

В условиях highload сложность оптимизации реляционных баз данных возрастает на порядок, так как покупка ещё более мощного железа обходится дорого а также уже нет возможности просто выключить приложение ночью для долгого процесса альтера БД и миграции данных.
Теперь же пришёл черёд статьи про то, как мы полностью изменили внутреннюю структуру самой нагруженной и важной базы данных в Badoo, не потеряв при этом ни одного запроса.
Недавно мы рассказали, как мы оптимизировали PHP-код нашего приложения.
Пациент
Users DataBase, или UDB — это сервис, с которого начинается практически любой запрос к Badoo. Он решает несколько задач: во-первых, это центральное хранилище основных пользовательских данных, по которым происходит авторизация (например, email, user_id или facebook_id). Помимо хранения этих данных, сервис обеспечивает контроль уникальности (чтобы в системе не могли зарегистрироваться два пользователя с одинаковым email, facebook_id и т. д.). И этот же сервис даёт информацию о том, в каком из тысяч шардов находятся все остальные данные пользователя.
Всё это обслуживается парами master-slave MySQL-серверов в каждом из наших дата-центров. На конец 2018 года UDB хранит данные более 800 млн пользователей, которые занимают на диске около 1 ТБ. В сумме они обрабатывают более 140 000 запросов в секунду.
Поэтому к нему предъявляются огромные требования по надёжности и доступности. Падение UDB означает недоступность всего Badoo, так как код не сможет найти шард, на котором лежат пользовательские данные.
Однако с течением времени требования, а также профиль нагрузки меняются. Из-за этой специфики проводить изменения в структуре хранения очень дорого, поэтому к проектированию UDB в 2013 году мы подходили крайне серьёзно. И наступил день, когда вместо очередного хака или закупки дорогостоящего железа разумнее было заняться оптимизацией более глобально. В стремлении адаптировать систему под новые требования и уровень нагрузки проводилось много небольших и простых изменений, но, к сожалению, такие изменения далеко не самые эффективные. Дальше мы рассмотрим основные этапы этого пути.
Неинвазивные оптимизации
Любые изменения структуры большой и нагруженной базы данных обходятся довольно дорого из-за сложности процесса миграции данных. Поэтому прежде всего следует исчерпать все варианты оптимизаций, которые не затрагивают структуру данных, а ограничиваются кодом и SQL- запросами. Возможно, этого будет достаточно, чтобы отодвинуть проблему чрезмерной нагрузки на пару лет, что позволит вам в это время заняться чем-то более важным для бизнеса.
Убедитесь, что вы собираете все метрики, которые могут вам помочь. Чем лучше вы понимаете вашу систему, тем проще вам будет найти подходы для подобных оптимизаций. Сколько запросов в секунду у разных типов операций? Речь идёт не только о системных метриках вроде CPU usage и RAM usage или метриках конкретной БД, но и о application-level метриках приложения, которое завязано на оптимизируемой базе данных. Каков размер входных и выходных данных? Какое у них время отклика? Вряд ли вам нужна оптимизация, которая немного снизит CPU usage на сервере БД, но при этом увеличит время отклика вашего приложения в десять раз. Именно по этим метрикам вы сможете судить об успешности проведённых оптимизаций.

Начав собирать дополнительные application-level метрики для UDB, мы смогли лучше понять, какие из выполняемых операций создают 80% нагрузки и являются первыми кандидатами на изучение, а какие используются мало или даже больше вообще не используются.
Просто выделив этот случай в отдельный метод API, который извлекает из таблицы только одну колонку, мы смогли получить выигрыш от использования покрывающего индекса и снять с помощью этого около 5% CPU load c сервера БД. Детальный анализ самой частой операции (извлечение пользователей, соответствующих определённым критериям) показал, что, несмотря на то, что из базы запрашиваются все имеющиеся данные пользователя, в реальности приложение в 95% случаев использует только user_id.
Мы перевели этот запрос на ленивую модель. Анализ другой частой операции показал, что, несмотря на то, что она выполняется на каждый HTTP-запрос, в реальности данные, которые она извлекает, используются крайне редко.
Нет смысла тратить кучу времени и усилий на оптимизацию запросов, составляющих менее 1% от вашего профиля нагрузки. Основная цель метрик в случае проекта по оптимизации — лучше понять вашу базу данных и найти самые мясистые куски. Такими оптимизациями на стороне кода нам удалось снять порядка 15% CPU usage из 80% потребляемого БД. Если у вас нет метрик, которые позволяют понять профиль вашей нагрузки — соберите их.
Тестирование идей
Если вы собираетесь оптимизировать нагруженную БД путём изменения её структуры, следует начать с проверки ваших идей на тестовом стенде, так как даже оптимизации, которые выглядят очень перспективными в теории, на практике могут не дать положительного эффекта (а иногда могут и вовсе дать отрицательный). И вам вряд ли захочется узнать об этом только после проведения долгой миграции данных на продакшене.
Важным моментом является и обеспечение правильной нагрузки стенда. Чем ближе конфигурация вашего стенда будет к конфигурации продакшена, тем более надёжные вы получите результаты. Наилучший вариант — использование реальных запросов с продакшена. Прогон случайных или одних и тех же запросов может привести к недостоверным результатам. За сутки мы собрали лог размером 65 Гб из 700 млн запросов. Для UDB мы логировали с продакшена каждый десятый API-запрос на чтение (включая параметры) в виде просто JSON-лога в файле.
Однако в вашем случае это может быть не так. Запись мы не тестировали, так как по сравнению с количеством запросов на чтение она совсем небольшая и не влияет на нашу нагрузку. Если вы хотите нагружать тестовый стенд запросами на запись, придётся собирать каждый запрос, так как пропуск запросов на запись может привести к ошибкам консистентности на тестовом стенде.
Мы использовали 400 воркеров на PHP, запущенных из нашего скриптового облака, которые читают собранный лог из быстрой очереди и последовательно выполняют запросы. Следующий этап — это корректно проиграть лог на стенде. Для проверки идей мы использовали скорость х10, что помноженное на то что мы собирали с продакшена только каждый десятый запрос, дало такое же количество RPS, что и на продакшене. При этом очередь наполняется другим скриптом со строго определённой скоростью.

При таких коэффициентах получается, что сутки продакшена со всеми перепадами нагрузки на тестовом стенде пролетают всего за два с половиной часа.
Так, например, выглядел первый тест который мы запустили на скорости х5 (50% нагрузки с продакшена) на логе запросов за половину суток:
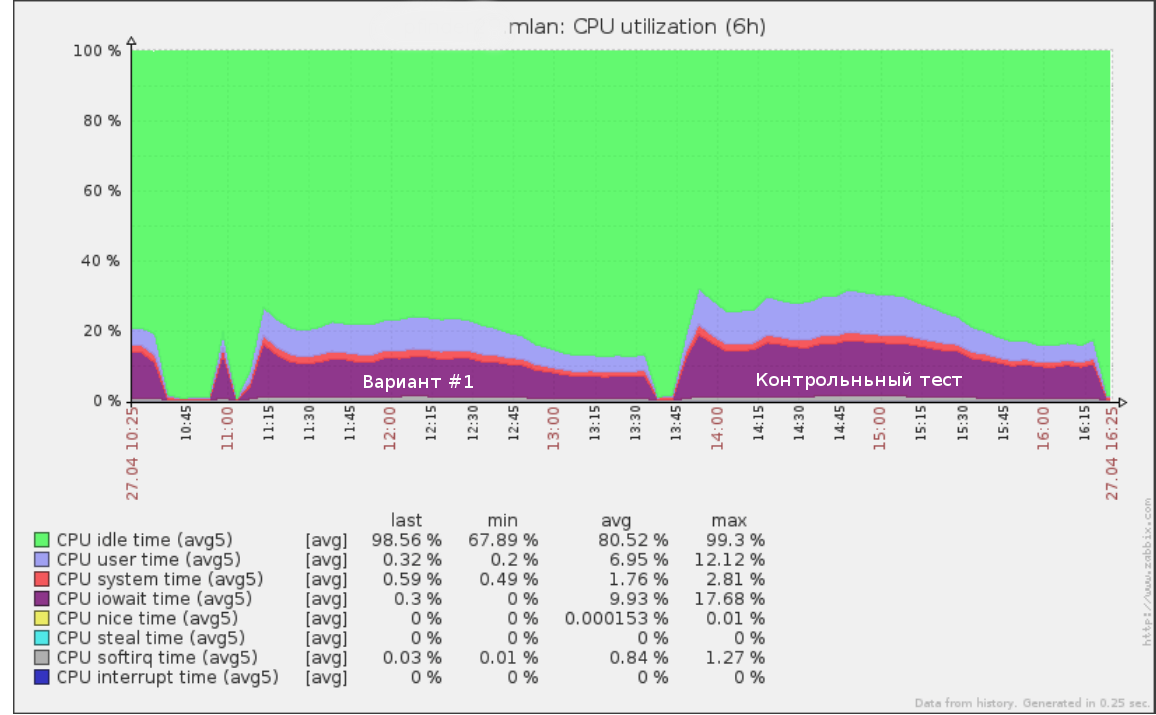
Это даст вам чёткое понимание того, сколько ещё нагрузки может выдержать ваша БД. Этим же инструментарием можно воспользоваться, чтобы провести тест на отказ: повышая скорость (а значит, RPS) до тех пор, пока база на стенде не начнёт деградировать.
Если его результаты и текущие показатели на продакшене сильно различаются, прежде всего следует разобраться в причинах. После тестирования новой схемы данных важно также провести контрольный тест на оригинальной структуре БД. Возможно, тестовый сервер сконфигурирован некорректно и данным нагрузочного тестирования нельзя доверять.
Нет особого смысла тестировать производительность запросов, которые не выполняют нужную работу. Также стоит убедиться в том, что новый код работает корректно. Хорошую службу вам сослужат интеграционные тесты, которые проверяют, возвращают ли старый и новый API одинаковые значения на одни и те же вызовы API.
После получения результатов по всем идеям остаётся только выбрать варианты с наилучшим соотношением между ценой и качеством и внедрить новую схему на продакшене.
Изменение схемы
В первую очередь отмечу, что изменение схемы данных не останавливая при этом работу сервиса — это всегда довольно сложно, дорого и рискованно. Поэтому если у вас есть возможность остановить ваше приложение на время изменения структуры — просто сделайте это. В случае с UDB мы, к сожалению, такое позволить себе не могли.
Если все предполагаемые изменения таблиц не выходят за рамки просто альтера (например, добавление пары новых индексов или колонок), то их можно провернуть типовыми процессами вроде pt-online-schema-change и gh-ost для MySQL или альтером слейва с последующей сменой их местами. Второй фактор, влияющий на сложность изменения схемы, — это планируемый масштаб изменений.
Такое преобразование типовыми инструментами уже не осуществить. В нашем случае отличный результат показало вертикальное шардирование одной гигантской таблицы на примерно десяток поменьше с другими колонками и индексами и данными в другом формате. Так что же делать?
Мы применили следующий алгоритм:
- Добиваемся состояния, когда одновременно существуют старая и новая схемы с актуальными данными. Запись идёт в обе, и при этом есть гарантия консистентности данных в обеих версиях. Этот пункт мы подробно рассмотрим ниже.
- Постепенно переключаем всё чтение на новую схему, контролируя нагрузку.
- Выключаем запись в старую схему и удаляем её.
Основные плюсы этого подхода:
- безопасность: есть возможность мгновенного отката вплоть до последнего этапа (просто переключаем чтение обратно на старую схему, если что-то пошло не так);
- полный контроль нагрузки при миграции данных;
- не требуется тяжёлый альтер большой таблицы старой схемы.
Однако есть и минусы:
- необходимость держать на диске обе версии схем в процессе миграции (это может быть проблемой, если места у вас мало, а мигрируемая таблица очень большая);
- много временного кода для поддержки процесса миграции, который будет спилен по завершении;
- возможно вымывание кеша чтением из двух схем параллельно; было опасение, что старая и новая версии будут конкурировать за оперативную память, что может привести к деградации сервиса (в реальности это действительно создало дополнительную нагрузку, однако, так как миграция проводилась в офф-пики, то проблем это для нас не создало).
Основную сложность в данном алгоритме представляет первый пункт. Его и рассмотрим подробно.
Синхронизация изменений
Миграция статичных данных особой сложности не представляет. Однако что делать, если вы не можете просто остановить всю запись на время миграции БД?
Есть несколько вариантов добиться синхронизации новой схемы: миграция с накатыванием лога и миграция идемпотентной записью.
Миграция снепшота данных с последующим проигрыванием лога следующих изменений
Каждая транзакция по обновлению данных логируется специальную таблицу через триггеры или на уровне приложения, либо в качестве лога используется бинлог репликации. После того как вы имеете такой лог, вы можете открыть транзакцию и смигрировать снепшот данных, запомнив при этом позицию в логе. Далее остаётся начать применять собранный лог на новой схеме. Подобным образом работает, например, популярный инструмент для бекапа MySQL Percona XtraBackup.
После того как новая схема догнала лог до текущей записи, наступает самый ответственный этап: нужно всё же приостановить запись в старую схему на небольшой промежуток времени и, убедившись, что к новой схеме применён весь доступный лог, а значит, данные между схемами консистентны, на уровне приложения включить запись сразу в оба источника.
Основные минусы этого подхода заключаются в том, что вам понадобится как-то хранить лог операций, что само по себе может создать нагрузку, в сложном процессе переключения, а также в вероятности сломать запись, если по какой-то причине схемы окажутся неконсистентными.
Идемпотентная запись
Основная идея этого подхода в том, чтобы начать писать в новую схему параллельно с записью в старую ещё до полной синхронизации изменений, а после завершить миграцию оставшихся данных. Аналогичным образом обычно заполняются новые колонки в больших таблицах.
Я советую делать это именно в коде, так как вам в любом случае в итоге придётся написать код, который будет записывать данные в новую схему, а реализация миграции на стороне кода обеспечит вам больше контроля. Синхронная запись может быть реализована как на триггерах БД, так и в исходном коде.
Из-за этого возможен сценарий, когда обновление новой таблицы приводит к нарушению констрейнта БД (внешних ключей или уникального индекса), в то время как с точки зрения текущей схемы транзакция полностью корректна и должна быть проведена. Важный момент, который стоит учесть, — это то, что до завершения миграции новая схема будет находиться в неконсистентном состоянии.
Простейшие способы обойти эту проблему — добавить модификатор IGNORE ко всем запросам на запись данных в новую схему или перехватывать откат такой транзакции и запускать версию без записи в новую схему. Такая ситуация может привести к откату хороших транзакций из-за процесса миграции.
Алгоритм синхронизации посредством идемпотентной записи в нашем случае выглядит следующим образом:
- Включаем запись в новую схему параллельно с записью в старую в режиме совместимости (IGNORE).
- Запускаем скрипт, который постепенно обходит новую схему и фиксит неконсистентные данные. После этого данные в обеих таблицах должны быть синхронизированы, но это неточно из-за возможных конфликтов в п. 1.
- Запускаем чекер консистентности данных — открываем транзакцию и последовательно читаем строки из новой и старой схемы сравнивая их соответствие.
- Если остались конфликты, досинкиваем и возвращаемся к п. 3.
- После того как чекер показал, что данные в обеих схемах синхронизированы, то дальнейших расхождений схем уже быть не должно, если, конечно мы не пропустили какой-то нюанс. Поэтому ждём какое-то время (например, неделю) и запускаем контрольный чек. Если и он показывает, что всё хорошо, то задача выполнена успешно и можно переводить чтение.
Результаты
В результате изменения формата данных нам удалось уменьшить размер основной таблицы с 544 Гб до 226 Гб, тем самым уменьшив нагрузку на диск и увеличив количество полезных данных, помещающихся в оперативной памяти.
Результаты последующего нагрузочного теста показали, что при текущих темпах роста нагрузки мы можем оставаться на имеющемся железе ещё как минимум в течение трёх лет. Суммарно с начала проекта применением всех описанных подходов нам удалось снизить CPU usage сервера БД с 80% до 35% в пик трафика.
Разбиение одной огромной таблицы на несколько упростило процесс проведения будущих альтеров в БД, а также заметно ускорило некоторые скрипты, которые собирали данные для BI.
![Фото [Перевод] Самонагревающийся бетон на шаг ближе к тому, чтобы избавить нас от использования снеговых лопат и соли](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-samonagrevayushhijsya-beton-na-shag-blizhe-k-tomu-chtoby-izbavit-nas-ot-ispolzovaniya-snegovyx-lopat-i-soli-390x220.jpg.pagespeed.ic.nP1EbRJPy7.jpg)




![Фото [Перевод] Как программировали в 1969 году](http://orion-int.ru/wp-content/uploads/2024/03/perevod-kak-programmirovali-v-1969-godu-220x150.jpg)
