
Сила JavaScript и браузерного API
Мир становится все более взаимосвязанным — число людей, имеющих доступ к Интернету, выросло до 4,5 миллиардов.

Даже в Соединенных Штатах 4,9 миллиона домов не могут получить проводной доступ к интернету скорость которого будет более 3 мегабит в секунду. Но в этих данных не отражено количество людей, у которых медленное или неисправное интернет соединение.
Некоторые факторы, которые могут повлиять на качество сетевого подключения, включают в себя: Остальной мир — те, кто имеет надежный доступ к Интернету — все еще подвержен потере соединения.
- Плохое покрытие от провайдера.
- Экстремальные погодные условия.
- Перебои питания.
- Пользователи, попадающие в «мертвые зоны», такие как здания, которые блокируют их сетевые подключения.
- Путешествие на поезде и проезд туннелей.
- Соединения, которые управляются третьей стороной и ограничены во времени.
- Культурные практики, которые требуют ограниченного или отсутствия доступа в Интернет в определенное время или дни.
Учитывая это, ясно, что мы должны учитывать автономный опыт при разработке и создании приложений.
Статья переведена при поддержке компании EDISON Software, которая выполняет «на отлично» заказы из Южного Китая, а также разрабатывает веб-приложения и сайты.

Техническая работа, необходимая для того, чтобы приложение работало в автономном режиме, сводилась к четырем отдельным задачам, о которых я расскажу в этом посте. Недавно у меня была возможность добавить автономность к существующему приложению, используя service workers, cache storage и IndexedDB.
Service Workers
Приложения, созданные для работы в автономном режиме, не должны сильно зависеть от сети. Концептуально это возможно только в том случае, если в случае сбоя существуют запасные варианты.
Откуда берутся эти ресурсы, если не из сетевого запроса? При ошибке загрузки веб-приложения, мы должны где-то взять ресурсы для браузера(HTML/CSS/JavaScript). Большинство людей согласятся с тем, что лучше предоставлять потенциально устаревший пользовательский интерфейс, чем пустую страницу. Как насчет кеша.
Служба кэширования данных в качестве запасного варианта все еще требует, чтобы мы каким-то образом перехватывали запросы браузера и писали правила кэширования. Браузер постоянно делает запросы к данным. Здесь service workers вступают в игру — думайте о них как о посреднике.
Service worker — это просто файл JavaScript, в котором мы можем подписаться на события и написать свои собственные правила для кэширования и обработки сетевых сбоев.
Давайте начнем.
Обратите внимание: наше демо приложение
Демо-приложение представляет собой простую страницу взятия/сдачи книг в библиотеке. На протяжении всего этого поста мы будем добавлять автономные функции в демо приложение. Прогресс будет представлен в виде серии GIF-файлов, и использования офлайн симуляции Chrome DevTools.
Вот начальное состояние:
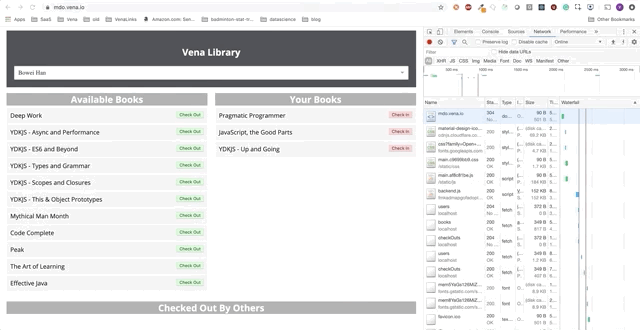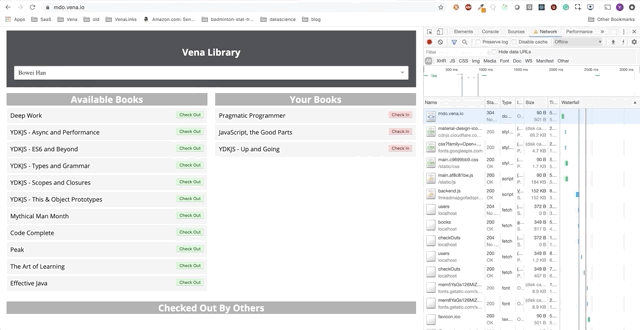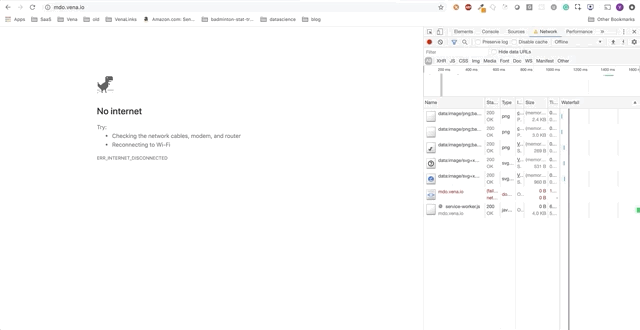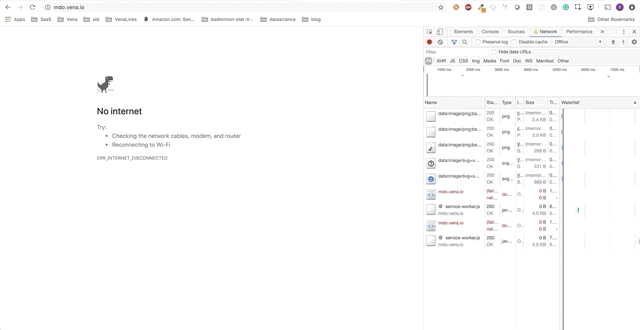
Задача 1 — Кэширование статических ресурсов
Статические ресурсы — это ресурсы, которые меняются не часто. HTML, CSS, JavaScript и изображения могут попадать в эту категорию. Браузер пытается загрузить статические ресурсы с помощью запросов, которые могут быть перехвачены service worker’ом.
Начнем с регистрации нашего service worker’a.
if ('serviceWorker' in navigator) );
}
Регистрация происходит с помощью метода register после загрузки сайта.
Теперь, когда у нас загружен service worker — давайте закешируем наши статические ресурсы.
var CACHE_NAME = 'my-offline-cache';
var urlsToCache = [ '/', '/static/css/main.c9699bb9.css', '/static/js/main.99348925.js'
]; self.addEventListener('install', function(event) { event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { return cache.addAll(urlsToCache); }) );
});
Поскольку мы контролируем URL-адреса статических ресурсов, мы можем их кэшировать сразу после инициализации service worker’a используя Cache Storage.
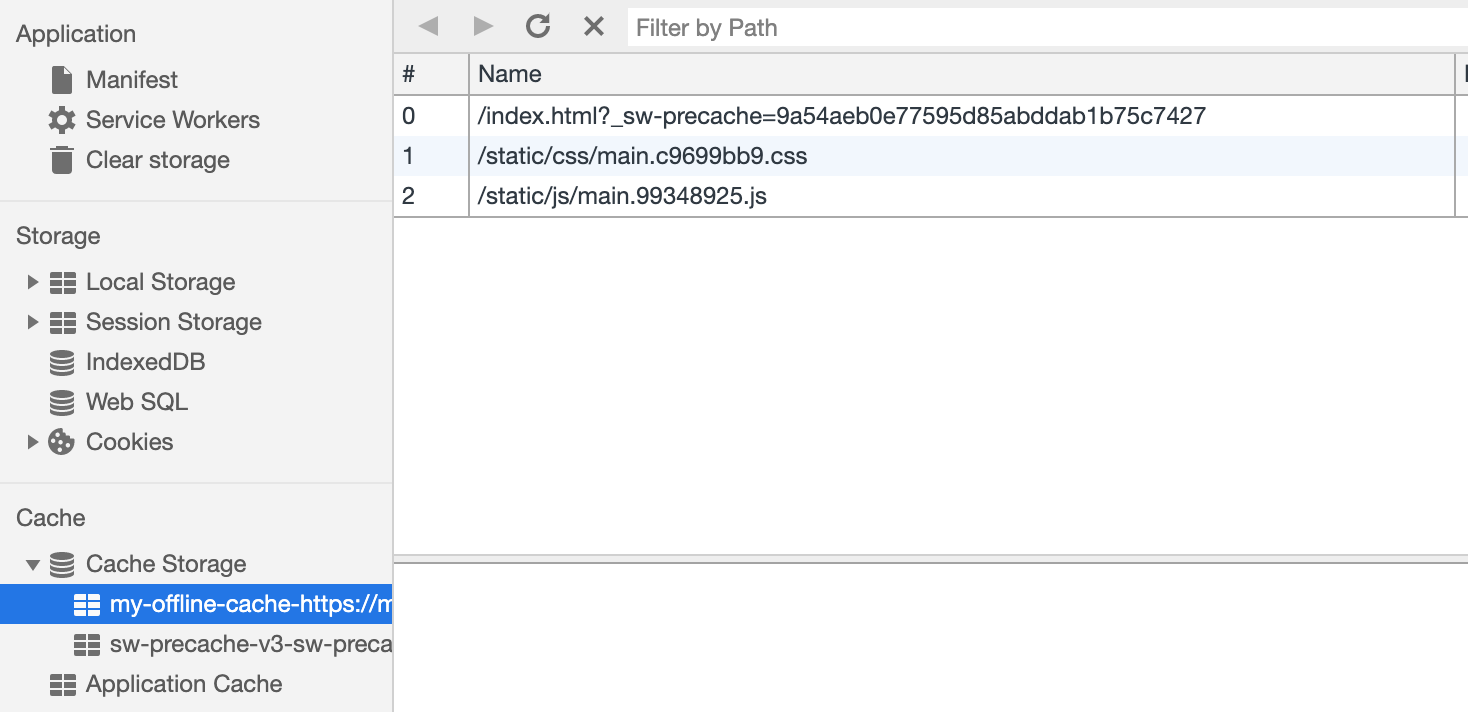
Теперь, когда наш кэш заполнен самыми последними запрашиваемыми статическими ресурсами, давайте загружать эти ресурсы из кэша в случае сбоя запроса.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); );
});
Наш новый обработчик события fetch теперь имеет дополнительную логику для возврата кэшированных ответов в случае сбоев сети. Событие fetch запускается каждый раз, когда браузер делает запрос.
Демо № 1
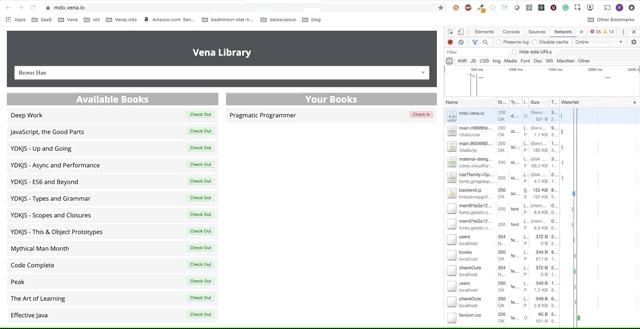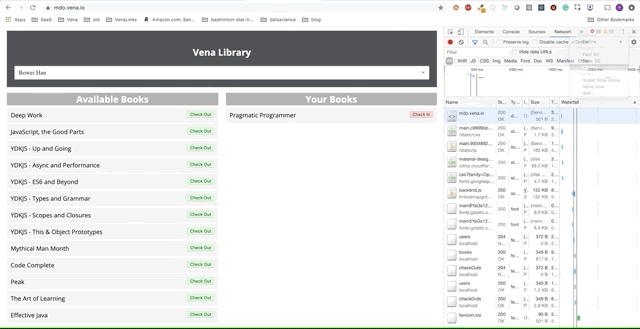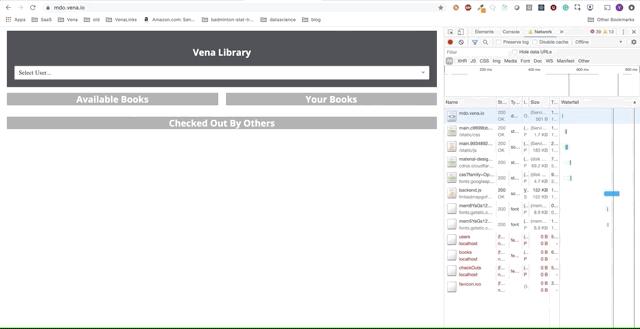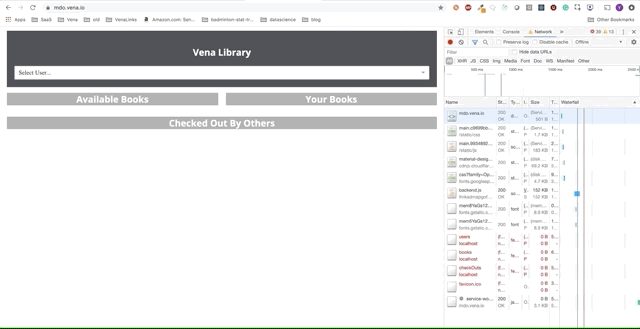
Но где наши данные? Наше демо-приложение теперь может обслуживать статические ресурсы в автономном режиме!
Задача 2 — Кэширование динамических ресурсов
Одностраничные приложения (SPA) обычно запрашивают данные постепенно после начальной загрузки страницы, и наше демо приложение не является исключением — список книг не загружается сразу. Эти данные обычно поступают из запросов XHR, которые возвращают ответы, которые часто меняются, чтобы предоставить новое состояние приложения — таким образом, они являются динамическими.
Генерировать полный список всех возможных динамических запросов XHR также довольно сложно, поэтому мы будем их кэшировать по мере их поступления, а не иметь заранее определенный список, как мы делали для статических ресурсов. Кэширование динамических ресурсов на самом деле очень похоже на кэширование статических ресурсов — главное отличие состоит в том, что нам нужно обновлять кэш чаще.
Посмотрим на наш обработчик fetch:
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); );
});
Это гарантирует, что мы постоянно добавляем новые запросы в наш кеш и постоянно обновляем кэшированные данные. Мы можем настроить эту реализацию, добавив немного кода, который кэширует успешные запросы и ответы.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request) .then(function(response) { caches.open(CACHE_NAME).then(function(cache) { cache.put(event.request, response); }); }) .catch(function() { caches.match(event.request).then(function(response) { return response; } ); );
});
Наш Cache Storage в настоящее время имеет несколько записей.

Демо № 2
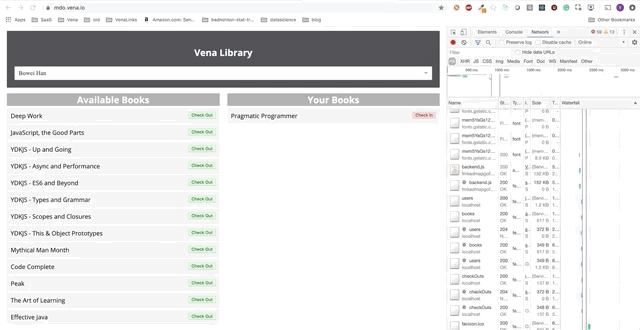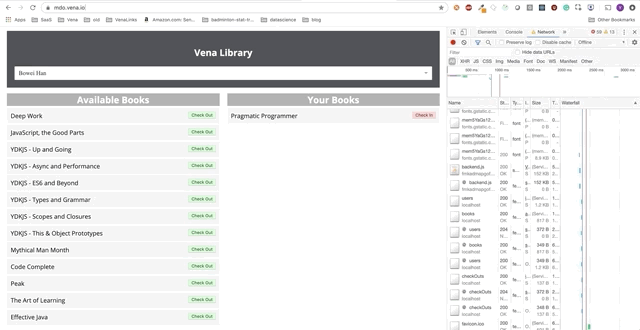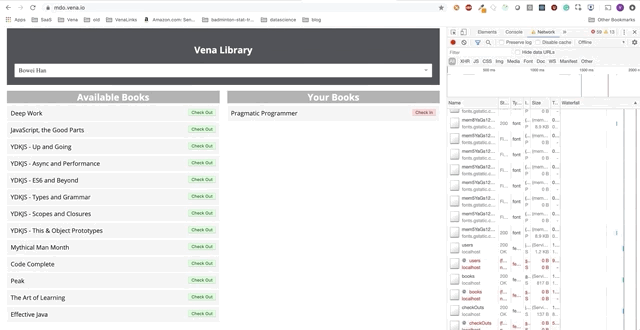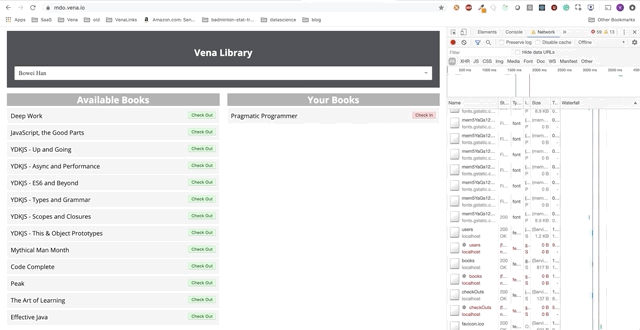
Наше демо теперь выглядит одинаково при начальной загрузке, независимо от нашего статуса сети!
Давайте теперь попробуем использовать наше приложение. Отлично.
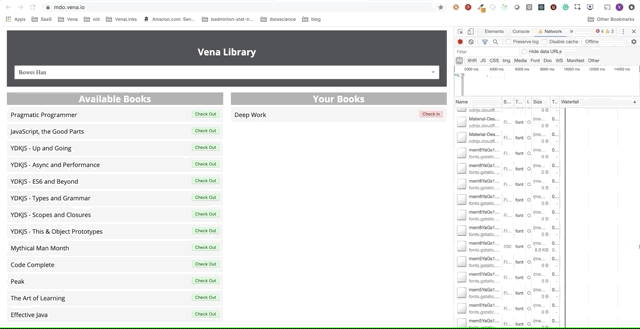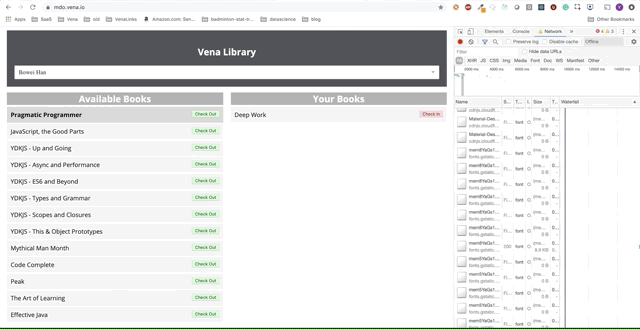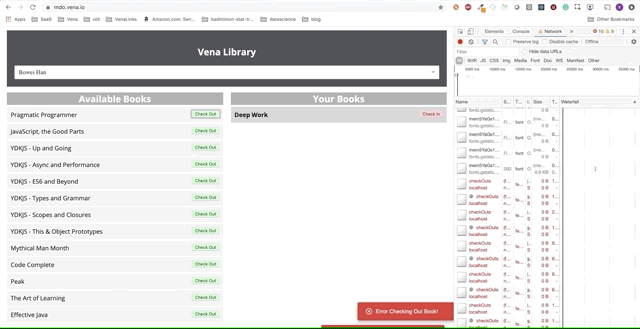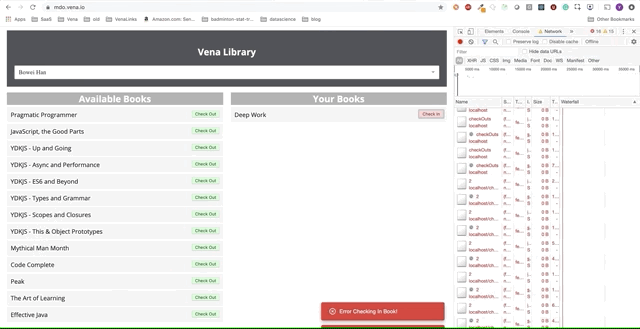
Похоже, все наши взаимодействия с интерфейсом не работают. К сожалению — сообщения об ошибках везде. Что нужно исправить? Я не могу выбрать или сдать книгу!
Задача 3 — Построить оптимистичный пользовательский интерфейс
На данный момент проблема с нашим приложением заключается в том, что наша логика сбора данных все еще сильно зависит от сетевых ответов. Действие check-in или check-out отправляет запрос на сервер и ожидает успешного ответа. Это отлично для согласованности данных, но плохо для нашего автономного опыта.
Оптимистичные взаимодействия не требуют ответа от сервера и охотно отображают обновленное представление данных. Чтобы эти взаимодействия работали в автономном режиме, нам нужно сделать наше приложение более оптимистичным. Обычная оптимистичная операция в большинстве веб-приложений это delete — почему бы не дать пользователю мгновенную обратную связь, если у нас уже есть вся необходимая информация?
Отключение нашего приложения от сети с использованием оптимистичного подхода является относительно простой в реализации.
case CHECK_OUT_SUCCESS:
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, };
case CHECK_IN_SUCCESS:
case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Приведенный выше фрагмент кода взят из redux редюсера нашего приложения, SUCCESS и FAILURE запускается в зависимости от доступности сети. Ключ — обрабатывать действия пользователя одинаково — независимо от того, успешен ли сетевой запрос или нет. Независимо от того, как выполнен сетевой запрос, мы собираемся обновить наш список книг.
Демо № 3
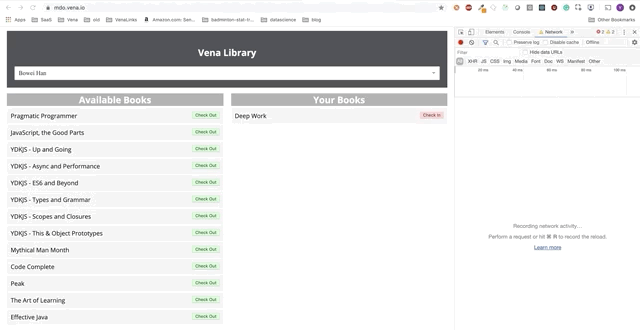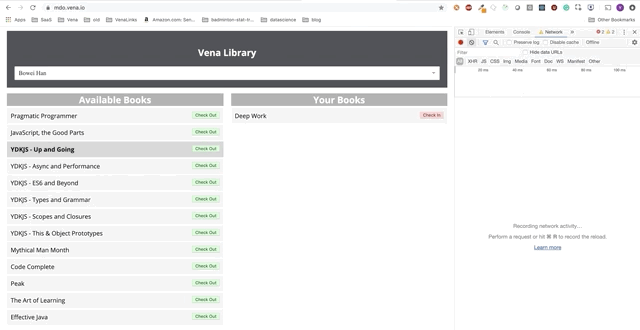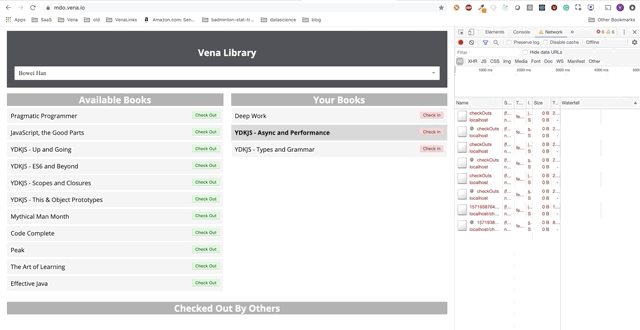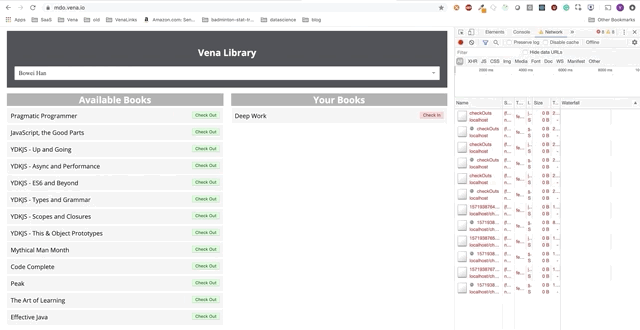
Кнопки «check-in» и «check-out» обновляют интерфейс соответствующим образом, хотя по красным сообщениям консоли видно, что сетевые запросы не выполняются. Взаимодействие с пользователем теперь происходит онлайн (не буквально).
Есть только одна небольшая проблема с оптимистичным рендерингом в автономном режиме… Хорошо!
Разве мы не теряем наши изменения!?

Задача 4 — Собирать действия пользователя в очередь для синхронизации
Нам нужно отслеживать действия, совершенные пользователем, когда он был в автономном режиме, чтобы мы могли синхронизировать их с нашим сервером, когда пользователь вернется в сеть. В браузере есть несколько механизмов хранения, которые могут выступать в качестве очереди действий, и мы собираемся использовать IndexedDB. IndexedDB предоставляет несколько вещей, которые вы не получите от LocalStorage:
- Асинхронные неблокирующие операции
- Значительно более высокие лимиты хранения
- Управление транзакциями
Посмотрите на наш старый код редюсера:
case CHECK_OUT_SUCCESS:
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, };
case CHECK_IN_SUCCESS:
case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Давайте изменим его, чтобы хранить события check-in и check-out в IndexedDB при событии FAILURE.
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); addToDB(action); // QUEUE IT UP return { ...state, list, };
case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); addToDB(action); // QUEUE IT UP } } return { ...state, list, };
Вот реализация создания IndexedDB вместе с хелпером addToDB.
let db = indexedDB.open('actions', 1);
db.onupgradeneeded = function(event) { let db = event.target.result; db.createObjectStore('requests', { autoIncrement: true });
}; const addToDB = action => { var db = indexedDB.open('actions', 1); db.onsuccess = function(event) { var db = event.target.result; var objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.add(action); };
};
Теперь, когда все наши автономные действия пользователя хранятся в памяти браузера, мы можем использовать слушатель события браузера online, чтобы синхронизировать данные, когда соединение восстановится.
window.addEventListener('online', () => { const db = indexedDB.open('actions', 1); db.onsuccess = function(event) { let db = event.target.result; let objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.getAll().onsuccess = function(event) { let requests = event.target.result; for (let request of requests) { send(request); // sync with the server } }; };
});
На этом этапе мы можем очистить очередь от всех запросов, которые мы успешно отправили на сервер.
Демо № 4
Финальное демо выглядит немного сложнее. Справа в темном терминальном окне регистрируется вся активность API. Демо предполагает выход в автономный режим, выбор нескольких книг и возврат в онлайн.
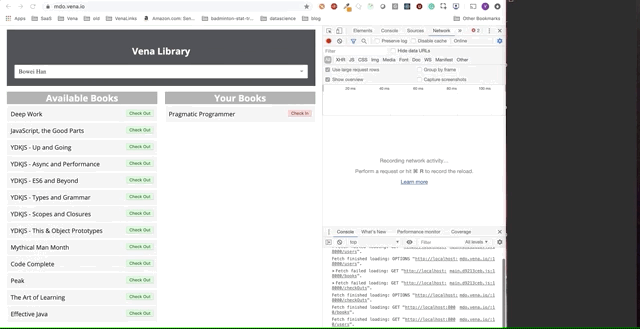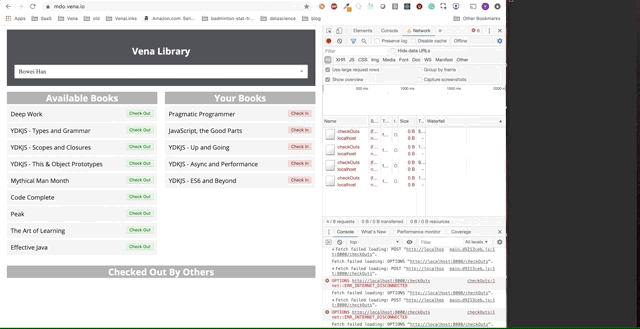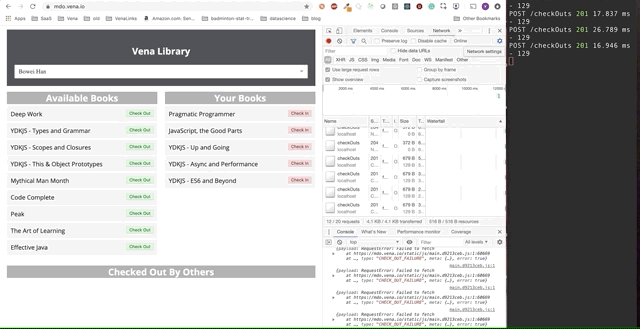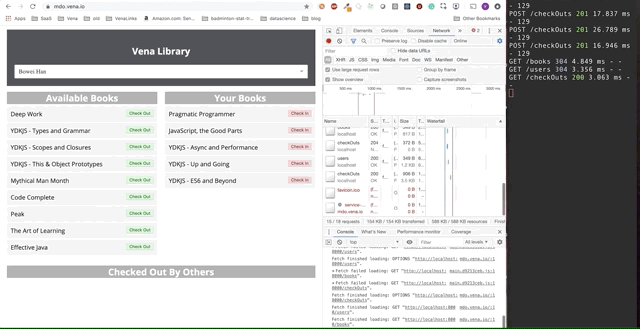
Ясно, что запросы сделанные в автономном режиме были поставлены в очередь и отправляются разом, когда пользователь возвращается в онлайн.
Это также не будет работать, если несколько человек используют одно и то же приложение. Этот подход «воспроизведения» немного наивный — например, нам, вероятно, не нужно делать два запроса, если мы берем и возвращаем одну и ту же книгу.
Это всё
Выйдите и сделайте ваши веб-приложения способным работать в автономном режиме! Этот пост демонстрирует некоторые из многих вещей, которые вы можете сделать, чтобы добавить автономные возможности в свои приложения, и определенно не является исчерпывающим.
Чтобы узнать больше, ознакомьтесь с Google Web Fundamentals. Чтобы увидеть другую офлайн-реализацию, ознакомьтесь с этим докладом.


![Фото [Перевод] Мега-Учебник Flask Глава 1: Привет, мир! (издание 2024)](http://orion-int.ru/wp-content/uploads/2024/04/perevod-mega-uchebnik-flask-glava-1-privet-mir-izdanie-2024-390x220.png)



