
[Из песочницы] В поисках «Годзиллы». Нейросети и прогнозирование котировок на основе биржевых и «внешних» данных

Эта работа вдохновлена статьей «Мечтают ли нейросети об электроденьгах?», где автор без преувеличения талантливо в своей доходчивости объясняет, почему использование искусственных нейросетей на голых биржевых данных не приводит к успеху. Вот особенно, на мой взгляд, удачный отрывок:
«Цена не формирует сама себя… Если рынок выразить как метафоричное озеро, то биржевой график это лишь рябь на воде. Может быть это ветер подул, может камень в воду бросили, может рыбы плеснула, может Годзилла прыгает в 200 километрах на батуте. Мы видим лишь рябь.»
Действительно, пытаться предсказать поведение ряби на следующий день, имея в распоряжении только лишь данные о поведении ряби в прошлом, видится, как минимум, самонадеянным. Не тот масштаб модели. Поведение водной глади формируется за счет множества внешних и внутренних по отношению к водоему факторов. И вот на этом моменте мое любопытство не позволило мне пройти мимо. А что если все-таки поработать с этими факторами? Что получиться, если учесть их в модели данных, предназначенных для «кормежки» нейросети?
«Но как же учесть миллионы, если не миллиарды возможных факторов влияющих на наш метафорический водоем?» — спросите вы. А я отвечу, что нас не интересуют ни движение мальков, ни случайно упавший с близлежащей скалы камушек, ни мерное покачивание удочки Дяди Вити-рыбака. Нас интересует Годзилла.
Справедливости ради стоит отметить, что автор вдохновившей меня статьи не исключает возможности увеличения прогностической точности нейросети, если учесть все множество отмеченных факторов. Тем не менее, в упомянутой статье рассуждения об их природе сводятся к пределу детализации — к человеку. А именно, к учету состояния (психического, психологического, физиологического, финансового и т.д.) каждого конкретного участника рынка. Этооо… дорого. Дорого настолько, что неразумно.
Я же в своей работе обращаюсь к гипотезе, что поведение участников торгов предваряют события, которые это поведение определяют. Я предполагаю что в паре «События»/«Поведение пользователей» «События» все же метафорическая собака, а «Поведение пользователей» — метафорический хвост, и собака, как положено, виляет хвостом, а не наоборот. Вот это самое предположение я и предлагаю нам с вами проверить.
Для тех, кто хочет сразу перейти к делу и поэкспериментировать самостоятельно — весь код и данные содержатся на GitHub вот тут.
Начнем
Сформулируем вопрос, на который будем искать ответ, более строго: «Увеличится ли эффективность прогнозирования поведения цены финансового актива нейронной сетью, при включении результатов анализа событийного потока в состав модели данных?»
Событие — понятие смутное и вольно трактуемое, потому будем его принудительно определять. Под событиями здесь и далее предлагаю понимать тематические новости на популярных ресурсах и транзакционную активность рассматриваемого финансового инструмента.
По отношению к анализу новостей, очевидно, разумным решением будет применить методы sentiment analisys, а в отношении транзакционной активности… «Стоп. Что за зверь эта ваша «транзакционная активность»?» — повис вопрос на лице читателя. Тут мы подошли к моменту, когда пора определить наш объект исследования.
Среди всего многообразия активов, для анализа я выбрал биткоин, и на то есть причина. Имя причины — блокчейн. Мне стало до жути интересно — как изменится предиктивная способность сети, если в модель данных мы добавим еще и динамику активности в самой сети биткоин? Сможем ли мы таким образом выявить «подводное течение» в нашем метафорическом водоеме? В конце концов, вдруг Годзилла в лучших традициях классического кинематографа прячется под водой?
Активность справедливо измерять в объемах переданных по сети криптомонет, информация о которых содержится в записях транзакций в блоках, собственно, блокчейна. Транзакция, в свою очередь, состоит из «входов» — это сумма монет, которую определенный кошелек принял, и «выходов» —это суммы монет, которые были (а) отправлены с определенного кошелька, (б) были возвращены на кошелек-отправитель в качестве «сдачи», (в) были уплачены в качестве комиссии майнерам. Поскольку суммы, указанные в качестве выходов транзакций на мой взгляд содержат больше информаци, в качестве мерила активности сети предлагаю использовать именно их.
Итак, прежде, чем отправиться в увлекательное путешествие, заглянем в список того, что должно находится в нашем инвентаре:
- Данные о биржевых торгах;
- Данные об активности в биткоин-сети;
- Преобразованный поток тематических новостей;
- TensorFlow + Keras — one love.
Пункт 3 — предмет для описания в ближайшем будущем, а вот со всем остальным мы поработаем сейчас.
Поиск данных
Первое — данные о биржевых торгах. Найти их не должно быть тяжелой задачей. И действительно, быстрая пробежка по первым строкам результатов Google привела меня на invrsting.com. Здесь забираем CVS с максимальной глубиной во времени и дневной детализацией.
Пометка на полях: пользоваться рекомендую данными Investing.com Bitcoin Index, поскольку автоматически рекомендуемый Bitfinex Bitcoin US Dollar содержит бессовестные пропуски данных недельных масштабов.
В чистом виде информацию об объеме выходов на каждый конкретный день мне найти не удалось, но не беда. Настойчивый поиск по теме привел на ресурс MIT, где инженеры кропотливо собирали детальную информацию по блокчейну биткойна в различных разрезах. Сам ресурс тут.
Из всего представленного перечня датасетов, нам понадобятся:
- bh.dat.gz — содержит хэш-суммы блоков. Формат: идентификатор блока (blockID), хэш-сумма (hash), временная метка записи блока в блокчейн (block_timestamp), количество транзакций в блоке (n_txs);
- tx.dat.xz — содержит информацию о транзакциях. Формат: идентификатор транзакции (txID), идентификатор блока, в который записана транзакция (blockID), количество входов (n_inputs), количество выходов (n_outputs);
- txout.dat.xz —содержит информацию о выходах для каждой транзакции. Формат: идентификатор транзакции (txID), порядковый номер (output_seq), идентификатор адреса, куда отправляется выход (addrID), объем отправленных монет (sum).
Сопоставим данные файлов друг с другом следующим образом:
import pandas as pd #Loading bh.datmit_data = pd.read_table('.../bh.dat', header=None, names=['blockID', 'hash','block_timestamp', 'n_txs'])mit_data['block_timestamp'] = pd.to_datetime(mit_data['block_timestamp'], unit='s')#Loading info about output of transactionsout_txs_all = pd.read_table('.../txout.dat',header=None, names=['txID', 'output_seq','addrID', 'sum'])#Loading info transaction overview datasetmapping_dataset = pd.read_table('.../tx.dat', #The path to the tx.dat file header=None, names=['txID', 'blockID','n_inputs', 'n_outputs'])#Dropping needless columns in outputs dataset and summing up outputs values groupping them by 'txID'out_txs_all.drop('output_seq',axis=1,inplace=True)out_txs_all.drop('addrID',axis=1,inplace=True)out_txs_all = out_txs_all.groupby('txID').sum().reset_index() #Dropping needless columns in transactions dataset and adding outputs valuesmapping_dataset.drop('n_inputs', axis=1,inplace=True)mapping_dataset.drop('n_outputs', axis=1,inplace=True)mapping_dataset['sum_outs'] = out_txs_all['sum'] #Now we can dropp 'txID' column since it's useless now.#Then we group mapping_df by blockID and addup all sums to get btc_sum per particular blockmapping_dataset.drop('txID', axis=1, inplace=True)mapping_dataset=mapping_dataset.groupby('blockID').sum().reset_index() #Prepare mit_data to the next manipulationsmit_data.drop('hash', axis=1,inplace=True)mit_data.drop('n_txs', axis=1,inplace=True) #Now we just can get dates from sliced block_timestemp dataset and concatinate#it with mapping_df since they have equals sizes and contains similar blocks.mapping_dataset['Date'] = mit_data['block_timestamp']mapping_dataset['sum_outs'] = mapping_dataset['sum_outs'].apply(lambda x: x/100000000) #Getting amount of bitcoins instead of satoshies #Finally we are making a csv filemapping_dataset.to_csv('../filename.csv', index=False) На выходе получаем таблицу суммарного объема выходов, записанных в блокчейн биткоина с 17.07.2010 по 08.02.2018. И вроде все чудесно, только покоя не дает тот факт, что данные ограничиваются 08 февраля 2018 года. А ведь дальше занимательный период волатильности, начавшегося как раз в феврале 2018 года. А волатильность — это источник информации. Разбрасываться информацией — кощунство. Потому обращаемся к API blockchain.com, потому как более удобного варианта я не нашел.
Получаем недостающие данные следующим образом:
import requestsimport json# Makeing timeline in unix timelimit_day = pd.to_datetime('2018-02-09')datelist = pd.date_range(limit_day, periods=733).to_list()date_series = pd.DataFrame(data=(datelist), columns=['Date'])dt = pd.DatetimeIndex(date_series['Date']).astype(np.int64)//1000000unix_mlseconds_lst = dt.to_list() #Getting blocks hash list with timestampsblocks_lst = []for j in unix_mlseconds_lst: request = requests.get('https://blockchain.info/blocks/'+str(j)+'?format=json') parse_result = json.loads(request.content) blocks_lst.append(parse_result['blocks']) #Parsing json content for the final datasetblockID = []hashID = []timestamp = []for d_list in blocks_lst: for dictionary in d_list: blockID.append(dictionary['height']) hashID.append(dictionary['hash']) timestamp.append(dictionary['time']) #Makeing additional bh-datasetadditional_bh = pd.DataFrame(data=(blockID,hashID,timestamp)).Tadditional_bh.columns=['blockID','hash','timestamp']additional_bh['timestamp']=pd.to_datetime(additional_bh['timestamp'], unit='s') #Getting info about additional outputsdates_out_sums = {}for indx in range(len(additional_bh)): request = requests.get('https://blockchain.info/rawblock/'+str(additional_bh['hash'][indx])) #Getting all info about block by it's hash parse_result = json.loads(request.content) block_outs_sum=[] for i in parse_result['tx']: #Running through all txs to sum up all outputs intermid_out_sum_values = [] for j in i['out']: intermid_out_sum_values.append(j['value']) block_outs_sum.append(sum(intermid_out_sum_values)) dates_out_sums[bh['timestamp'][indx]] = sum(block_outs_sum) #Making dataframe of additional outputsdates_out_sums_lst = dates_out_sums.items()out_txs = pd.DataFrame(dates_out_sums_lst, columns=['Date', 'out_sums'])out_txs['out_sums']=out_txs['out_sums'].apply(lambda x: x/100000000) #Making a series of bitcoins instead of satoshiesout_txs.to_csv('.../Data/additional_outs_dated(2018-02-09_2018-04-28).csv', index=False)Пометка на полях: качать информацию с blockchain.com оказалось делом, мягко говоря, небыстрым. В процессе работы над статьей, наряду с лопнувшим терпением, я получил данные из 11949 дополнительных блоков, что соответствует двум дополнительным месяцам. Я посчитал, что этого будет достаточно.
Теперь объединяем полученные датасеты, и мы готовы к этапу предварительной обработки информации.
Data pre-processing
Первое, что бросается в глаза, это формат данных нашего биржевого датасета.

Кроме того, что данные приведены в текстовом формате, выгрузка совсем некстати содержит запятые и разнородные ‘K’, и ‘M’ в значениях объемов, что не дает конвертировать данные во float-формат стандартными методами. Дотошное гугление рыночных данных с пристрастием не дало результатов такого же широкого временного диапазона. Что ж. Регулярные выражения Python, дайте мне силы!

import reimport pandas as pd def strtofloatconvert(data): #Converting series to list price_lst = data['Price'].to_list() open_lst = data['Open'].to_list() high_lst = data['High'].to_list() low_lst = data['Low'].to_list() vol_lst = data['Vol.'].to_list() change_lst = data['Change %'].to_list() #Separating str by ',' sign exept Volume strings. It's got anoter #format, like '294.8K' or '12.9M'. Volume we convert lower sprt_prices = [] sprt_open = [] sprt_high = [] sprt_low = [] sprt_p = [] sprt_o = [] sprt_h = [] sprt_l = [] for price in price_lst: sprt_p = re.split(r',',price) sprt_prices.append(sprt_p) for open_p in open_lst: sprt_o = re.split(r',',open_p) sprt_open.append(sprt_o) for high in high_lst: sprt_h = re.split(r',',high) sprt_high.append(sprt_h) for low in low_lst: sprt_l = re.split(r',',low) sprt_low.append(sprt_l) #Adding splitted values together and converting them to float add_p = [] add_o = [] add_h = [] add_l = [] add_v = [] add_ch = [] for p in sprt_prices: if len(p) == 2: a = p[0]+p[1] a = float(a) add_p.append(a) else: a = p[0] a = float(a) add_p.append(a) for o in sprt_open: if len(o) == 2: a = o[0]+o[1] a = float(a) add_o.append(a) else: a = o[0] a = float(a) add_o.append(a) for h in sprt_high: if len(h) == 2: a = h[0]+h[1] a = float(a) add_h.append(a) else: a = h[0] a = float(a) add_h.append(a) for l in sprt_low: if len(l) == 2: a = l[0]+l[1] a = float(a) add_l.append(a) else: a = l[0] a = float(a) add_l.append(a) #Working with zeroes in 'Vol.' in str_flt because it does not matter whether we put None or zero in empty space. #Pandas will convert None into NaN wich is kind of float 'number'. It will not respond to pandas 'isnull()' function. for v in vol_lst: if v == '-': add_v.append(0) else: exam = re.findall(r'K',v) if len(exam)>0: add = re.sub(r'K', '',v) add = float(add) add *= 1000 add_v.append(add) else: add = re.sub(r'M', '',v) add = float(add) add *= 1000000 add_v.append(add) for i in change_lst: add = re.sub(r'%', '',i) add = float(add) add_ch.append(add) #Putting all lists above to the DataFrame test_df = pd.DataFrame(data=(add_p, add_o, add_h, add_l, add_v,add_ch)).T test_df.columns = ['Price', 'Open', 'High', 'Low', 'Vol.', 'Change%'] return test_dfДругое дело.
Посмотрим на хвост полученного нами датафрейма.
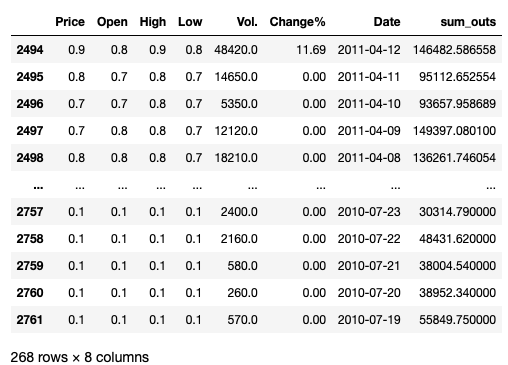
267 элементов датасета не содержат информации о динамике изменения стоимости. Удалим их повышения общей информативности данных ради.
Теперь, поскольку мы собрались все же прогнозировать поведение цены в будущем, нам нужно организовать данные так, чтобы цена в момент времени Т соответствовала набору признаков T-n, где n — это дальность нашего горизонта прогноза. Предлагаю попытаться заглянуть в будущее для начала на один день вперед. Для этого мы удаляем последнее значение из перечня цен закрытия и первую строку соответствующих признаков.
price = test_df.pop('Price')price = price.drop(price.index[-1])test_df = test_df.drop(test_df.index[0]) test_df.index = np.arange(len(test_df))test_df = pd.concat((price,test_df), axis=1)Таким образом мы получаем имитацию реальной картины мира. Текущие цены будут прогнозироваться на основе вчерашних данных, а данные за сегодняшний день, соответственно, будут лежать в основе прогноза на день завтрашний.
Поскольку в процессе тестирования нашей нейросети тренировочная и тестовая выборки будут состоять из перемешанных значений подготовленного нами датасета, а нам с вами все-таки хочется посмотреть, как прогнозы будут соотноситься с реальными котировками, ради наглядности отщипнем от данных первые 45 строк из расчета тестирования результатов на промежутке длинной в полтора месяца.
PRACTICE_DS_SIZE = 45later_testds_for_plot = test_df.iloc[:PRACTICE_DS_SIZE]test_df = test_df.iloc[len(later_testds_for_plot):]test_df = test_df.reset_index(drop=True)Для предстоящей оценки эффективности модели, тренированной только на биржевых данных, пока что извлечем из датасета информацию об объемах выходов транзакций. Так же, за ненадобностью в процессе обучения и прогнозирования, извлечем даты.
timestamps = test_df.pop('Date')sum_outs = test_df.pop('out_sums')Делим датасет на тренировочную и тестовую выборки и извлекаем зависимую переменную — цену закрытия:
# Making train/test splittrain = test_df.sample(frac=0.8, random_state=42)test = test_df.drop(train.index) #Setting targetstrain_labels = train.pop('Price')test_labels = test.pop('Price')Полученные данные нормализуем.
def norm(train_data, data): #Getting overall statistics train_stats = train_data.describe() train_stats = train_stats.transpose() #Normalising data normalized_data = (data - train_stats['mean']) / train_stats['std'] return normalized_dataТеперь проверим насколько эффектным будет обычный многослойный перцептрон, если ему скормить только лишь биржевые данные.
Тестирование нейронной сети
Покрутив некоторое время гиперпараметры, я получил следующую, наиболее оптимальную из всех изученных мной, конфигурацию нейросети:
def build_model(): model = keras.Sequential([ layers.Dense(32, activation='relu', input_shape=[len(train.keys())]), layers.Dense(32, activation='relu'), layers.Dense(32, activation='relu'), layers.Dense(16, activation='relu'), layers.Dense(1) ]) optimizer = tf.keras.optimizers.RMSprop(0.001) model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse']) return modelmodel = build_model()model.summary() EPOCHS = 500 # Patience parameter describes epoch amount testing on improvementearly_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10) model.fit(normed_train_data2, train_labels2, epochs=EPOCHS, validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
PrintDot() — коллбэк отвечающий за вывод красивых точек в процессе обучения модели. Позаимствовал его из официальной документации по TensorFlow. Очень уж он мне понравился. Выглядит он незамысловато:
class PrintDot2(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs): if epoch % 100 == 0: print('') print('.', end='')Задача его — рисовать точки, отражая эпохи.
Что ж, запустим тренировку нашей модели и посмотрим на результат.
Проверим эффективность модели на тестовой выборке.
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)Результат: 506/506 — 0s — loss: 36201.9241 — mae: 66.5216 — mse: 36201.9219
MSE в 45430.1133 долларов оставляет нас со среднеквадратическим отклонением в 190.27 долларов. Многовато.
Теперь проведем обучение и тестирование сети на данных, содержащих выходы транзакций.
loss, mae, mse = model.evaluate(normed_test_data2, test_labels2, verbose=2)Результат: 506/506 — 0s — loss: 24382.0926 — mae: 48.5508 — mse: 24382.0918
MSE в 24382.0918 долларов значит, что среднеквадратическое отклонение сократилось до 156.15 долларов, что, конечно, не сказка, но улучшение налицо.
Момент истины. Произведем прогнозирование и нарисуем как соотносятся предсказанные значения цен закрытия с реальными ценами.
actual_price = later_testds_for_plot.pop('Price')actual_dates = later_testds_for_plot.pop('Date')normed_practice_data = norm(train, later_testds_for_plot)practice_prediction = model.predict(normed_practice_data).flatten() actual_price2 = later_testds_for_plot2.pop('Price')actual_dates2 = later_testds_for_plot2.pop('Date')normed_practice_data2 = norm(train2, later_testds_for_plot2)practice_prediction2 = model.predict(normed_practice_data2).flatten() fig = plt.figure(figsize=(15,6))ax1 = fig.add_subplot(121)ax2 = fig.add_subplot(122) ax1.plot(actual_dates,actual_price, label ='actual btc price')ax1.plot(actual_dates,practice_prediction, label ='predicted btc price')ax1.set_title('BTC Close Price Prediction with only Exch Data')ax1.legend() ax2.plot(actual_dates2,actual_price2, label ='actual btc price')ax2.plot(actual_dates2,practice_prediction2, label ='predicted btc price')ax2.set_title('BTC Close Price Prediction with Outs')ax2.legend()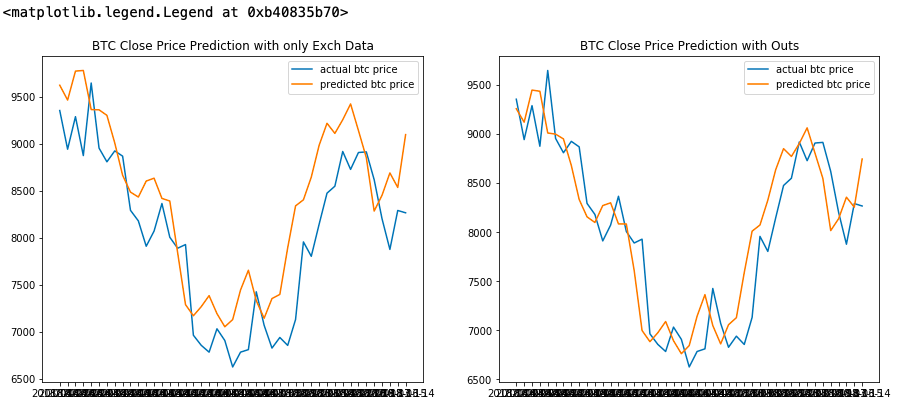
На графиках видно, что линия цен, спрогнозированных с учетом выходов транзакций сети биткоин, лежит значительно ближе к линии действительных цен закрытия. Этого, безусловно, недостаточно для того, чтобы торговать, но достаточно, чтобы набраться оптимизма в отношении последующих исследований.
Выводы
Итак, если Годзилла и живет внутри водоема, то уж точно не в области динамики объемов выходов транзакций сети биткоин. Тем не менее, определенных успехов в части прогнозной эффективности, благодаря добавлению дополнительных источников в модель данных, мы добились.
Этот вольный эксперимент, безусловно, не обнадеживает в части создания финансового «Демона Лапласа» (мы ж ведь все-таки разумные люди), но дарит определенный оптимизм в отношении моделирования хотя бы небольшого такого «бесенка».

![Фото [Перевод] Как я выиграл Хакатон, едва не потеряв рассудок](http://orion-int.ru/wp-content/uploads/2024/03/xperevod-kak-ya-vyigral-xakaton-edva-ne-poteryav-rassudok-390x220.png.pagespeed.ic.uqlKF6sbRM.jpg)




