Вот пример одного из правил: a left-comment token is LeftComment aligned with its covering token. Польза от такой спецификации в том, что понять и отладить шесть правил значительно проще, чем 850 строк кода. Это то, как математики описывают математику: пишут определения терминов и на основе них — правила. Специально для этой цели я написал код, который сообщал, какое именно правило используется. Надо сказать, что написать эти правила было непросто, довольно много времени ушло на их отладку. В Java для этого есть отличные инструменты. Благодаря тому, что я проверил эти шесть правил на нескольких примерах, мне не нужно было отлаживать 850 строк кода, и баги оказалось довольно легко найти. Если бы я просто написал код, то у меня ушло бы значительно больше времени, и форматирование получилось бы худшего качества.
С одной стороны, правильность выполнения здесь не слишком важна. Почему нельзя было использовать формальную спецификацию? Еще важнее тот факт, что у меня не было адекватных инструментов. Структурная распечатка обязательно кому-то не угодит, так что мне не нужно было добиваться правильной работы во всех неординарных ситуациях. Средство для проверки моделей TLA+ здесь бесполезно, так что мне пришлось бы вручную писать примеры.
Она более высокого уровня, чем код. У приведенной спецификации есть черты, общие для всех спецификаций. Для ее написания бесполезны какие-либо инструменты или методы. Реализовать ее можно на любом языке. И не существует инструментов, которые могли бы сделать эту спецификацию ненужной, если, конечно, вы не пишете язык специально для написания программ структурной распечатки на TLA+. Никакой курс программирования вам не поможет написать эту спецификацию. Мы пишем спецификацию, чтобы помочь нам продумать проблему, прежде чем мы начнем думать о коде. Наконец, эта спецификация ничего не говорит о том, как именно мы будем писать код, в ней только указывается, что этот код делает.
95% других спецификаций значительно короче и проще: Но у этой спецификации есть и особенности, отличающие ее от других спецификаций.

Как правило, это признак плохой спецификации. Далее, эта спецификация является набором правил. Тем не менее, в данном случае лучшего способа мне было не найти. Понять последствия набора правил довольно трудно, и именно поэтому мне пришлось потратить много времени на их отладку.
Как правило, они работают параллельно, например, операционные системы или распределенные системы. Стоит сказать несколько слов о программах, которые работают непрерывно. Поэтому необходимы инструменты, которые будут проверять нашу работу — например, TLA+ или PlusCal. Разобраться в них в уме или на бумаге могут очень немногие, и я к их числу не принадлежу, хотя когда-то мне это было по силам.
На самом деле, мне только казалось, будто бы я это знаю. Зачем нужно было писать спецификацию, если я и так знал, что именно код должен делать? У меня есть правило: не должно быть никаких общих правил. Кроме того, при наличии спецификации постороннему человеку уже не нужно залезать в код, чтобы понять, что именно он делает. У этого правила, конечно же, есть исключение, это единственное общее правило, которому я следую: спецификация того, что делает код, должна сообщать людям все, что им нужно знать при использовании этого кода.
Для начала, то же, что и всем: если ты не пишешь, то тебе только кажется, что ты мыслишь. Итак, что именно программистам нужно знать о мышлении? Спецификация — это то, что мы пишем перед тем, как начать кодить. Кроме того, нужно думать, прежде чем кодить, а это значит, нужно писать, прежде чем кодить. И этим «кто-либо» может оказаться сам автор кода через месяц после его написания. Спецификация нужна для любого кода, который может быть кем-либо использован или изменен. Что именно нужно писать о коде? Спецификация нужна для больших программ и систем, для классов, для методов и иногда даже для сложных участков отдельного метода. Иногда может также быть необходимо указать, как именно код достигает своей цели. Нужно описать, что он делает, то есть то, что может быть полезно любому человеку, использующему этот код. Если же это нечто более специальное и новое, то мы называем это высокоуровневым проектированием. Если этот способ мы проходили в курсе алгоритмов, то мы называем это алгоритмом. Формальной разницы здесь нет: и то, и другое является абстрактной моделью программы.
Главное: она должна быть на уровень выше самого кода. Как именно следует писать спецификацию кода? Она должна быть настолько строгой, насколько этого требует задача. Она должна описывать состояния и поведения. Учиться писать спецификации нужно на формальных спецификациях. Если вы пишете спецификацию способа реализации задачи, то ее можно написать на псевдокоде или при помощи PlusCal. А как научиться писать формальные спецификации? Это даст вам необходимые навыки, которые помогут в том числе и с неформальными. То же самое здесь: нужно написать спецификацию, проверить ее при помощи средства проверки моделей и исправить ошибки. Когда мы учились программированию, мы писали программы, а затем отлаживали их. Преимущество TLA+ в том, что он отлично учит математическому мышлению. TLA+, возможно, не самый лучший язык для формальной спецификации, и для ваших конкретных нужд скорее всего лучше подойдет другой язык.
При помощи комментариев, которые связывают математические понятия и их реализацию. Как связать спецификацию и код? Поэтому вам нужно написать, как именно граф реализуется этими структурами программирования. Если вы работаете с графами, то на уровне программы у вас будут массивы узлов и массивы связей.
Когда вы пишете код, то есть выполняете третий шаг, вам тоже нужно мыслить и продумывать программу. Нужно заметить, что ничто из вышесказанного не относится к самому процессу написания кода. Но о самом коде я здесь не говорю. Если подзадача оказывается сложной или неочевидной, нужно написать для нее спецификацию. Кроме того, ничто из вышесказанного не избавляет от необходимости тестировать и отлаживать код. Вы можете пользоваться любым языком программирования, любой методологией, речь не о них. Даже если абстрактная модель написана верно, в ее реализации могут быть баги.
Благодаря нему многие ошибки можно отловить меньшими усилиями — мы это знаем по опыту программистов из Amazon. Написание спецификаций — дополнительный этап в процессе написания кода. Так почему же тогда мы так часто обходимся без них? Со спецификациями качество программ становится выше. А писать трудно, потому что для этого нужно думать, а думать тоже трудно. Потому что писать трудно. Здесь можно провести аналогию с бегом — чем меньше вы бегаете, тем медленнее вы бежите. Всегда проще делать вид, что думаешь. Нужна практика. Нужно тренировать свои мускулы и упражняться в письме.
Вы могли где-то сделать ошибку, или могли измениться требования, или оказалось необходимо сделать улучшение. Спецификация может быть неверной. В идеале в этом случае нужно написать новую спецификацию и полностью переписать код. Любой код, которым кто-либо пользуется, приходится менять, поэтому рано или поздно спецификация перестанет соответствовать программе. На практике мы патчим код и, возможно, обновляем спецификацию. Мы прекрасно знаем, что так никто не делает. Во-первых, для человека, который будет править ваш код, каждое лишнее слово в спецификации будет на вес золота, и этим человеком вполне можете быть вы сами. Если это обязательно рано или поздно происходит, то зачем вообще писать спецификации? А я пишу больше спецификаций, чем кода. Я часто ругаю себя за недостаточную спецификацию, когда правлю свой код. Во-вторых, с каждой правкой код становится хуже, его становится все труднее читать и поддерживать. Поэтому, когда вы правите код, спецификацию всегда нужно обновлять. Но если вы не начинаете со спецификации, то каждая написанная строка будет правкой, и код с самого начала будет громоздким и трудночитаемым. Это нарастание энтропии.
А он знал кое-что о битвах. Как говорил Эйзенхауер, ни одна битва не была выиграна по плану, и ни одна битва не была выиграна без плана. Иногда это действительно так, и задача настолько проста, что продумывать ее нечего. Существует мнение, что написание спецификаций — пустая трата времени. И об этом каждый раз следует подумать. Но всегда нужно помнить, что, когда вам советуют не писать спецификаций, это значит, что вам советуют не думать. Как мы знаем, волшебной палочки никто не изобрел, и программирование — сложное занятие. Продумывание задачи не гарантирует, что вы не совершите ошибок. Но если вы не продумываете задачу, вы гарантированно сделаете ошибки.
На этом у меня все, спасибо за внимание. Подробнее про TLA+ и PlusCal можно почитать на специальном сайте, туда можно зайти с моей домашней страницы по ссылке.
Когда вы будете писать комментарии — помните, что автор их не прочитает. Напоминаю, что это перевод. Билеты можно приобрести на официальном сайте. Если вам действительно хочется пообщаться с автором, то он будет на конференции Hydra 2019, которая пройдёт 11-12 июля 2019 года в Санкт-Петербурге.





![Фото [Перевод] Gmail исполнилось двадцать лет](http://orion-int.ru/wp-content/uploads/2024/04/perevod-gmail-ispolnilos-dvadcat-let-220x150.jpg.pagespeed.ce.UvOK2tKHyL.jpg)
