

И не только собрать, а еще очистить от дублей и мусора. Типичный проект системной интеграции для нас выглядит так: у заказчика вагон систем для учета клиентов, задача — собрать клиентские карточки в единую базу. Чтобы на выходе получились чистые, структурированные, полные карточки клиентов.
Для начинающих поясню, что миграция идет по такой схеме: источники → преобразование данных (отвечает ETL или шина) → приемник.
Самое обидное, что этого можно было избежать.
Работали так: На одном проекте мы потеряли три месяца просто потому, что сторонняя команда интеграторов не изучала данные в системах-источниках.
- Системные интеграторы настраивают ETL-процесс.
- ETL преобразует исходные данные и отдает мне.
- Я изучаю выгрузку и отправляю ошибки интеграторам.
- Интеграторы исправляют ETL и снова запускают миграцию.
В статье покажу, как анализировать данные при системной интеграции. Я изучала выгрузки из ETL, было очень полезно. Но на исходных данных те же приемы ускорили бы работу раза в два.
Приемы универсальны для реляционных баз, а во всю мощь раскрываются на объемах от миллиона клиентов. Советы пригодятся тестировщикам, внедренцам enterprise-продуктов, системным интеграторам-аналитикам.
Но сначала — об одном из главных мифов системной интеграции.
Документация и архитектор помогут (на самом деле нет)
Интеграторы часто не изучают данные перед миграцией — экономят время. Читают документацию, смотрят на структуру, беседуют с архитектором — и хватит. После этого уже планируют интеграцию.
Только анализ покажет, что́ реально творится в базе. Выходит скверно. Если не залезть в данные с засученными рукавами и увеличительным стеклом, миграция пойдет наперекосяк.
Все эти годы изменения в ней документируют самые разные подразделения и подрядчики. Документация врет. Типичная enterprise-система работает 5–20 лет. Поэтому целостности в документации нет, никто до конца не понимает логику и структуру хранения данных. Каждый со своей колокольни. Не говоря о том, что сроки вечно горят и на документирование не хватает времени.
Но когда я смотрю в данные, то вижу — поле пустое. Обычная история: в таблице клиентов есть поле «СНИЛС», на бумаге очень важное. В итоге заказчик соглашается, что целевая база обойдется без поля для СНИЛС, раз данных все равно нет.
Все это тоже не поможет. Частный случай документации — регламенты и описания бизнес-процессов: как данные попадают в базу, при каких обстоятельствах, в каком формате.
Под окном всю ночь орали, а с утра Анатолий поругался с девушкой. Бизнес-процессы безупречны лишь на бумаге. Ранним утром в оперофис банка на окраине Выксы заходит невыспавшийся оператор Анатолий. Он ненавидит весь мир.
Про день рождения начисто забывает — в форме остается дефолтное «01. Нервы еще не пришли в порядок, и Анатолий целиком вбивает ФИО нового клиента в поле для фамилии. 1900 г». 01. Поэтому хаос побеждает бизнес-процессы, очень стройные на бумаге. Наплевать на регламенты, когда все вокруг так бесит!!!
За годы, что они работают, архитекторы меняются. Системный архитектор знает не все. Дело снова в почтенном сроке жизни enterprise-систем. Даже если поговорить с действующим, решения предыдущих всплывут сюрпризами во время проекта.
И будьте уверены: даже приятный во всех отношениях архитектор сохранит в тайне свои факапы и костыли системы.
Я покажу, как мы в HFLabs изучаем данные при системной интеграции. Интеграция «по приборам», без анализа данных — ошибка. Но когда заказчик выдает доступ к исходным данным, их обязательно проверяю по тем же принципам. В последнем проекте я анализировала только выгрузки из ETL.
Заполненность полей и null-значения
Самые простые проверки — на заполненность таблиц в целом и на заполненность отдельных полей. С них и начинаю.
Сколько всего заполненных строк в таблице. Самый простой запрос из возможных.
select count(*) from <table>;
Получаю первый результат.
Физические лица
Количество
Всего
99 966 324
Здесь смотрю на адекватность данных. Если в выгрузке для крупного банка пришло только два миллиона клиентов, явно что-то не так. Но пока все выглядит ожидаемо, двигаюсь дальше.
Сколько строк заполнены по каждому полю отдельно. Проверяю все столбцы таблицы.
select <column_name>, count(*) as <column_name> cnt from <table> where <column_name> is not null;
Первым попалось поле с днем рождения, и сразу любопытно: данные почему-то вообще не пришли.
Физические лица
Количество
Всего
99 966 324
ДР
0
Если в выгрузке все значения в поле — «NULL», первым делом смотрю в исходную систему. Возможно, там данные хранятся исправно, но их потеряли при миграции.
Иду к интеграторам: ребята, ошибка. Вижу, что в системе-источнике дни рождения на месте. Код поправили, в следующей выгрузке проверим изменения. Выяснилось, что в ETL-процессе неправильно отработала функция «decode».
Иду дальше, к полю с ИНН.
Физические лица
Количество
Всего
99 966 324
ДР
0
ИНН
65 136
В базе 100 миллионов человек, а ИНН заполнены только у 65 тысяч — это 0,07%. Такая слабая заполненность — сигнал, что поле в базе-приемнике, быть может, не нужно вовсе.
Значит, дело не в миграции. Проверяю систему-источник, все верно: ИНН похожи на актуальные, но их почти нет. Осталось выяснить, нужно ли заказчику в целевой базе почти пустое поле под ИНН.
Добралась до флага удаления клиента.
Физические лица
Количество
Всего
99 966 324
ДР
0
ИНН
65 136
Флаг удаления
0
Флаги не заполнены. Это что же, компания не удаляет клиентов? Смотрю в исходную систему, разговариваю с заказчиком. Выходит, что да: флаг формальный, вместо удаления клиентов удаляют их счета. Нет счетов — клиента как бы удалили.
Значит, если у клиента ноль счетов в системе-приемнике, его нужно закрыть через дополнительную логику или вовсе не импортировать. В целевой же системе флаг удаленного клиента обязателен, это особенность архитектуры. Тут уж как заказчик решит.
Обычно в таких таблицах что-то не так, потому что адреса — штука сложная, вводят их по-разному. Дальше — табличка с адресами.
Проверяю заполненность составляющих адреса.
Адреса
Количество
Всего
254 803 976
Страна
229 256 090
Индекс
46 834 777
Город
6 474 841
Улица
894 040
Дом
20 903
Адреса заполнены неоднородно, но выводы делать рано: сначала спрошу у заказчика, для чего они нужны. Если для сегментации по странам, все отлично: данных достаточно. Если для почтовых рассылок, тогда проблема: дома́ почти не заполнены, квартир нет.
Она в базе как памятник. В итоге заказчик увидел, что ETL брал адреса из старой и неактуальной таблички. А есть другая таблица, новая и хорошая, данные нужно брать из нее.
Условие «IS NOT NULL» с ними не работает: вместо «NULL» в ячейке обычно «0». Во время анализа на заполненность я особняком ставлю поля, ссылающиеся на справочники. Поэтому поля-справочники проверяю отдельно.
Нашла проблемы, интеграторы исправили ETL-процесс и снова запустили миграцию. Изменения заполненности полей. Итак, я проверила общую заполненность и заполненность каждого поля.
Статистику записываю в тот же файл, чтобы видеть изменения. Вторую выгрузку прогоняю по всем шагам, перечисленным выше.
Заполненность всех полей.
Физические лица
Выгрузка 1
Выгрузка 2
Дельта
Всего
99 966 324
94 847 160
-5 119 164
Между выгрузками исчезли 5 миллионов записей. Иду к интеграторам, задаю типовые вопросы:
- «Почему потерялись записи?»;
- «Какие данные отсеяли?»;
- «Какие данные оставили?»
Выясняется, что проблемы нет: из свежей выгрузки просто убрали «технических» клиентов. Они в базе для тестов, это не живые люди. Но с той же вероятностью данные могли пропасть по ошибке, такое бывает.
А вот дни рождения в новой выгрузке появились, как я и ожидала.
Физические лица
Выгрузка 1
Выгрузка 2
Дельта
Всего
99 966 324
94 847 160
-5 119 164
ДР
0
77 046 780
77 046 780
Но! Не обязательно хорошо, когда в новой выгрузке вдруг появились ранее отсутствующие данные. Например, дни рождения могли заполнить дефолтными датами — радоваться тут нечему. Поэтому я всегда проверяю, какие данные пришли.
Что проверять, в двух словах.
- Общее количество записей в таблицах. Адекватно ли ожиданиям это количество.
- Количество заполненных строк в каждом поле.
- Соотношение количества заполненных строк в каждом поле к количеству строк в таблице. Если оно слишком мало, это повод подумать, нужно ли тащить поле в целевую базу.
Повторять первые три шага для каждой выгрузки. Следить за динамикой: где и почему прибавилось или убавилось.
Длина значений в строковых полях
Я следую одному из базовых правил тестирования — проверяю граничные значения.
Какие значения слишком короткие. Среди самых коротких значений полно мусорных, поэтому здесь интересно копнуть.
select * from <table> where length (<column_name>) < 3;
Таким способом я проверяю ФИО, телефоны, ИНН, ОКВЭД, адреса сайтов. Всплывает бессмыслица вроде «A*1», «0», «11», «-» и «...».
MySQL откалывает такое лихо и без предупреждений. Все ли в порядке с максимальными значениями. Заполненность поля впритык — маркер того, что при переносе данные не влезли, и их автоматом обрезали. При этом кажется, что миграция прошла гладко.
select * from <table_name> where length(<column_name>) = 65;
Таким способом я нашла в поле с типом документа строку «Свидетельство о регистрации ходатайства иммигранта о признании ег». Рассказала интеграторам, длину поля поправили.
Как значения распределяются по длине. В HFLabs таблицу распределения строк по длине мы называем «частотка».
select length(<column_name>), count(<column_name>) from <table> group by length(<column_name>);
Здесь я выискиваю аномалии в распределении по длине. Например, вот частотка для таблицы с почтовыми адресами.
Длина
Количество
122
120
123
90
124
130
125
1100
126
70
Значений с длиной 125 чересчур много. Смотрю в базу-источник и нахожу, что три года назад часть адресов почему-то обрезали до 125 символов. В остальные годы все нормально. Иду с этой проблемой к заказчику и интеграторам, разбираемся.
Что проверять, в двух словах.
- Самые короткие значения в строковых полях. Часто строки меньше трех символов — это мусор.
- Значения, которые «упираются» по длине в ширину поля. Часто они обрезаны.
- Аномалии в распределении строк по длине.
Популярные значения
Я делю на три категории значения, попадающие в топ популярных:
- реально распространенные, как имя «Татьяна» или отчество «Владимирович». Здесь нужно помнить, что в общем случае «Татьяна» не должна быть в 100 раз популярнее, чем «Анна», а «Исмаил» едва ли может быть популярнее, чем «Егор»;
- мусорные, вроде «.», «1», «-» и тому подобных;
- дефолтные на форме ввода, как «01.01.1900» для дат.
Два случая из трех — маркеры проблемы, полезно их поискать.
Популярные значения я ищу в полях трех типов:
- Обычных строковых полях.
- Строковых полях-справочниках. Это обычные строковые поля, но количество различных значений в них конечно и регламентировано. В таких полях хранят страны, города, месяцы, типы телефонов.
- Полях-классификаторах — в них стоит ссылка на запись в сторонней таблице-классификаторе.
Поля каждого из этих типов изучаю немного по-разному.
Для строковых полей — каковы топ-100 популярных значений. Если хочется, можно взять и побольше, но в первые сто значений обычно помещаются все аномалии.
select * from (select <column_name>, count(*) cnt from <table> group by <column_name> order by 2 desc) where rownum <= 100;
Я проверяю таким способом поля:
- ФИО целиком, а также отдельно фамилии, имена и отчества;
- даты рождения и вообще любые даты;
- адреса́. Как полный адрес, так и отдельные его составляющие, если они хранятся в базе;
- телефоны;
- серию, номер, тип, место выдачи документов.
Почти всегда среди популярных — тестовые и дефолтные значения, какие-то заглушки.

Однажды я нашла в базе подозрительно популярный номер телефона. Бывает, что найденная проблема — и не проблема вовсе. Оказалось, что этот номер клиенты указывали как рабочий, а в базе просто много сотрудников одной организации.
Этим полям по логике вроде как не положено быть справочниками, но фактически в базе они таковыми являются. Попутно такой анализ покажет скрытые поля-справочники. Например, выбираю популярные значения из поля «Должность», а их всего пять.
Должность
Директор
Бухгалтер
Специалист
Секретарь
Системный администратор
Возможно, компания обслуживает только пять профессий. Не очень похоже на правду, верно? Скорее, в форме для операторов вместо строки сделали справочник и забыли отсыпать значений. Важный вопрос здесь: разумно ли вообще заполнять должности через справочник. Так через анализ данных я выхожу на возможные проблемы с операторским софтом.
Скриптами здесь не обойтись, беру документацию и прикидываю. Для полей-справочников и классификаторов проверяю, какова популярность всех значений. Для начала разбираюсь, какие поля — справочники. Обычно справочники создают для значений, число которых конечно и относительно невелико:
- страны,
- языки,
- валюты,
- месяцы,
- города.
В идеальном мире содержание полей-справочников четко и единообразно. Но наш мир не таков, поэтому проверяю запросом.
select <column_name>, count(*) cnt from <table> group by <column_name> order by 2 desc;
Обычно в строковых-полях справочниках лежит такое.
Место рождения
Количество
таджикистан
467 599
Таджикистан
410 484
Россия
292 585
ТАДЖИКИСТАН
234 465
россия
158 163
РОССИЯ
76 367
Типичные проблемы:
- опечатки;
- пробелы;
- разный регистр.
Обнаружив беспорядок, иду к интеграторам с примерами на руках. Пусть они оставят мусор в источнике, а разночтения устранят. Тогда в целевой базе для строгости можно будет превратить строки-справочники в классификаторы.
Сталкивалась с такими случаями.
Популярные значения в полях-классификаторах я проверяю, чтобы отловить недостаток вариантов.
Пол
Тип телефона
- Женский
- Не определен
- Домашний
Выглядят такие классификаторы очень странно, их стоит показать заказчику. У меня каждый раз за такими случаями крылась ошибка: или в базе что-то не так, или данные загрузили не оттуда.
Что проверять, в двух словах.
- Какие строковые поля справочные, а какие — нет.
- Для простых строковых полей — топ популярных значений. Обычно в топе мусор и дефолтные данные.
- Для строковых полей-справочников — распределение всех значений по популярности. Выборка покажет разночтения в справочных значениях.
- Для классификаторов — достаточно ли вариантов в базе.
Консистентность и кросс-сверки
От анализа данных внутри таблиц перехожу к анализу связей.
Беру подчиненную таблицу, например, с телефонами. Связаны ли данные, которым положено быть связанными. Этот параметр мы называем «консистентность». И смотрю, сколько в подчиненной таблице айдишников клиентов, которых нет в родительской. К ней в пару — родительскую таблицу клиентов.
select count(*) from ((select <ID1> from <table1>) minus (select <ID2> from <table2>));
Если запрос дал дельту, значит, не повезло — в выгрузке есть несвязанные данные. Так я проверяю таблицы с телефонами, договорами, адресами, счетами и так далее. Однажды во время проекта нашла 23 миллиона номеров, просто висевших в воздухе.
Иногда это нормально — ну нет адреса у клиента, что такого. В обратную сторону тоже работает — ищу клиентов, у которых почему-то нет ни одного договора, адреса, телефона. Здесь нужно выяснять у заказчика, документация запросто обманет.
Например, разнополых клиентов. Нет ли дублирования первичных ключей в разных таблицах. Иногда одинаковые сущности хранят в разных таблицах. (Никто не знает, зачем, потому что структуру утверждал еще Брежнев.) А в приемнике таблица единая, и при миграции айдишники клиентов будут конфликтовать.
Это могут быть таблицы клиентов, контактных телефонов, паспортов и так далее. Я включаю голову и смотрю на структуру базы: где возможно дробление схожих сущностей.
Пересекаются — клеим заплатку. Если таблиц со схожими сущностями несколько, делаю кросс-сверку: проверяю пересечение идентификаторов. Например, собираем айдишники для единой таблицы по схеме «название исходной таблицы + ID».
Что проверять, в двух словах.
- Сколько в связанных таблицах несвязанных данных.
- Нет ли потенциальных конфликтов первичных ключей.
Что еще проверить
Нет ли латинских символов там, где им не место. Например, в фамилиях.
select <column_name> from <table> where regexp_like(<column_name>, ’[A-Z]’, ’i’);
Так я отлавливаю замечательную латинскую букву «C», которая совпадает с кириллической. Ошибка неприятная, потому что по ФИО с латинской «C» оператор никогда не найдет клиента.
Не затесались ли посторонние символы в строковые поля, предназначенные для цифр.
select <column_name> from <table> where regexp_like(<column_name>, ‘[^0-9]’);
Проблемы всплывают в полях с номером паспорта РФ или ИНН. Телефоны — то же самое, но там я разрешаю плюс, скобки и дефис. Запрос выявит и букву «O», которую поставили вместо нуля.
Встречала такие случаи: Насколько данные адекватны. Никогда не знаешь, где всплывет проблема, поэтому я всегда настороже.
- 50 000 телефонов у клиента «Софья Владимировна» — это нормально? Ответ: не нормально. Клиент технический, на него повесили «бесхозные» телефонные номера, чтобы делать sms-рассылки. Тянуть клиента в новую базу не нужно;
- ИНН заполнены, на поверку в столбце лежит «79853617764», «89109462345», «4956780966» и так далее. Что за телефоны, окуда? Где ИНН? Ответ: что за номера — неизвестно, кто положил — непонятно. Никто их не использует. Актуальный ИНН хранят в другом поле другой таблицы, забирать оттуда;
- поле «адрес одной строкой» не соответствует полям, в которых адрес хранится по частям. Почему адреса разные? Ответ: когда-то операторы заполняли адреса одной строкой, а внешняя система разобрала адреса по отдельным полям. Для сегментации. Шло время, люди меняли адреса. Операторы их исправно обновляли, но только в виде строки: адрес частями остался старый.
Все, что нужно — SQL и Excel
Чтобы анализировать данные, дорогое ПО не нужно. Хватает старого доброго Excel и знания SQL.
Например проверяю поля на заполненность, а в таблице их 140. Excel я использую, чтобы собрать длинный запрос. Писать руками буду до морковкиного заговения, поэтому собираю запрос формулами в excel-табличке.
В колонке «B» — формула для склеивания запроса 
В столбец «A» вставляю названия полей, беру их в документации или служебных таблицах.
Вставляю названия полей, пишу первую формулу в колонке «B», тяну за уголок — и готово.
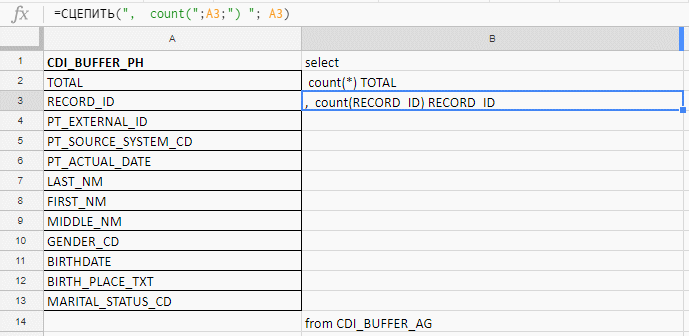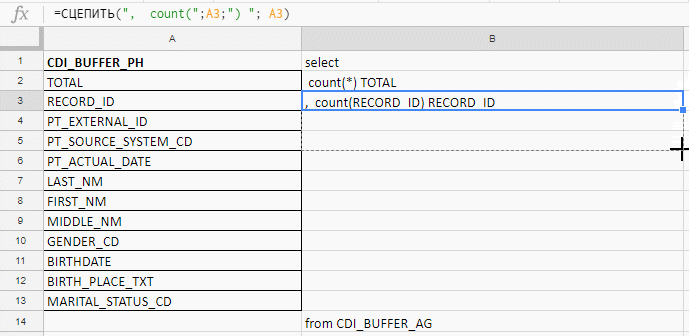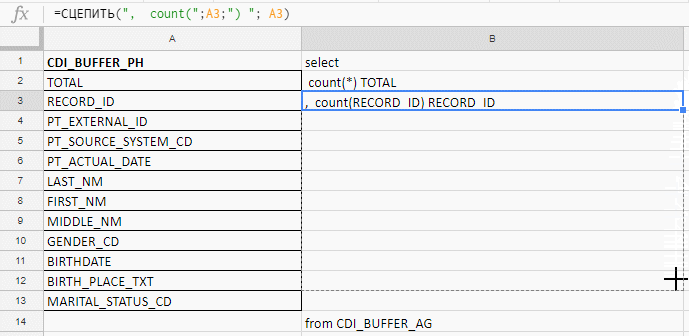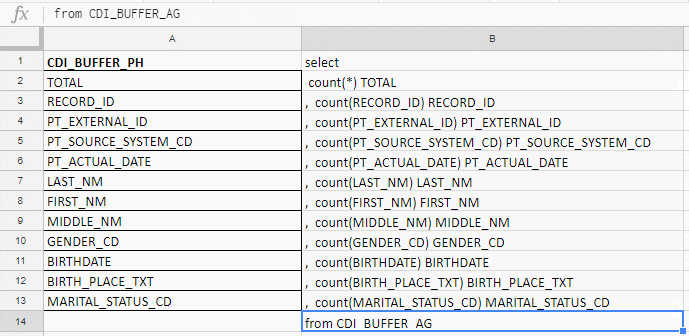
Работает и в Excel, и в Google Docs, и в «Яндекс.Таблицах»
С ним проще уложиться в дедлайн. Анализ данных экономит вагон времени и спасает нервы менеджеров. Если проект крупный, аналитика сохранит миллионы рублей и репутацию.
Не цифры, а выводы
Сформулировала для себя правило: не показывать заказчику голые числа, эффекта все равно не добьешься. Моя задача — проанализировать данные и сделать выводы, а числа приложить как доказательство. Выводы — первичны, числа — вторичны.
Что я собираю для отчета:
- формулировки проблем в виде гипотезы или вопроса: «ИНН заполнены на 0,07%. Как вы используете эти данные, насколько они актуальны, как их трактовать? Только ли в одной таблице лежат ИНН?». Нельзя обвинять: «У вас ИНН не заполнены вообще». В ответ получишь только агрессию;
- примеры проблем. Это таблички, которых так много в статье;
- варианты, как можно сделать: «Возможно, стоит убрать ИНН из целевой базы, чтобы не плодить пустые поля».
Я не имею права решать, что именно забирать из исходной базы и как менять данные при миграции. Поэтому с отчетом я иду к заказчику или интеграторам, и мы выясняем, как дальше быть.
Закупим лишний терабайт памяти, да и все. Иногда заказчик, увидев проблему, отвечает: «Не парьтесь, не обращайте внимания. Соглашаться на такое нельзя: если забирать все подряд, качества в приемнике не будет. Так дешевле, чем оптимизировать». Мигрируют все те же замусоренные избыточные данные.
Не «зачем нужны», а именно «как будете использовать». Поэтому мы мягко, но неуклонно просим: «Расскажите, как будете использовать именно эти данные в целевой системе». Рано или поздно заказчик понимает, без каких данных можно обойтись. Ответы «потом придумаем» или «это на всякий случай» не годятся.
На живую менять архитектуру и модель данных — с ума сойдешь. Главное — найти и разрешить все вопросы, пока систему не запустили в прод.
С базовой аналитикой на этом все, изучайте данные!
Подходящего человека научим всему, о чем я рассказала в статье, и другим премудростям. HFLabs ищет аналитика-стажера с зарплатой от 50 000 ₽.
Если интересно, присылайте отклики со страницы вакансии на hh.ru. Вакансия подойдет технарям, которые хотят сменить профиль или еще не определились, в какой сфере работать.






