
У розницы очень разнообразный круг покупателей. Их много – всевозможных профессий и уровней дохода, от молодёжи до пенсионеров. Такое разнообразие не получится корректно описать двумя-тремя бизнес-правилами, потому что вы просто не сможете охватить все сочетания критериев и неизбежно потеряете часть клиентов. Поэтому для розницы очень важно как можно точнее сегментировать свою аудиторию, но это неизбежно усложняет модели. Здесь на помощь приходят технологии Machine Learning, дающие бизнесу более точные прогнозы и ответы на важные вопросы.

Например: уйдёт ли клиент? 
Какие вопросы имеются в виду? Например, женщина каждый месяц покупает особый крем за 10 тысяч рублей и может выбирать из двух магазинов косметики. Нередко клиенты уходят, если в магазине нет нужного товара. Скорее всего, она станет постоянно покупать во втором, пусть и чуть дороже. В одном из них часто отсутствует нужный товар, а во втором проблем с наличием нет.
Например, нужно спланировать рабочие смены кассиров и продавцов-консультантов. Другой актуальный вопрос: как оптимизировать работу персонала? Аналитик оценивает активность клиентов в зависимости от дня недели и видит, что в субботу покупают больше всего, а в пятницу и в воскресенье чуть меньше. Один способ подразумевает использование статистического анализа. Эту гипотезу проверяют статистическими тестами, а выводы передают руководству.
Например, если 7 марта приходится на среду — купят ли в этот день больше, чем в пятницу (ведь в обычное время пятница – более популярный день, чем остальные будни)? Но такой анализ может не учитывать многих сочетаний факторов. Или местные праздники? А выпускные? И вместо того, чтобы бесконечно усложнять правила, можно построить модель, которая спрогнозирует спрос на конкретный день. Чем больше факторов, тем труднее их все учесть с помощью простых правил.

Наш проект в non-food ритейле
В данном случае нужно было проанализировать базу покупателей (примерно 2,5 млн человек) и предсказать, кто из них вернётся в магазин в ближайшие две недели. Мы взяли два метода библиотеки CatBoost — CatBoostClassifier и CatBoostRegressor, первая — для прогнозирования состава аудитории, вторая — для выбора самых востребованных товаров в ближайшие 2 недели. CatBoost вышел в самом начале нашего проекта, это был свежий подход к работе с категориальными признаками. А поскольку номенклатура товаров нашего заказчика содержит очень много категориальных фич, мы с удовольствием попробовали новинку в работе. После подбора параметров модель сразу же оправдала наши надежды точным прогнозированием. Не зря CatBoost — одна из самых популярных сегодня моделей градиентного бустинга.
Для модели взяли статистику за 2017 год:
- чеки: кому принадлежит бонусная карта из чека, когда сделана покупка, что купили, размер скидки, покупка это или возврат.
- демография: регион и город проживания клиента, дата рождения и пол, согласия на рассылки по телефону или почте.
- товары: к какой категории или сегменту относятся покупки, область применения и т.д.
Очистили данные от шума (карты продавцов, возвраты, покупки услуг, а не товаров) и посчитали нужные критерии (процент скидки, возраст). После этого вычислили самый большой и самый маленький чек у каждого покупателя, среднюю, медианную и максимальную скидку, сколько раз человек приходил и сколько товаров из каких категорий покупал. Эти параметры пересчитали на промежутки: последняя неделя, две недели, месяц, три месяца. Такая скрупулезная работа позволила построить модели с высокой точностью прогнозирования.
Первая модель предсказала, кто из покупателей придёт в ближайшие две недели, а вторая выдавала рекомендации: какие товары (до уровня артикула) купит конкретный человек. Агрегировали данные для моделей и запустили расчёты. Кстати, требование прогнозировать популярность конкретных артикулов значительно усложняло задачу (обычно бизнесу достаточно прогнозов по категориям и наименованиям товаров, а не позициям).
Клиенты, рекомендованные моделью для целевой рассылки, за один визит имели более крупный медианный чек, а за анализируемый период купили суммарно на бо̒льшую сумму, чем прочие клиенты.
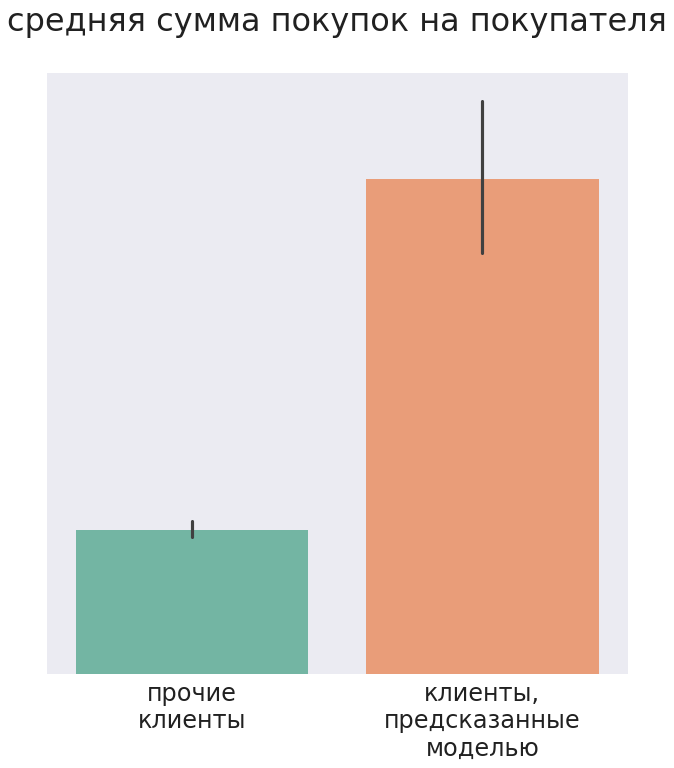
В итоге после рассылки около 30% клиентов приобрели хотя бы один товар из трех, предсказанных моделью.
Это помогает не только оптимизировать логистику, но и снизить сопутствующие расходы. Теперь компания может точнее прогнозировать продажи: ритейлер знает, кто придет к нему в ближайшее время и что купит. Модели также оптимизируют рассылки: специалист на основе прогноза сразу понимает, кому отправить e-mail, а кому — срочное SMS. Например, если конкретный клиент обычно ничего не покупает зимой, то не нужно отправлять ему SMS в январе.
Подводные камни
Они есть в любой ML-задаче — были и в нашей. Например, мы проверяли, помогают ли рассылки с рекомендациями товаров повысить продажи. Для этого предсказанный сегмент покупателей разделили на три группы:
- Контрольная — рассылку не получали.
- Группа с напоминаниями — получали общий текст от магазина.
- Группа с рекомендациями — получали SMS с тремя конкретными товарами, предсказанными моделью.
Оказалось, что люди, получившие рекомендации, покупали меньше, чем клиенты, не получавшие рассылок. Меньше был и средний чек, и количество приобретенных товаров. T-тест показал, что различия были статистически значимы (pvalue=0,017).
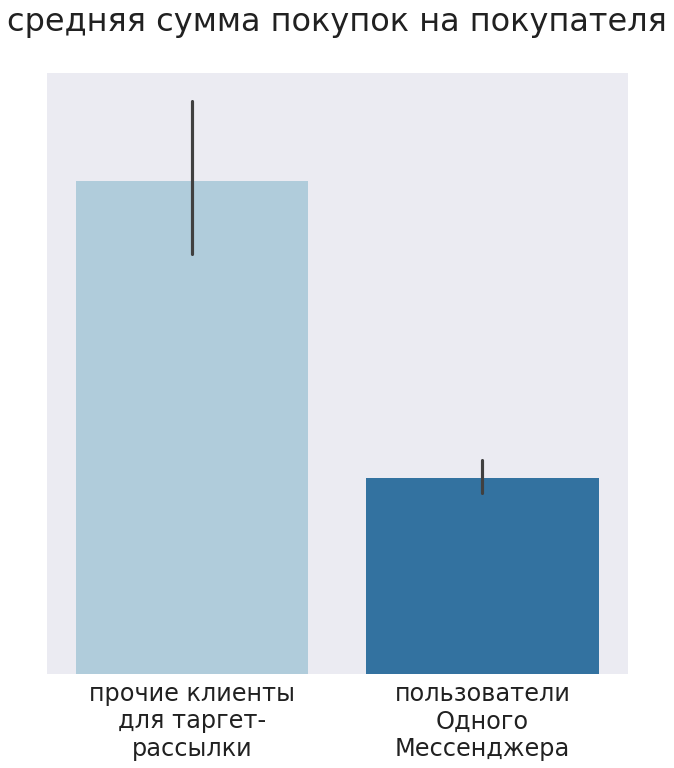
Стали искать причину и выяснили, что магазины отправляли клиентам сообщения в определенный мессенджер, а его пользователи в нашем сегменте изначально покупали меньше по сравнению с другими клиентами. Мягко говоря, такие результаты всех обескуражили. Так что эксперимент получился некорректным, но по его результатам мы добавили в модель параметр «пользователь мессенджера». Об этом не знали даже маркетологи заказчика. Этот случай демонстрирует, как тщательно нужно выбирать каналы для общения с клиентами.
Какие ещё можно сделать выводы?
- Данных много не бывает.
- Иногда взгляд аналитика со стороны приводит к свежей идее.
Сегментация клиентов
Анализ данных позволяет обнаружить закономерности, которые были скрыты в ранее доступной информации. Хорошим примером служит сравнение групп клиентов с помощью RFM-сегментации (Recency Frequency Monetary) и сегментации с использованием алгоритмов ML.
В RFM-сегментации используются три основных показателя:
- давность последней покупки,
- частота покупок за период,
- сумма, потраченная клиентом.
На основании этих данных выделяют основные группы: «транжиры», «лояльные клиенты», «почти потерянные клиенты» и т.п. А маркетологи уже включают нужную целевую группу в определенную рассылку или делают предложение именно для этой группы.
Например, с помощью RFM-сегментации можно выделить сегменты покупателей и представить их как точки в трехмерном пространстве:
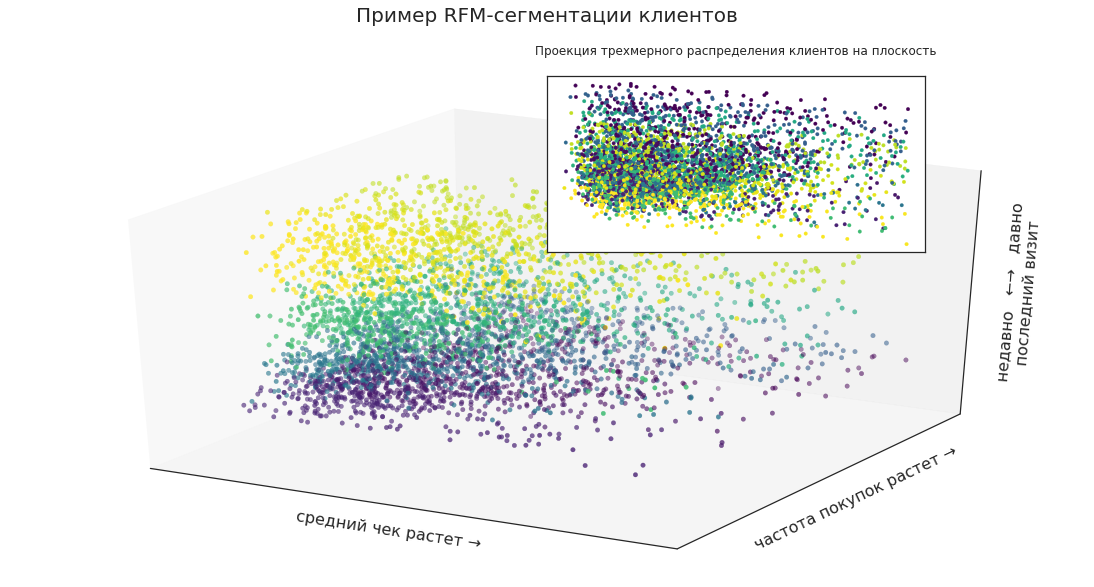
Это позволяет наглядно увидеть расположение определённых групп в общей массе клиентов, их пропорции и динамику изменений.
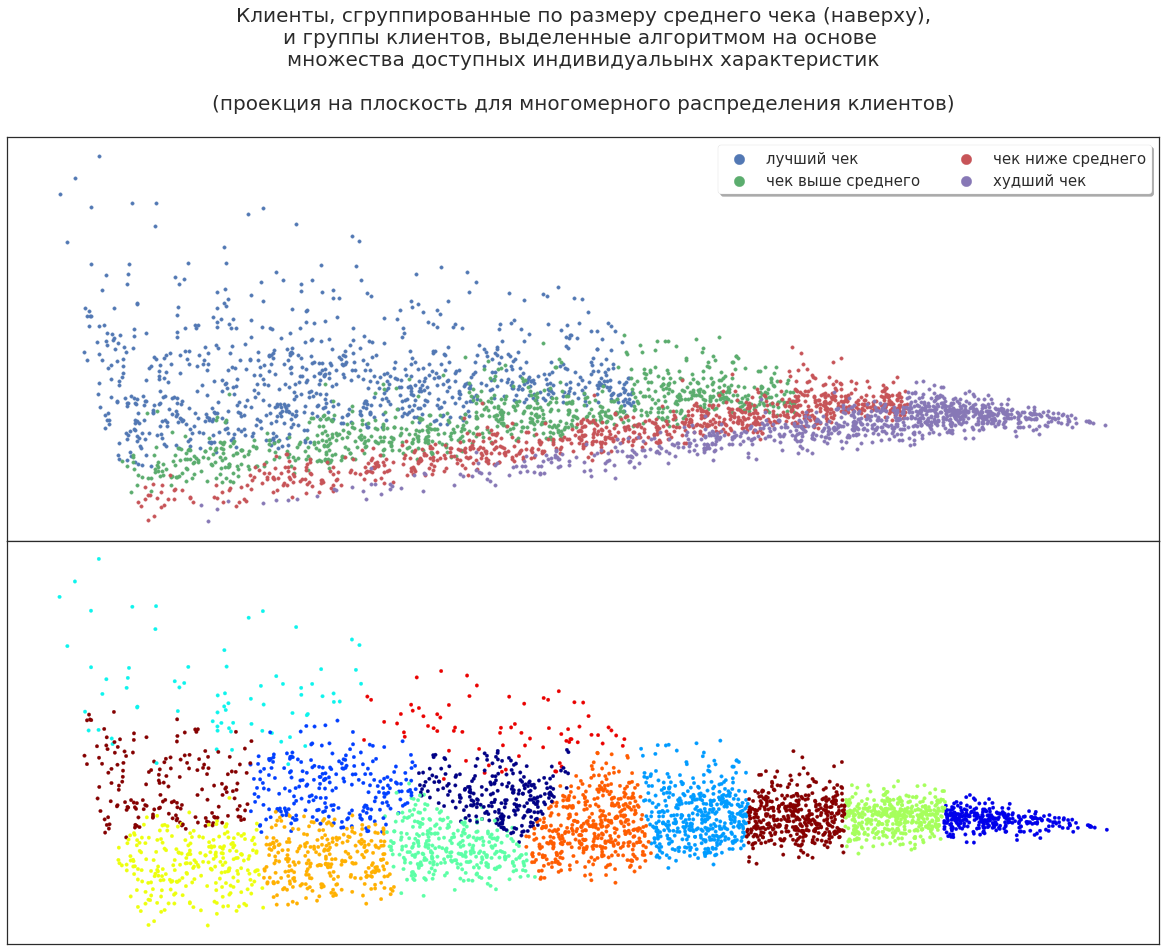
Клиентов можно разделить по приносимому компании доходу, чтобы включать в маркетинговые кампании самых прибыльных, но будет ли этого достаточно для эффективного планирования? Теперь спроецируем трёхмерное распределение сегментов на плоскость.
Можно проанализировать это разбиение, чтобы выяснить, почему алгоритм именно так разделил клиентов. Даже в таких данных алгоритм машинного обучения находит дополнительные возможности: разбивает клиентов на новые большие группы. То есть после первого применения ML можно получить дополнительную информацию о своих клиентах на основе всё тех же данных. Например, некоторые высокодоходные клиенты — эксперты, которые сопровождают своих заказчикаов на шоппинге и используют свои скидочные карты; некоторые активно делятся своими карточками с друзьями и знакомыми.
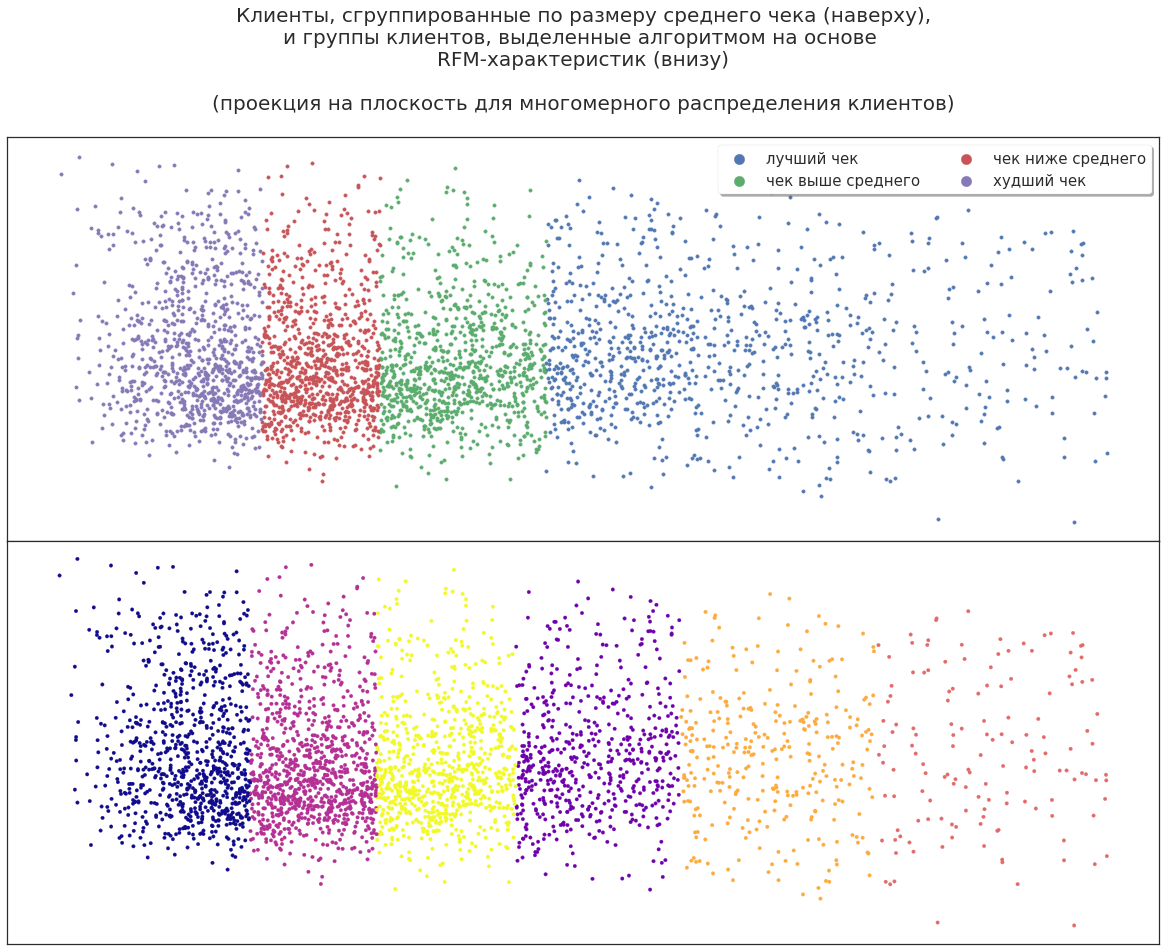
Как теперь алгоритм распределит покупателей? Давайте расширим набор характеристик клиентов: добавим пол, возраст, особенности поведения и прочее.
Почему алгоритм выделил эту группу — вопрос для аналитика. Например, есть группа, которая охватывает как лучших клиентов (самых прибыльных), так и их «соседей», приносящих меньшую прибыль. Или, напротив, эти клиенты не особо перспективны и повышение доходности было случайным отклонением, — стимулировать их дополнительно бессмысленно. Быть может, эти клиенты при дополнительном стимулировании покажут большую доходность. Можно выдвинуть различные теории, но проверять их приходится экспериментально.
Планирование складов — прогнозирование продаж
Дальше у проекта возможны несколько вариантов развития. Например, можно прогнозировать покупки в конкретном магазине на ближайший период. Тогда администратор магазина сможет вовремя заказать с центрального склада нужные товары.
К примеру, если в магазин приходит много покупателей-мужчин, отдел с мужской продукцией не стоит размещать в дальнем углу. Анализ покупок в конкретной торговой точке поможет сформировать и выкладку товаров на витринах.
То есть, если две точки продаж одной сети находятся рядом (например, в разных концах одной улицы), одна из них может оттягивать клиентов на себя, а вторая будет простаивать. Нельзя забывать о так называемой каннибализации магазинов. Можно построить модель, которая станет отслеживать подобные явления и сигнализировать об этом.
***
Часто при построении моделей выявляются неочевидные закономерности, о которых не знали даже бизнес-пользователи. Одним словом, машинное обучение — мощный инструмент, который может многое. Однако качество модели очень сильно зависит от качества и количества данных.
Аналитики Дирекции по разработке и внедрению ПО, «Инфосистемы Джет»


![Фото [Перевод] Анатомия Hello World на языке C](http://orion-int.ru/wp-content/uploads/2024/04/xperevod-anatomiya-hello-world-na-yazyke-c-390x220.png.pagespeed.ic.AxnjwvMFQ9.png)



