
В инвестировании есть понятие «Плохо сейчас — хорошо потом». Инвестор регулярно отщипывает 10, 20% или даже 30% своего заработка на будущее. Эти деньги он инвестирует в облигации, акции, ОФЗ, ETF — кто во что горазд. Сейчас, в моменте, инвестор отбирает у себя свой заработок, лишает себя каких-то благ, чтобы в будущем, на горизонте в 10-20 лет, получить пользу от инвестиций. Прибыль в будущем покроет сегодняшние лишения. Примерно такую же стратегию исповедует Алексей Охрименко (obenjiro), но применительно к разработке — лучше день потерять, а потом за 5 минут полететь.

Источник
Этот доклад не о чувстве скуки и не о том, как бороться с монотонными и рутинными задачами, а о том как потратить время по максимуму — сколько есть, все потратить, и посмотреть, что из этого получится. На Frontend Conf 2018 Алексей рассказал, как потеряв кучу времени сейчас, в конечном счете его сэкономить потом. Бонусом Алексей расскажет о ряде уже существующих инструментов и о пользе, которую они приносят. В расшифровке доклада опыт написания инструментов для отладки, тестирования, оптимизации, скафолдинга и валидации под разные проекты. Давайте выяснять, надо ли вообще на это тратить время.
Ведет подкаст «5 min Angular», а в свободное ото сна и подкаста время организует Angular Meetup вместе с ребятами из Тинькофф, и выступает с огромным количеством разных и спорных докладов.
О докладчике: Алексей Охрименко — разработчик в Avito Frontend Architecture, где немного улучшает жизнь миллионов людей.
Где можно потерять время?
Нулевой шаг — купить Mac/iMac и тут же начать терять время, или поставить Linux на ноутбук и потерять в нем вообще все рабочее время, меняя конфиги. Также очень рекомендую начать с Gentoo.
Есть 8 пунктов, на которые мы можем потратить время.
- Терминал.
- Проектирование.
- Создание проекта.
- Кодогенерация.
- Написание кода.
- Рефакторинг.
- Тестирование.
- Отладка.
Приступим к основательной потере начав по порядку.
Терминал
Где на терминале можно потратить наше время, чтобы потерять все? Организуйте рабочее пространство — создайте папки «Моя работа», «Мои хобби-проекты» и раскладывайте все в них. Поставьте себе Homebrew, чтобы устанавливать дополнительный софт, который еще будет упомянут.

Поставьте iTerm2, а дефолтный терминал на Mac — выкиньте.

Поставьте дополнения, например, oh-my-zsh, которые идут вместе с набором очень крутых плагинов.
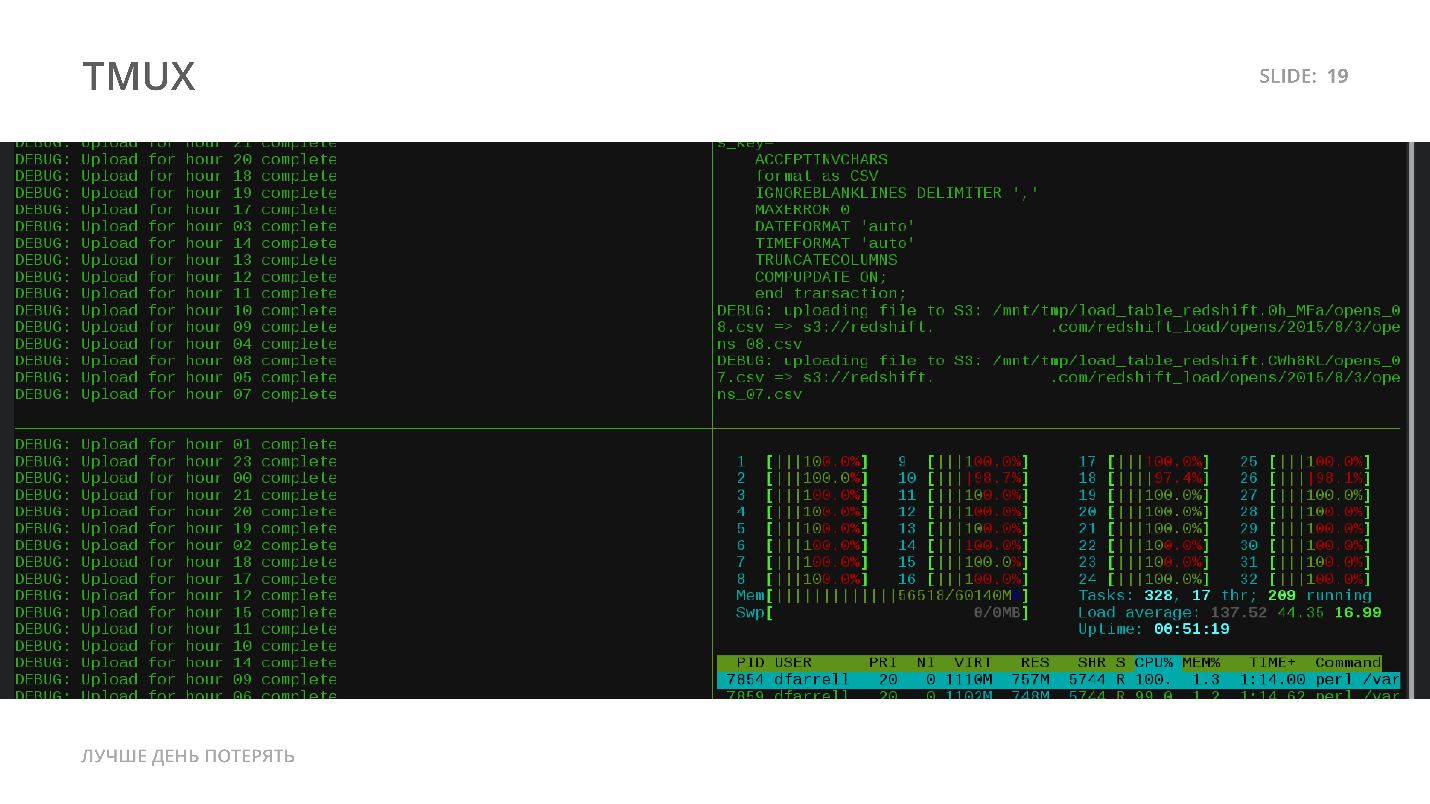
Это программа для терминала, которая позволяет в одном окне открыть несколько окон и дополнительно поддерживать сессию. Поставьте tmux — terminal multiplexer. Если не разу с tmux не работали — рекомендую обзор от Студии DBMS. Обычно, если вы закрыли терминал, все ломается и заканчивается, а tmux будет продолжать работать, даже если вы все выключили.
Каждый раз, когда в терминале вы написали что-то больше одного раза — напишите себе alias, пригодится. Прописывайте aliases. Два раза — уже много, обязательно будет третий, шестой и десятый.

Его можно установить через brew и делать интересные query-запросы в JSON-файлы. Поставьте дополнительные инструменты, например, jmespath или сокращенно — jp.
brew tap jmespath/jmespath
brew instal jp
К примеру, у вас лежат packed JSON-файлы, вы можете по всем пройтись и узнать какие версии React в ваших приложениях и проектах.

Автоматизируйте свою работу — не открывайте одни и те же файлы много раз!
А теперь поговорим куда это все потратить. Все, что выше — это небольшая потеря времени, потерять больше можно в Shell Scripts.
Shell Script
Это язык программирования, в основном для bash, со своим синтаксисом.
#!/bin/bash
for dir in ‘ls $YOUR_TOP_LEVEL_FOLDER’;
do
for subdir in ’Is $YOUR_TOP_LEVEL_FOLDER/$dir’
do
$(PLAY AS MUCH AS YOU WANT); done
done
Язык полноценный — некоторые люди создают игры и веб-серверы, что делать не советую. Я рекомендую всю работу, на которую затратили время, потратить еще раз и написать все это полноценно в файле. Зачем? Все знакомые девелоперы, которые давно работают в индустрии, просто создают себе свой GitHub репозиторий для конфигураций, и размещают туда конфигурацию для своего TMUX — terminal multiplexer, Shell Scripts для инициализации.
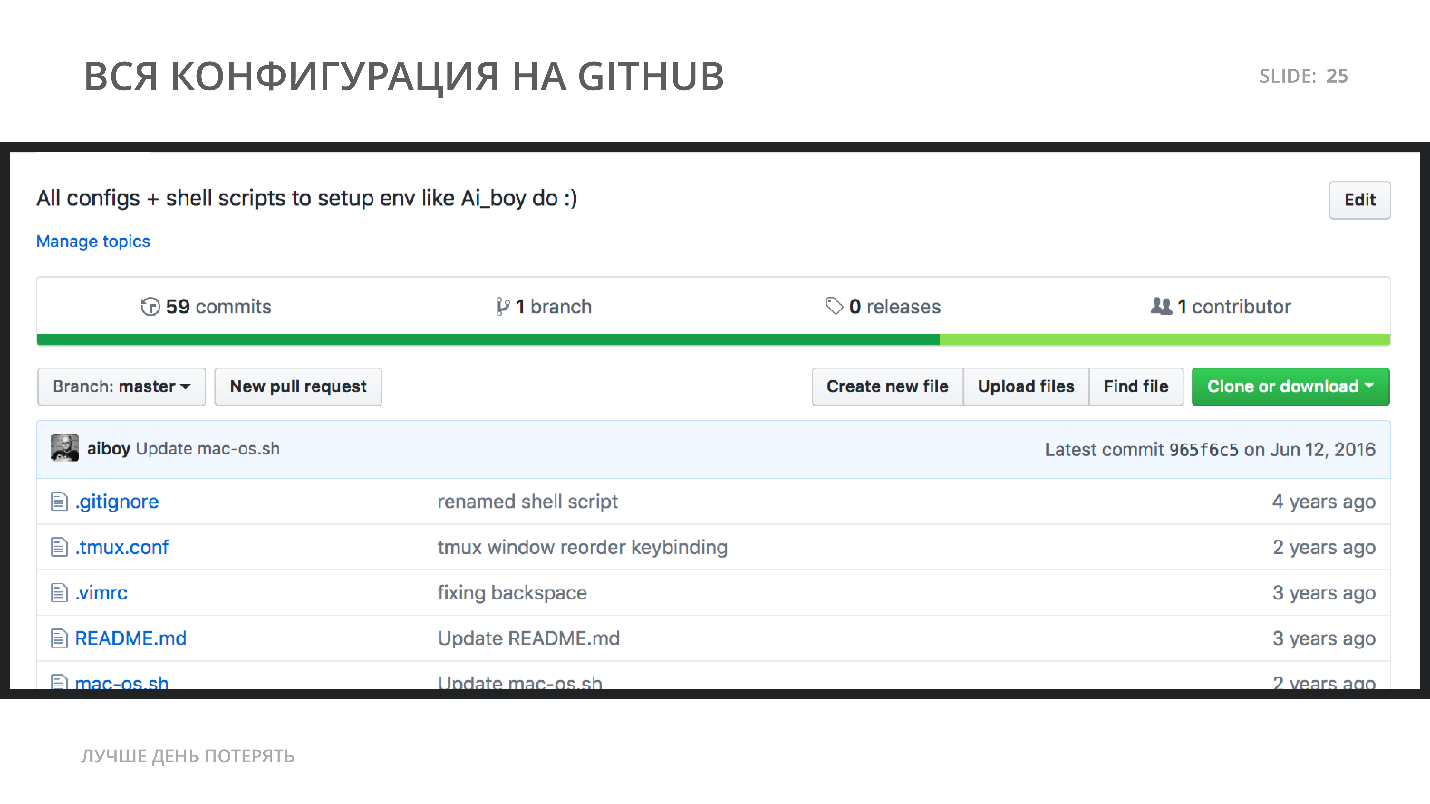
Затем, что вы перейдете на другую работу, вам поменяют компьютер на работе, сгорит материнская плата и вы будете снова тратить день-два-три, чтобы настроить environment. Зачем тратить еще кучу времени на то, что уже один раз сделано? Когда у вас есть такой репозиторий, настройка и установка всего займет 10 минут.
Проектирование
Обычно все сразу очень воодушевлены: «Да, проектирование! UML-диаграммы!», но когда я говорю слово UML вслух, многие знакомые программисты замечают:
Что с тобой? — В 2018?! Зачем ты откапываешь труп? UML — это страшный пережиток прошлого. Брось лопату!
Например, на Scrum-митинге Java-разработчик слушает, как Python-программисты обсуждают архитектуру бэкенд-фичи. Но UML очень полезен. Java-разработчик не может взаимодействовать с Python-программистами — не скажет, как писать код, использовать классы, миксины или что-то еще. Он грустно потирает голову и понимает, что ничего не понимает, а просто теряет час своего времени. В нашей компании есть JavaScript, Python и Lua. Он просто не участвует в деле. Эту проблему решает UML. В моменте 2/3 людей скучают: сначала одни 2/3, потом другие.
UML — это универсальный абстрактный визуальный язык для проектирования систем, который позволяет игнорировать особенности языков.
Приведу два моих любимых примера.
Sequence Diagrams
Эти диаграммы помогают показать историю взаимодействия во времени.
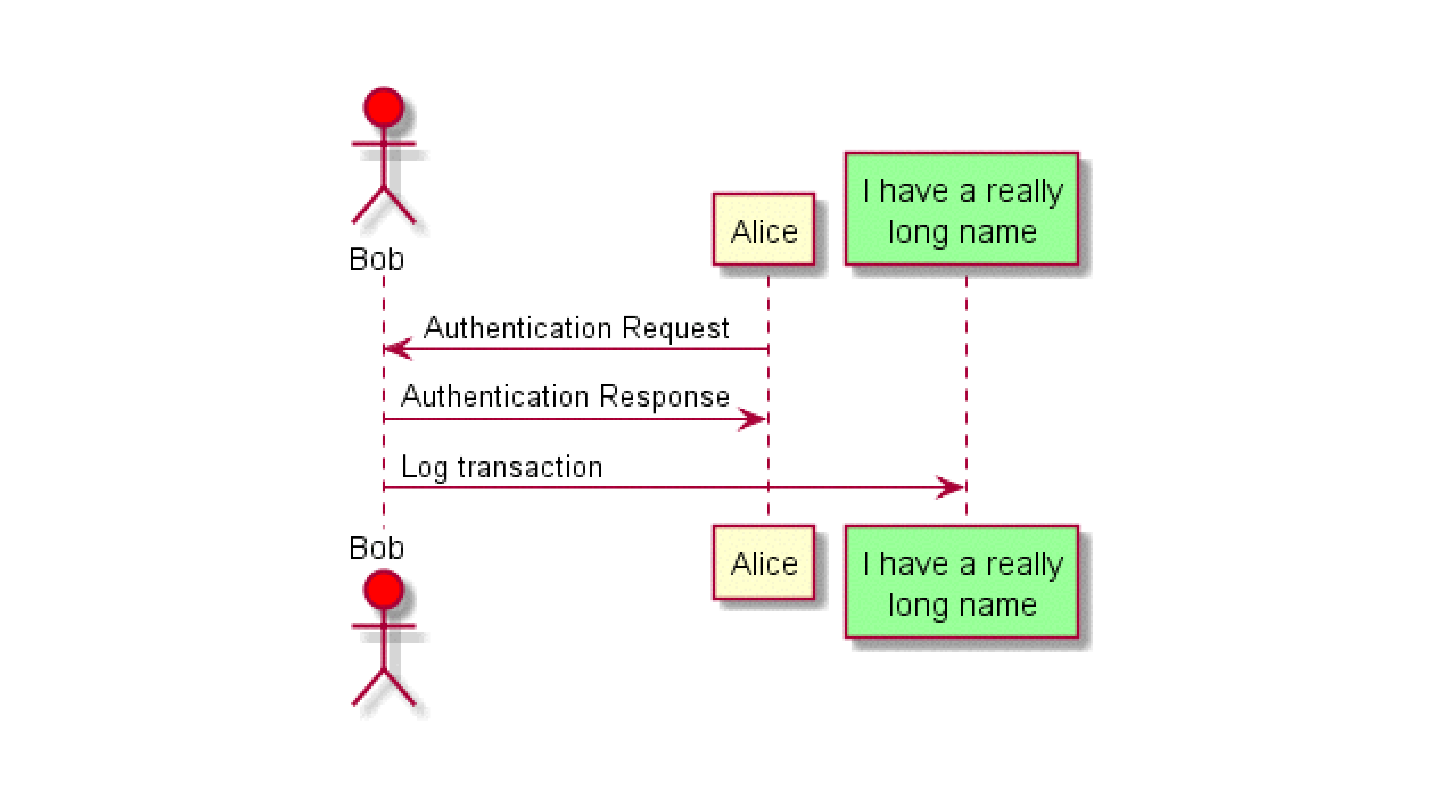
По горизонтальной оси X происходит уже непосредственное взаимодействие между героями — участниками какого-то события. По вертикальной оси Y вниз идет временная зависимость: сначала получаем запрос на аутентификацию, потом даем ответ, и дальше кладем что-то в логи.
При этом я, JS-разработчик, нахожу общий язык с бэкендом Python, Lua и Java. Лично я периодически использую Sequence Diagrams для описания аутентификации процесса в приложениях. Мы все друг друга понимаем и знаем, как в результате будет работать код, и не заморачиваемся по поводу конкретной реализации того или иного языка.
Class Diagram
Эти диаграммы тоже очень полезны. В JavaScript есть классы, в чем смысл диаграмм? Но есть же TypeScript, и с его помощью можно получить интерфейсы, абстрактные классы — полноценное представление конечной архитектуры.

Минута проектирования экономит неделю кодинга.
PlantUML
Я пользуюсь Java-библиотекой PlantUML. С ней вы можете использовать некий непростой dsl, в котором указать, к примеру, что List наследуется от AbstractList, Collection — от AbstractCollection, а также взаимодействие, агрегирование, свойства, интерфейсы и все остальное.
@startuml
abstract class AbstractList abstract AbstractCollection interface List interface Collection
List <|— AbstractList Collection <|— AbstractCollection
Collection <|— List AbstractCollection <|— AbstractList AbstractList <|— ArrayList
class ArrayList {
Object[ ] elementData size()
}
enum TimeUnit {
DAYS
В результате получу конечную диаграмму.
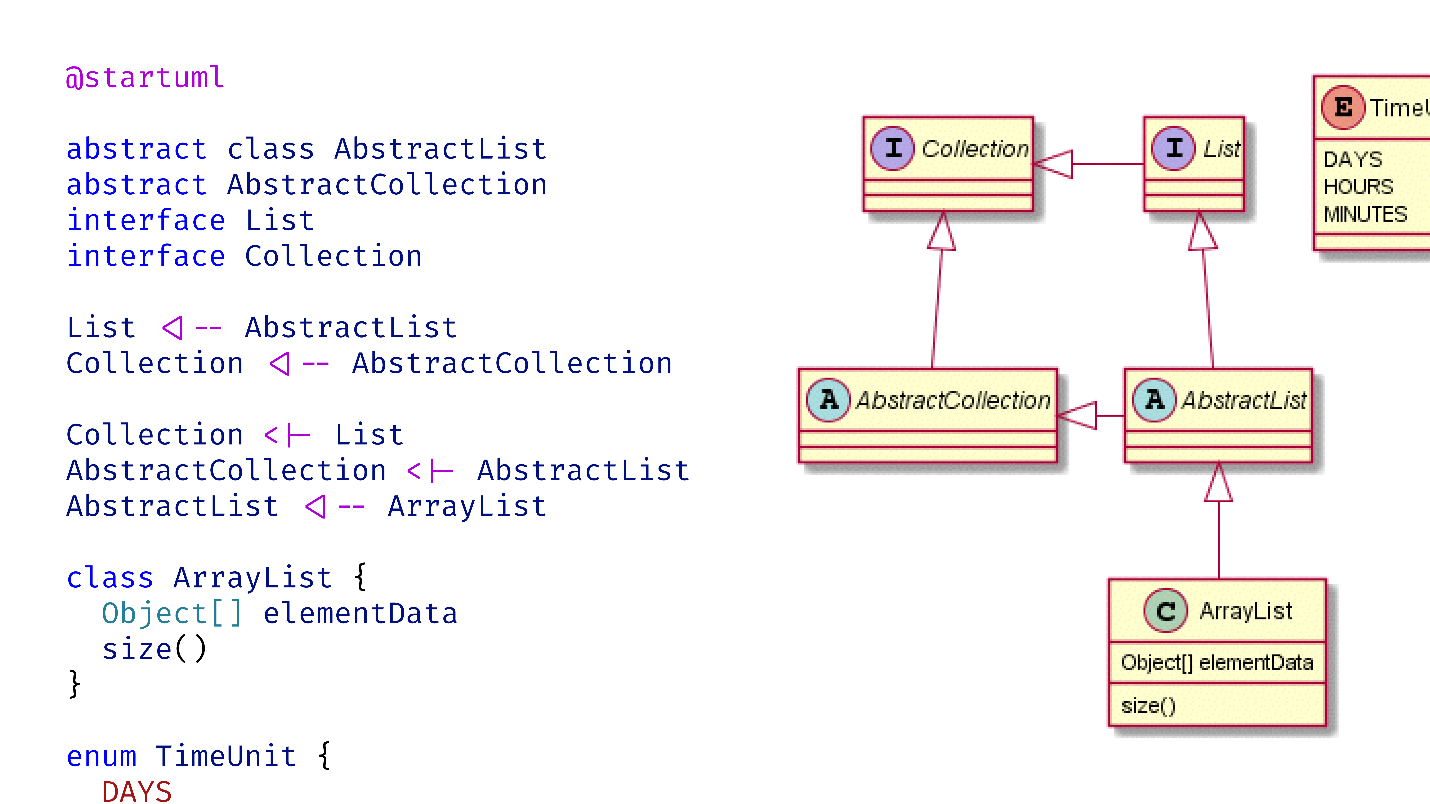
Все это работает хорошо, есть плагины для Visual Studio Code.
Есть еще одно интересное приложение.
StarUML
Мы рисуем простейшую диаграмму: здесь есть базовый класс, от которого наследуется тестовый класс.
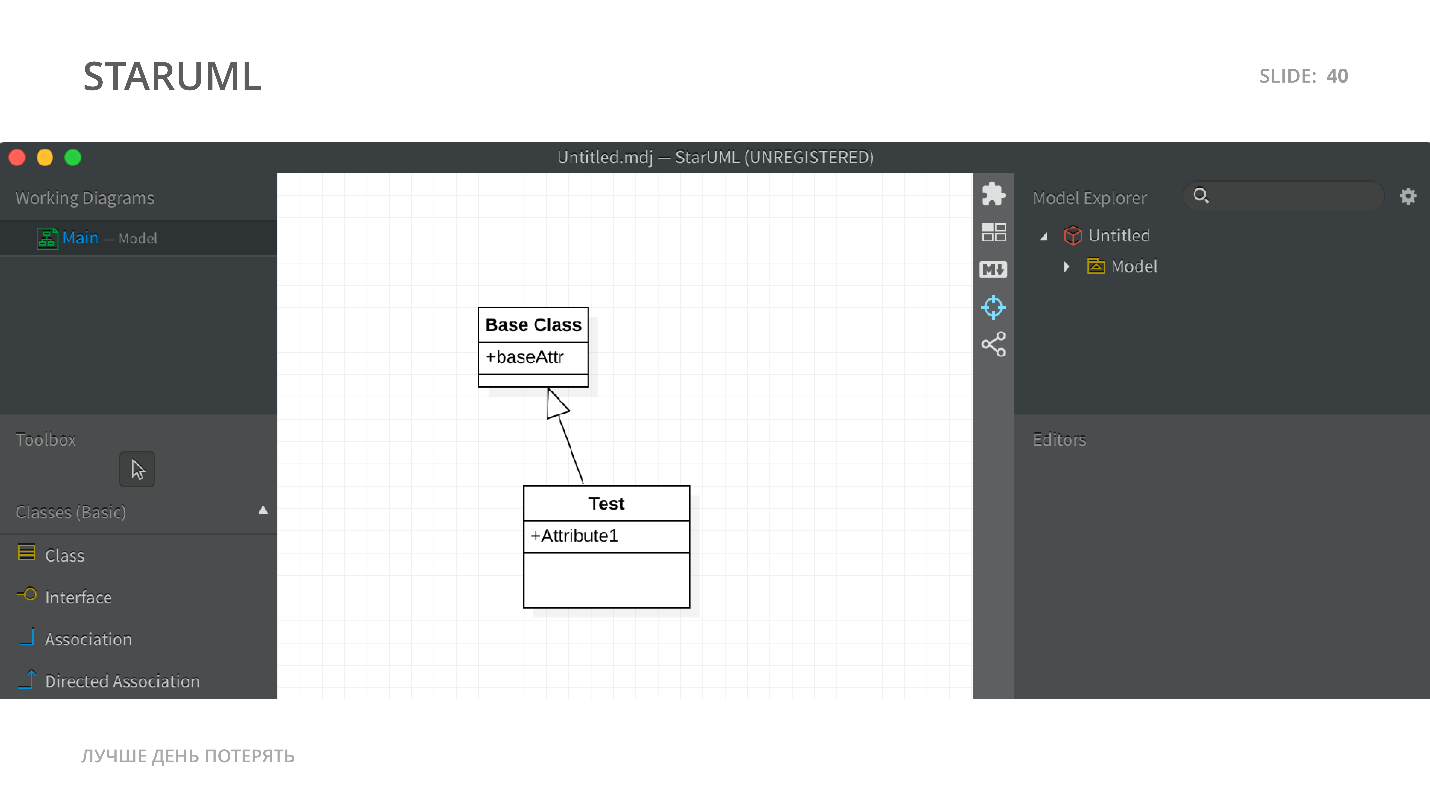
Он стоит не слишком дорого и умеет экспортировать в Java. Дальше используем StarUML. Инструмента, который бы UML-диаграммы экспортировал в TypeScript-код, нет, но мы можем экспортировать как раз с помощью StarUML в Java-код.

JSweet
Потом применим JSweet — библиотеку, которая позволяет конвертировать Java-код в TypeScript или JavaScript-код.

Java-код…
import java.until.*;
/**
*
*/
public class BaseClass {
/**
* Default constructor */
public BaseClass(){
}
/**
* some attribute */
protected String baseAttribute;
}
… с помощью JSweet конвертируем в TypeScript-код:
/* Generated from Java with JSweet 2.0.0 — <a href="http://www.jsweet.org/">http://www.jsweet.org</a> */ /**
* Default constructor
* @class */
class BaseClass {
public constructor) {
this.baseAttribute = null;
}
/**
* some attribute */
baseAttribute : string;
}
BaseClass["_class«] = «BaseClass»;
Здесь есть дополнительный параметр _class — это особенность работы Java, подобное можно удалять. В результате мы получили готовый boilerplate TypeScript-кода из диаграмм — базу, на которой можно работать. Причем эта база спроектирована и ясна всем.
Тратить время на проектирование UML однозначно стоит.
Создание проекта
Кто конфигурирует Webpack каждый раз и создает webpack-config в новом проекте — ребята, что с вами?! Все хорошо? Вам нужна помощь? Если вас держат в заложниках — напишите координаты в комментариях, мы вышлем вертолет спасения.
Самый простой способ избежать подобного и каждый раз не конфигурировать одно и то же — это создать общий репозиторий на GitHub локально или поднять GitLub CI, склонировать этот репозиторий, зайти в него и удалить папку git.
git clone something
cd something
rm -rf .git
Теперь у нас есть эталонный проект, из которого клонируем. Таким подходом можно получить очень дешевый Bootstrapping.
Yeoman — deprecated. Slush — deprecated
То, что Yeoman deprecated — слишком самоуверенно. Он не deprecated, просто его все меньше и меньше используют, как и Slush. Это два одинаковых инструмента, просто с разной базой: Yeoman — это Grunt и кодогенерация. Slush — это Galp и кодогенерация.
Несмотря на то, что инструменты интересные, сейчас чаще используются другие.
Angular CLI, Create React App, Vue CLI
Кто работает с Angular — используют Angular CLI. Create React App — кто работает с React. Vue CLI — любители Vue.JS.
Один из главных аргументов, почему стоит работать именно с CLI — это унифицированность. Большинство уже пересели на эти инструменты. Эти инструменты очень хороши. Если вы забудстрэппили ваш проект с помощью CLI, то уверены, что человек, который придет после вас, будет знать структуру проекта: команды, фичи, что можно запускать end-to-end и юнит тесты.
Да, не сомневайтесь. Стоит ли тратить время на bootstrapping проектов именно с помощью CLI, а не Yeoman?
Кодогенерация
У нас есть некая кодовая база. Обычно, когда запускаем проект, мы создаем сначала Routing, а потом Redux — как же без него? В каждом фреймворке есть специализированный инструмент кодогенерации. В Angular — это CLI Schematics. Во Vue CLI — отдельная секция для генерации плагинов Vue CLI plugins: можно в секции плагинов сгенерировать некий код для наших проектов.
Redux CLI
Я хочу остановиться на React и Redux CLI, потому что из моей практики кодогенерацией меньше всех занимаются именно React-программисты и на это больно смотреть. Каждый раз, когда люди создают одни и те же файлы и жалуются, что с Redux тяжело работать, надо создавать кучу всего. Так есть уже инструменты!
Дополнительно вы можете сгенерировать свои компоненты или кодовую базу с помощью Redux CLI. Это Redux CLI, который за вас создаст dock-файл, в котором будут и эффекты, и редьюсеры, и соответствующие экшены, и «глупые» компоненты, и «умные» компоненты. Ставится Redux CLI просто, вы можете как создать проект с его помощью, так и проинициализировать уже в готовом, например, созданном с помощью Create React App.
npm i redux-cli -g
blueprint new <project name>
blueprint init blueprint g dumb SimpleButton
Есть еще один универсальный инструмент, который не зависит от фреймворка — Plop.
Plop

Plop делает тоже самое, что и предыдущий: проинициализировав этот инструмент, можно создать все необходимые базовые компоненты. Я узнал о нём недавно. Так вы не тратите время на создание основной кодовой базы. Указываете из каких компонент состоит ваше приложение и просто генерируете их. Имея user story и спецификацию можно нагенерировать базовый функционал, тесты, основные стили — сэкономите огромное количество работы.
Все инструменты придется настраивать — я периодически настраиваю под React Blueprint, делаю свою библиотеку компонентов, но это время окупается.
Написание кода
Здесь будет банальщина.
Code snippets
Code snippets позволяют написать небольшой фрагмент, ключевое кодовое слово, и получить готовый кусок функционала. Например, можно создать Angular-компонент, написав @Component.

Для React и Vue есть такие же code snippets.
Чем профессиональнее разработчик, тем меньше он использует code snippets — просто потому, что уже знает, как всё пишется и ему лень их создавать. С банальными code snippets есть проблема. Он уже запомнил, как пишется этот компонент.
Поэтому садимся и пишем code snippets. Напомню, наша цель — потратить время, при этом не сделав ничего полезного. Здесь можно потратить бесконечно большое количество времени, и цель будет достигнута.
Лично мне snippets пригодились, когда я работал с i-bem.js:
modules.define("button<i>«,</i> [«i-bem-dom»], function(provide, bemDom) {
provide(
bemDom.declBlock( this.name,
{
/* методы экземпляра */
},
{
/* статические методы */
}
)
);
});
В этой декларации нет ничего сложного, но синтаксис не похож ни на Angular, ни на React, ни на Vue, и его очень тяжело запомнить первые сто раз. На сто первый запоминается. Я мучался, потратил кучу времени, и потом начал массово создавать эти компоненты просто за счет того, что использовал code snippets.
Для тех, кто работает с WebStorm, это не сильно полезно, просто потому, что в нем нет такой большой экосистемы плагинов и, в основном, всё включено изначально — это полноценный IDE.
VScode extensions / VIM extensions
С редакторами Visual Studio Code и VIM ситуация другая. Чтобы получить от них какую-то пользу, надо ставить плагины. Чтобы найти все хорошие плагины и поставить их можно потратить несколько суток — плагинов безумно много!
Можно сидеть часами, искать, смотреть на них, на красивые анимированные гифки — чудо! Я убил на их поиск безумное количество времени, что и вам рекомендую. Напишите в комментариях, если хотите, чтобы я поделился всеми, что у меня есть.
Есть инструменты, которые автоматически подсвечивают complexity кода, какие тесты проходят, какие нет, когда прямо в коде видно причину непрохождения, какой код прошел или нет, автокомплиты, автопрефиксеры — всё это в плагинах.
Конечно, плагины немного не относятся к написанию кода, но представим, что они помогают нам его написать. Здесь можно потратить очень много времени, и мы нашей цели достигнем.
Рефакторинг
Это моя любимая тема! Причем настолько, что у меня есть отдельный доклад про рефакторинг: «Рефакторинг — Где? Куда? Когда? Откуда? Почему? Зачем и Как?» Я в нем подробно рассказываю что это такое и как с ним работать.
Обычно под этим подразумеваются: «Я улучшил кодовую базу и добавил новую фичу». Сразу предупреждаю, рефакторинг — это не то, что вы обычно себе представляете. Если у вас сейчас когнитивный диссонанс — посмотрите доклад и он пройдет. Это — не рефакторинг.
AngularJS Grunt -> webpack
Про рефакторинг хочу рассказать одну поучительную историю. У нас был очень старый AngularJS-проект, который собирался с помощью Grunt банальной конкатенацией. Проект был написан во времена первой и второй версий Angular. Соответственно, там все было очень просто: файлы конкатенировались, потом uglify, и все. В какой-то момент мы поняли, что надо переезжать на Webpack. У нас огромная legacy кодовая база — как ее перевести на Webpack?
Первое — обратились к библиотеке lebab.io. Мы сделали несколько интересных заходов.
Lebab.io
Эта библиотека позволяет конвертировать код из ES5 в ES6, причем очень хорошо. Она берет старую кодовую базу и превращает ее в новую: вставляет импорты, использует новые строки, классы, выставляет let и const правильно — все делает за вас. В этом плане очень хорошая библиотека.

После этого просто взяли шаблоны Mustache и код, который под новый Angular 1. Мы поставили этот плагин, прогнали код файла через Lebab.io. 5 с компонентным подходом, выглядел по-другому. 6 и 1. С помощью регулярок мы вытащили необходимые куски, с помощью Mustache отрендерили наш шаблон по-другому и прошлись циклом по всем нашим файлам.
var object_to_render = ;
fs.readFile(path_to_mustache_template, function (err, data) { if (err) throw err;
var output = Mustache.render(data.toString(), object_to_render);
fs.saveFileSync(path_to_mustache_template);
}):
В результате мы сконвертировали огромное количество legacy кода в современный формат и быстро подключили Webpack. Для меня лично история очень поучительная.
Jsfmt
Это инструмент, который позволяет форматировать кодовую базу и искать по ней не обычным поиском, а семантически. Мы подключаем нашу библиотеку, файловую систему, считываем файл и хотим что-то найти. Ниже абстрактный пример, мы сейчас работаем с Angular.
var jsfmt = require(‘jsfmt’); var fs = require(’fs’); var js = fs.readFileSync(’component.js’); jsfmt.search(js,"R.Component(a, { dependencies : z })").map((matches, wildcards) => { console.log(wildcards.z);
});
Так выглядит наш запрос:
<b>R.Component</b> (a, { dependencies: z })
R/Component — это собственная библиотека R и некий Component.
Эта часть выглядит очень странно:
R.Component<b> (<u>a</b></u>, { dependencies: <b><u>z</b></u> })
Это не похоже не валидный JavaScript — и так и есть. Мы вставляем маленькие буквы, как плейсхолдеры, и говорим Jsfmt, что нам не интересно, что там находится: объект или массив, строка или boolean-значение, null или undefined — не важно. Нам важно получить ссылки на a и z, после чего, когда мы пройдемся по всей кодовой базе, найдем все варианты z. К примеру, мы можем найти все зависимости у этого компонента. Благодаря этому можно делать сложные рефакторинги.
С помощью инструмента мне удалось отрефакторить огромную кодовую базу семантическим подходом с помощью деревьев и анализа.
Мне не пришлось писать сложные запросы, сложные регулярки или парсить синтаксическое дерево — я просто сформировал запрос и указал, что на что поменять.
Два дополнительных инструмента
В рефакторинге есть простая вещь, про которую я должен сказать. Если вы хотите что-то отрефакторить, то в Visual Studio Code выделите код, и появятся подсказки и варианты рефакторинга, которые есть. К примеру, extract-метод, inline-метод.

В WebStorm есть контекстное меню, которое можно вызвать с помощью комбинации клавиш в зависимости от конфигурации, и отрефакторить кодовую базу.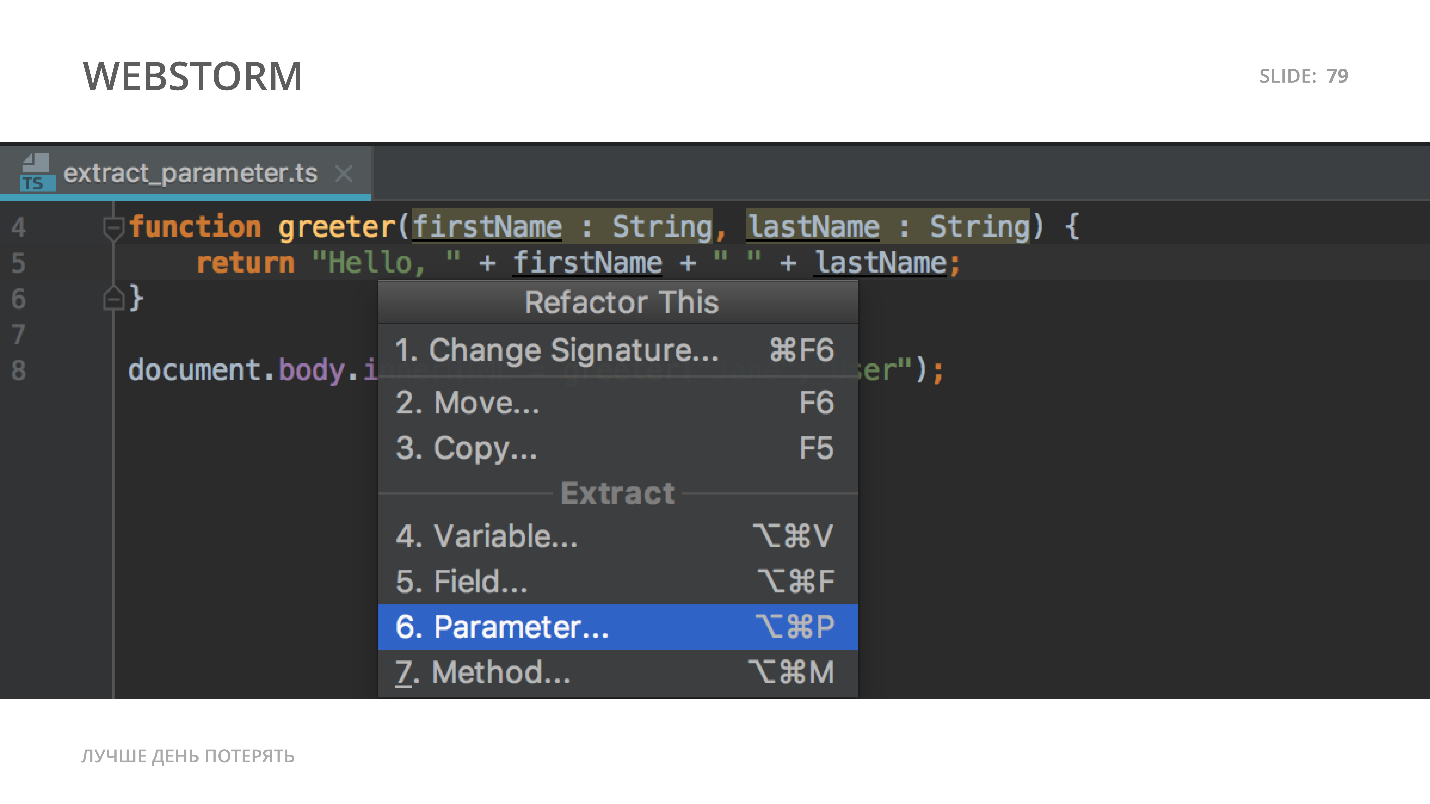
В целом, у WebStorm большее количество команд, он сейчас более развит, чем Visual Studio Code.
Тестирование
Теперь самое интересное и воодушевляющее:)
Selenium IDE
Сначала небольшая история. Пришли ко мне как-то тестеры и говорят:
— Мы пишем end-to-end тесты, хотим автоматизировать их, и у нас есть Selenium IDE.
Он запоминает все ваши шаги — клики, скроллы, вводы, переходы, и эти шаги вы можете проиграть заново. Selenium IDE — это просто плагин для Firefox, который записывает ваши действия в браузере. Можно заэкспортировать то, что вы записали, например, в Java или в Python, и запустить автоматизированные end-to-end тесты с помощью Selenium IDE. Но это еще не все.
Звучит супер, но на деле Selenium IDE сам по себе работает не идеально, и к тому же на тот момент у нас еще был ExtJs.
ExtJs
Если у вас был ExtJs — сочувствую и обнимаю. Selenium IDE записывает всегда самый уникальный селектор. На наших элементах — это id. Но ExtJs для каждого элемента генерирует рандомный id, не знаю зачем. Эта проблема у ExtJs идет с нулевой версии.
ExtJS = <div id="random_6452"/>
В результате наши тестеры с утра открывали приложение, записывали все, потом, не перезагружая страницу, периодически прогоняли ее, пытаясь понять, сломался ли бэкенд, к примеру. Они обновляли бэкенд, а фронтенд не трогали. Главное было — не нажать refresh, потому что после этого генерировался новый id.
Selenium IDE умеет экспортировать свои записи в HTML-формат — мы же умеем работать с HTML, у нас есть шаблонизаторы — давайте попробуем это сделать! Тут же тестерам пришла одна гениальная идея.
Google Chrome Extension
Быстро создали Google Chrome-расширение и тут же нашли шикарный метод elementFromPoint.
document.elementFromPoint(x, y);
Банально записывая движение мышки на окне и вызывая потом elementFromPoint, когда срабатывал клик, я находил координаты элемента, на который кликал. Дальше обязательно нужно было создать некий селектор, как-то выделить конкретно этот элемент. Id пользоваться нельзя — что же делать?
Для компонента создавался абстрактный тестовый id, который был нужен только для тестов. Пришла идея — дополнительно вешать на компоненты специальные test-id.
data-test-id="ComponentTestId«
Он генерировался только в тестовом окружении и по нему мы делали select по data-атрибуту. Но этого не всегда хватало. К примеру, у нас есть компонент, но внутри еще есть div, span, icon, иконка в i-теге. Что с этим делать?
Для этого «хвоста» мы дополнительно генерировали XPath:
function createXPathFromElement(elm) {
var allNodes = document.getElementsByTagName(’*’);
for (var segs = [ ]; elm && elm.nodeType = 1; elm = elm.parentNode)
{
if (elm.hasAttribute(’class’)) {
segs.unshift(elm.localName.toLowerCase() +
’[a)class = «’ + elm.getAttribute(‘class’) + ‘ »] ‘);
} else {
for (i = 1, sib = elm.previousSibling; sib; sib = sib.previousSibling) {
if (sib.localName = elm.localName) i++; }; segs.unshift(elm.localName.toLowerCase() + ’[’ + i + ’]’);
};
};
return segs.length ? ’/’ + segs.join(’/’) : null;
};
В результате формируется уникальный XPath-селектор, который состоит, в успешном случае, из data-атрибута селектора по data-атрибуту с названием компонента:
<b><u>.//*[@data-test-id=’ComponentName’]</b></u>/ul/li/div/p[2]
Если внутри компонента была еще какая-то сложная структура, дополнительно по строгому XPath все выделялось — без id. Мы избегали id, потому что работали с ExtJs.
Мы все записывали, экспортировали обратно в HTML-документ, загружали обратно в Selenium IDE и прогоняли. Этот XPath можно было легко протестировать.
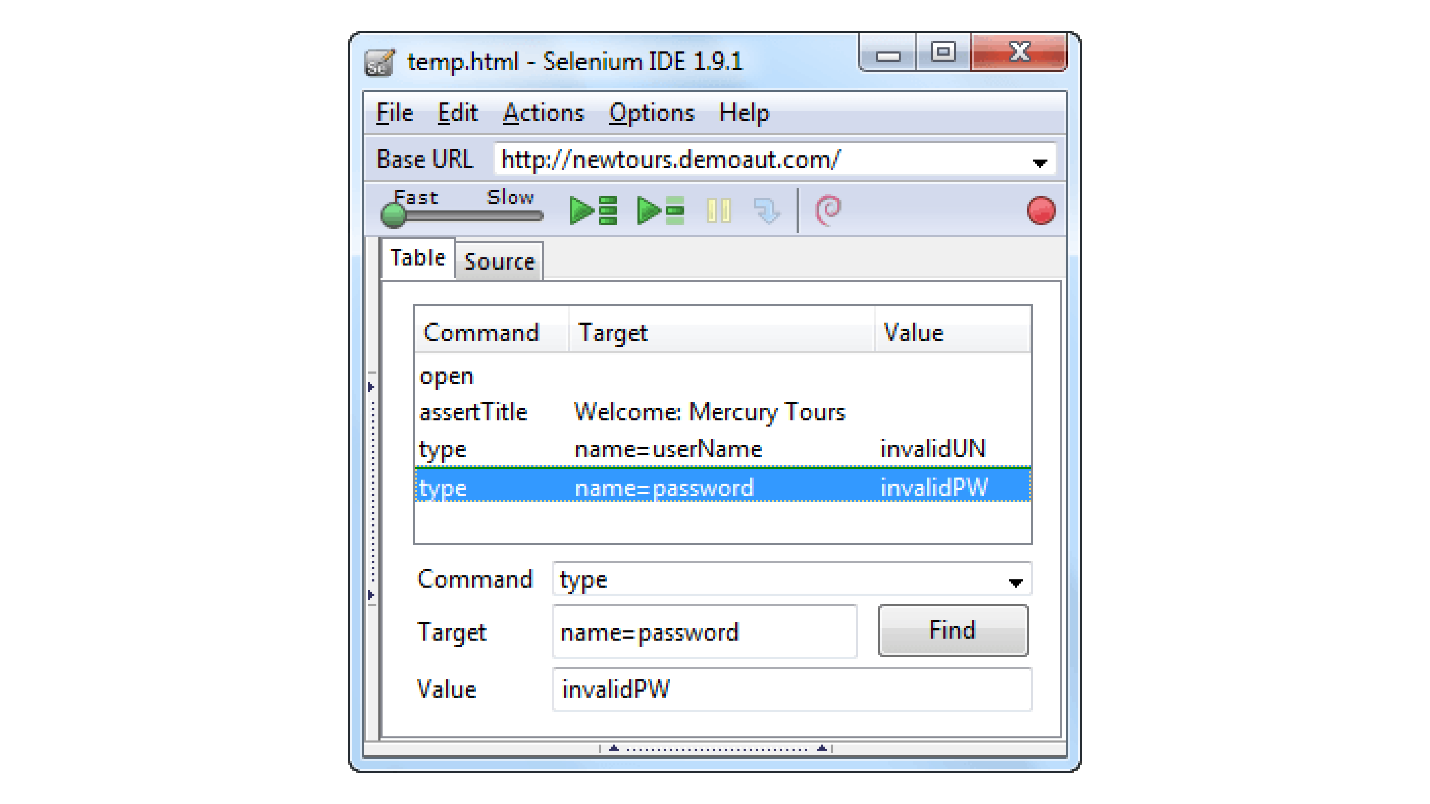
Там же мы добавили много умных проверок прокрутки спиннера, успешной загрузки приложения — добавили дополнительные нюансы, которые Selenium IDE не учитывает. Мы создали Chrome Extension, который просто генерировал формат записи Selenium IDE, но по-своему, не так, как это делает Selenium IDE. Благодаря этому у нас появились полностью автоматизированные end-to-end тесты.
Единственное, что после этого оставалось сделать тестерам — открыть любую версию приложения, кликнуть, загрузить в Selenium IDE, проверить, сохранить это как Python-код, радоваться повышению зарплаты и премии и говорить мне «спасибо».
Я не знаю о подобных инструментах для React и VueJS — возможно, они и есть. Для unit-тестов не могу обрадовать людей из React и VueJS сообществ — простите! Обрадую только тех, кто с Angular.
SimonTest
Существует плагин SimonTest в Visual Studio Code для Angular.

После чего появится весь необходимый каркас: Если вам нужно написать unit-тест на ваш компонент — указываете на этот компонент и говорите сгенерировать каркас вашего unit-теста.
- будут созданы все необходимые зависимости, они будут замоканы и указаны все необходимые свойства для корректного тестирования;
- будут созданы тесты на методы с базовой проверкой и базовым функционалом.
Останется лишь добавить проверку бизнес-логики и какой-то логики вашего компонента, или бизнес-логики вашего приложения в этот компонент. Просто нажав генерацию, мы получаем полноценный каркас для unit-тестов.
Потратьте время на тестирование — это будет на зря.
Отладка
Первые 80% времени в разработке не так страшны, как последние 80% в отладке.
Где на отладке можно потратить время, когда у нас нет еще исключений и проблем? Что на этом этапе можно интересного поделать и потратить кучу времени?
Chrome DevTools
Здесь мы можем проверить производительность, получить какие-то данные и отладить наш код, чтобы понять, как он работает в реальности, особенно если кодовая база старая.
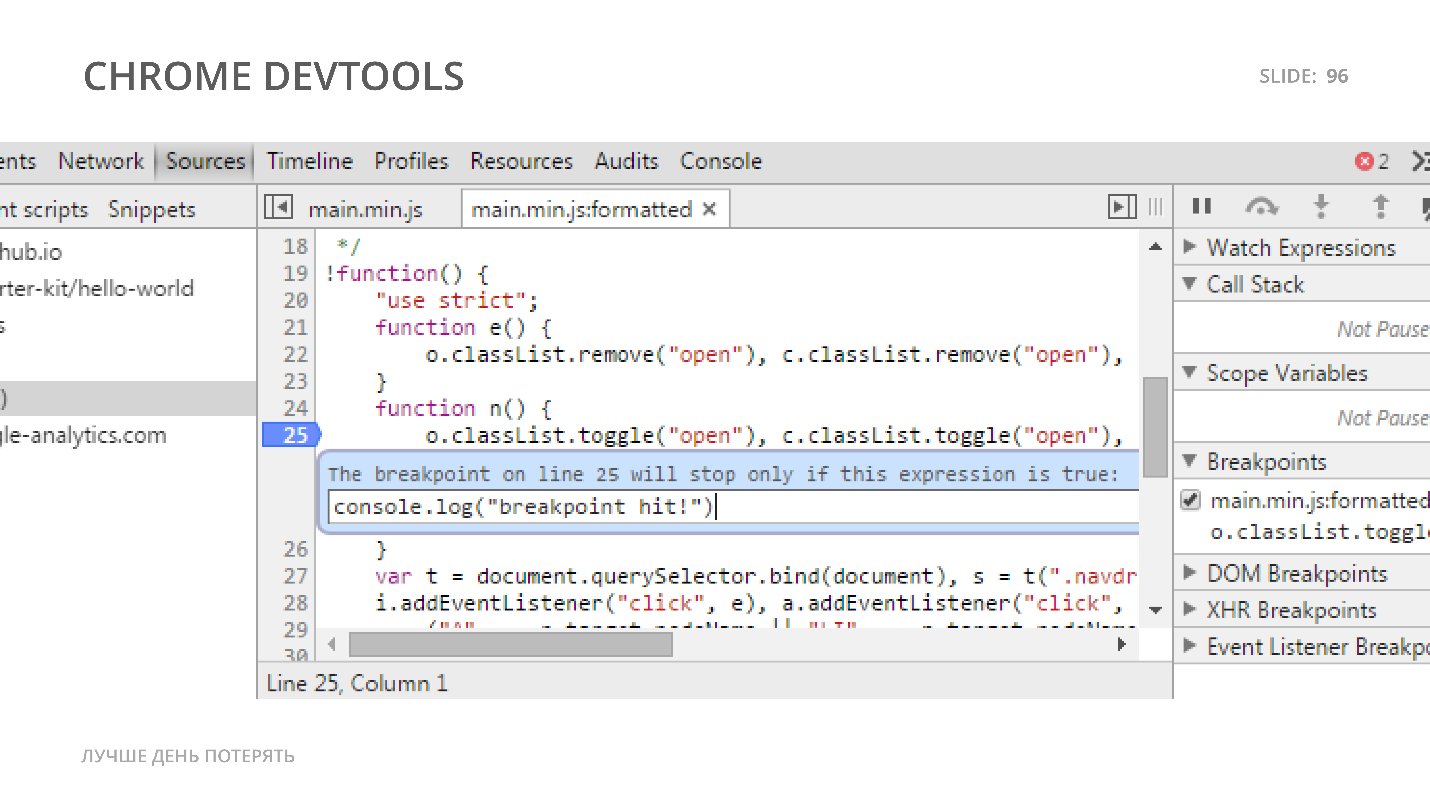
Фулл-стек или бэкенд-программисты просто обязаны знать альтернативу, которую используют для отладки. Какие альтернативы Debugger вы знаете? Есть Profiler, но он больше для определения производительности, есть Dumps, но нас интересует работа в runtime, а есть инструмент именно для мониторинга, который позволяет понять, что происходит и что идет не так.
Tracing
Для начала — концепция трассировщика: записываются все события в реальном времени. В runtime записывается весь лог всего: произошел клик, который вызвал событие, после вызова события — promise, потом setTimeout, после setTimeout еще один promise. Все эти события ловит трассировщик.

Spy-js vs TraceGL
Изначально существовало два основных конкурента: Spy-js и TraceGL. Эти конкурирующие трассировщики могли в реальном времени показать, что происходит с программой. Отличие от Debugger в следующем: допустим, ваша кодовая база состоит из тысячи строк — сколько раз ее нужно проходить? Долго, тяжело, муторно — и вы не всегда сможете выловить баги.
Если у вас многопоточная программа, которая делает deadlocks — вы не поймаете deadlock с помощью отладчика, потому что события будут приходить в другой последовательности. Проблема отладчика, например, на многопоточном бэкенде — если вы начинаете блокировать, то некоторые вещи просто не находите.
Они позволяют видеть реальную картину в реальном времени. В JS иногда происходит то же самое, поэтому трассировщики помогают. Вы просто анализируете deadlocks и все.
Изменения появлялись только в spy-js. Spy-js купил WebStorm, очистил репозиторий, новые версии больше не выкладываются. У разработчика были огромные планы, он обещал, что в Firefox появится супер-трассировщик. TraceGL купил Mozilla. Следов TraceGL в Chrome не видно и, скорее всего, не будет никогда. TraceGL был крутой, но потом, видимо, начальство решило внедрять новые фичи инкрементально и они так и внедряются до сих пор.
Он настраивается очень легко: вы создаете некую конфигурацию Spy-js, запускаете ваш проект, после чего начинаете ловить все необходимые события в реальном времени и можете анализировать их. Возрадуйтесь, обладатели WebStorm, потому что именно там есть Spy-js. Если вы прогнали код с помощью Spy-js, после того, как программа завершилась, можно посмотреть, какие переменные и какие значения были в ваших аргументах. Дополнительно WebStorm предоставляет еще ряд интересных фич: он совместим с TypeScript, CoffeeScript, дополнительно показывает последние данные выполнения. В этом плане инструмент шикарный.
Несколько минут — и я эксперт в любой кодовой базе, просто потому что в реальном времени видел и понимал, что происходит. В любом новом проекте, в который приходил, я включал трассировщик и через 5 минут знал, как работает проект: архитектура, устройство, элементы взаимодействия, какие события происходят.
Что теперь у нас в арсенале?
- Мы потратили кучу времени на настройку и написание скриптов для терминала.
- Для проектирование мы потратили время на картинки, которые в результате мы все-таки превратили в код, но не в полноценный, а только в каркас бизнес-логики.
- Создание проекта. Мы соскафолдили проект с помощью инструментов.
- Кодогенерация — сгенерировали некоторое количество кода, базовые компоненты, то есть сделали черновую работу;
- Мы сами код не написали, но при этом все подготовили: поставили все плагины и сниппеты.
- На рефакторинге можно убивать бесконечное количество времени, и мы это сделали, но воспользовались умными инструментами — это немного не то, что я хотел.
- На тестировании хорошо потратили время — создали свой собственный тестовый рекордер.
- На отладку можно потратить столько времени, сколько хотим! Отлаживать можно бесконечно.
Зачем мы всё это делали? Процитирую профессионала из мультика «Крылья, ноги и хвосты»:
Запомни: лучше день потерять, потом за 5 минут долететь! — Все равно ты не взлетишь! Вперед!
Уже через пару недель пройдет Frontend Conf. Доклад Алексея — один из лучших на конференции 2018 года. Понравилось? в составе РИТ++. Приходите на Frontend Conf РИТ++ в мае, подписывайтесь на рассылку: новые материалы, анонсы, доступы к видео и больше крутых статей. Присоединяйтесь!
Опрос. Стоит ли тратить время на..


![Фото [Перевод] Делаем код-ревью правильно](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-delaem-kod-revyu-pravilno-390x220.png.pagespeed.ic.vpSnpmykLy.png)
![Фото [Перевод] Самонагревающийся бетон на шаг ближе к тому, чтобы избавить нас от использования снеговых лопат и соли](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-samonagrevayushhijsya-beton-na-shag-blizhe-k-tomu-chtoby-izbavit-nas-ot-ispolzovaniya-snegovyx-lopat-i-soli-390x220.jpg.pagespeed.ic.nP1EbRJPy7.jpg)
![Фото [Перевод] Самонагревающийся бетон на шаг ближе к тому, чтобы избавить нас от использования снеговых лопат и соли](http://orion-int.ru/wp-content/uploads/2024/03/perevod-samonagrevayushhijsya-beton-na-shag-blizhe-k-tomu-chtoby-izbavit-nas-ot-ispolzovaniya-snegovyx-lopat-i-soli-220x150.jpg.pagespeed.ce.c7zyDe-yI6.jpg)

