
Автороцентричное ранжирование. Доклад Яндекса о поиске релевантной аудитории для авторов Дзена
Важнее всего для сервиса Яндекс.Дзен — развивать и поддерживать платформу, которая соединяет аудитории с авторами. Чтобы быть привлекательной платформой для хороших авторов, Дзен должен уметь находить релевантную аудиторию для каналов, пишущих на любые темы, в том числе на самые узкие. Руководитель группы счастья авторов Борис Шарчилев рассказал про автороцентричное ранжирование, которое подбирает для авторов наиболее релевантных пользователей. Из доклада можно узнать о том, чем такой подход отличается от подбора релевантных айтемов — более популярного в рекомендательных системах.
Балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться правильного соотношения счастья пользователей и счастья авторов.
— Коллеги, всем привет. Меня зовут Боря. Я занимаюсь качеством ранжирования в Дзене. Я уверен, что у нас один из самых интересных сервисов Яндекса, у нас очень крутое машинное обучение, и в следующие 17 минут я вас в этом постараюсь убедить.
Говоря простым языком, Дзен — это сервис персональных рекомендаций. Что такое Дзен? Наша высокоуровневая цель: во-первых, чтобы пользователи хотели в Дзене проводить время, и во-вторых, что очень важно — чтобы они об этом времени не жалели. То есть каждому пользователю в зависимости от того, что мы о нем знаем и что ему интересно, мы стремимся порекомендовать наиболее релевантный контент.
Это бесконечная лента рекомендаций. Примерно так выглядит наша основная форма потребления контента. Тут есть разные тематики: что-то про бизнес, что-то про юмор, даже что-то про фэнтези. И тут видно, что мы, в принципе, стараемся рекомендовать материалы разнообразно. Есть что-то познавательное, что-то образовательное, что-то более лайтовое и развлекательное. Разная направленность. У всех эта лента выглядит сильно по-разному, в зависимости от того, что пользователю интересно. И, разумеется, персонализация. Плюс, конечно, немного рекламы.

В самом начале, когда мы только появились, мы были, по сути, агрегатором контента из интернета. Очень важный момент. Сейчас ситуация совсем иная. То есть мы обходили существующие сайты, брали с них контент и показывали его пользователю в зависимости от интересов. Его приветствует такой приятный экран, а котором мы говорим, что мы человеку будем сами подбирать аудиторию, сами находить ему релевантных читателей и от него требуется только писать хороший контент. Сейчас Дзен — это целая блогерская и авторская платформа, на которой каждый человек может завести свой канал, будь то какой-нибудь известный блогер либо какой-то начинающий человек, которому есть о чем рассказать.
Это число будет только расти. Сейчас на платформу приходится более половины общего трафика в Дзене. Разумеется, мы сделаем это лучше всех. То есть мы понимаем, что ранжировать уже имеющийся контент могут примерно все, вернее пытаться могут все. Но уникальный контент есть далеко не у всех, и мы верим, что именно в этом будет наше конкурентное преимущество.

По данным Яндекс.Радара, число дневных читателей на конец прошлого года — примерно 11 млн в день. Важно понимать, что Дзен уже очень большой. Это значит, что мы на полном серьезе делаем интернет, у нас очень серьезные задачи, их много, и мы очень ждем вашей помощи. И даже, по некоторым данным, по данным того же Яндекс.Радара, мы в прошлом году впервые обошли по цитированию Яндекс.Новости.

Поговорим про детали того, как это работает, и обсудим то, чем же можно у нас заниматься стажеру, чем же можно помочь нашему сервису.
Все начинается с нашей большой базы документов. Общая схема рекомендаций у нас устроена примерно так. Ежедневно появляется порядка миллиона новых документов. Она включает в себя десятки миллионов документов, причем это число пополняется ежедневно. Но, к сожалению, на практике так сделать не получается, потому что Дзен работает в реальном времени. В идеале мы бы хотели применить весь наш аппарат машинного обучения ко всем этим десяткам миллионов персонально для каждого пользователя и выбрать ему самое-самое релевантное. Этот этап сужения базы с десятков миллионов примерно до тысяч у нас называется отбором кандидатов или легким ранжированием. У нас есть очень жесткие гарантии на то, насколько быстро мы готовы отвечать, поэтому из практических соображений мы вынуждены на первом этапе сужать базу из десятков миллионов документов до нескольких тысяч потенциальных рекомендаций, которые мы уже можем полностью отранжировать нашей моделью и выбрать из них самые релевантные.
Тут все без сюрпризов, но факторы у нас очень разнообразные. Когда у нас есть этот набор, мы применяем к нему нашу сложную большую модель машинного обучения, которая на верхнем уровне представляет из себя градиентный бустинг. Но есть и более сложные факторы, которые основаны, например, на каких-нибудь нейросетевых признаках. Они варьируются от каких-то простых, которые характеризуют, например, то, насколько пользователю релевантен данный домен, насколько часто он заходит на данный источник, кликает, оставляет фидбек, лайки и дизлайки. Вся эта схема довольно сложная, в деталях рассказать не успею. Мы обрабатываем текст статьи, картинки, другие источники данных и такие композитные признаки тоже используем.
Размер топа зависит от того, сколько контента нам надо порекомендовать. После того, как мы отранжировали наши 2000 кандидатов, мы берем из них топ. Таким образом мы формируем итоговую выдачу. Это всегда определяется по-разному.
Теперь давайте поговорим о том, какие же компоненты всего этого процесса нам интересно улучшать. Так выглядит схема на высоком уровне.

Задач очень много. Оказывается, что нам интересно заниматься примерно всем. То есть нам интересно и увеличивать скорость доставки данных для ранжирования (чем более свежие у нас данные, тем более релевантные мы делаем рекомендации). И пользы можно принести примерно везде, будь то какие-то инфраструктурные задачи. Нам интересно повышать надежность. Нам интересно ускорять время работы сервиса (чем быстрее работаем, тем лучше пользовательский экспириенс). Нам важно, чтобы сервис был всегда доступен, всегда работал.
То есть нам нужно как применять какие-нибудь новые модели машинного обучения, так и улучшать наши модели в других странах. Нам важно улучшать ранжирование. Мы рекомендуемся не только в России, но и во многих других странах.
Нам интересно также учитывать региональность, то есть учитывать то, из какого региона пользователь, и рекомендовать ему то, что ему релевантно по региону.
Это наше будущее, нам надо в нее вкладываться. И очень важно — нам надо развивать нашу авторскую платформу. В частности нам нужно уметь находить и бустить качественный контент. Задач тут тоже очень много. Нам нужно уметь ранжировать новые форматы контента. Нам важно показывать хорошие материалы, а не какой-то треш. Все эти форматы нужно уметь ранжировать. У нас есть не только статьи, но и короткие видео, и посты, которые пользователи смотрят прямо в ленте.
Давайте поговорим подробнее, в чем же здесь проблема и как мы ее решаем. И очень важный момент, о котором я хочу поговорить немного подробнее в более технических деталях — нам важно уметь для каждого автор находить ему релевантную аудиторию, даже если речь идет о довольно нишевых авторах.
Давайте рассмотрим это на примере.
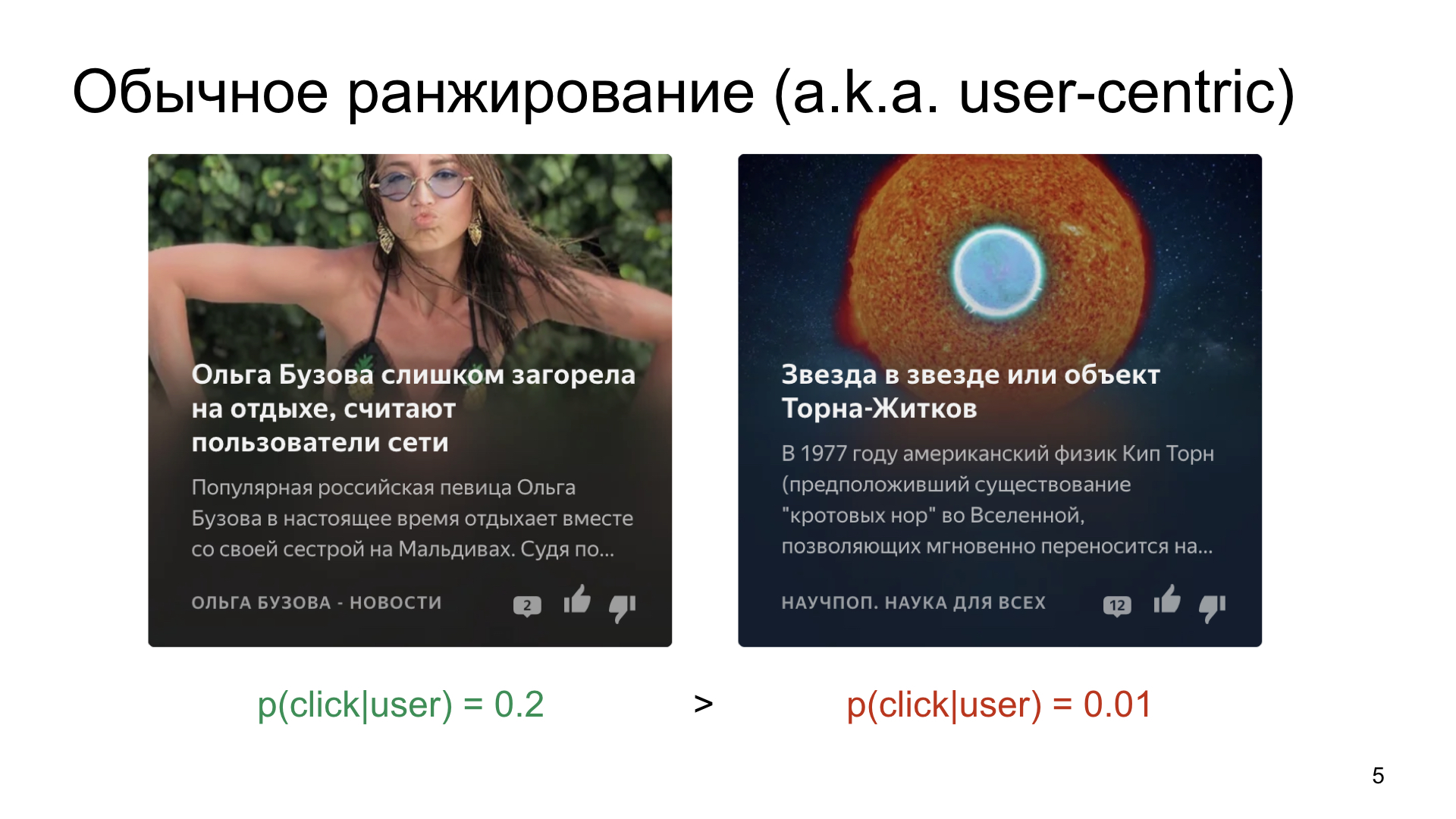
Так устроен мир и человек, что есть нечто более среднепопулярное, где вероятность клика в среднем процентов 20, а есть что-то более нишевое, например статьи про науку или про космос. Мы выбираем, предположим, из двух карточек, которые мы хотим пользователю показать.
Конечно, нам такого не хочется, а хочется как-то находить релевантную аудиторию даже для таких узких каналов. Если мы просто ранжируем карточки по вероятности клика, то, разумеется, так как в среднем более кликабельный более простой контент, он будет собирать очень большое количество показов, а даже хорошая статья про науку может остаться с десятком или сотней показов.

На самом деле, здесь есть две причины. Почему это хочется делать? То есть мы хотим, чтобы Дзен был некоторым срезом интернета. Первая — продуктовая. То есть мы хотим, чтобы все, что пользователь может найти и чем он интересуется в большом интернете, было представлено в Дзене, чтобы мы всем могли найти что-то, что ему релевантно.
Он связан с тем, как у нас устроен сервис. Наконец, такой момент. Если ей показать науку и популярный контент, они на этот контент кликнут с большей вероятностью, чем на науку. На самом деле, например, у научных каналов есть своя какая-то аудитория. Вопрос в том, как находить таких людей и как делать так называемые показы не для пользователя, а для автора. Но если им показать только науку, они на науку тоже кликнут, и даже ничуть об этом не расстроятся.

Так как мы сейчас обсудили, обычная формула ранжирования, которая предсказывает вероятность кликов, нам здесь не поможет, потому что в среднем более нишевые статьи будут часто проигрывать. Как же это делать? Так делать можно, и это сделает авторов немного счастливее, но, к сожалению, это сделает менее счастливыми наших пользователей. Но можно пойти другим путем — выделить некоторую квоту, и в ней более-менее равномерно как-нибудь случайно авторам налить, дать какую-нибудь нижнюю гарантию. Мы этого, конечно, не хотим. Пользователи будут меньше кликать, больше расстраиваться и уходить.
Как здесь быть?
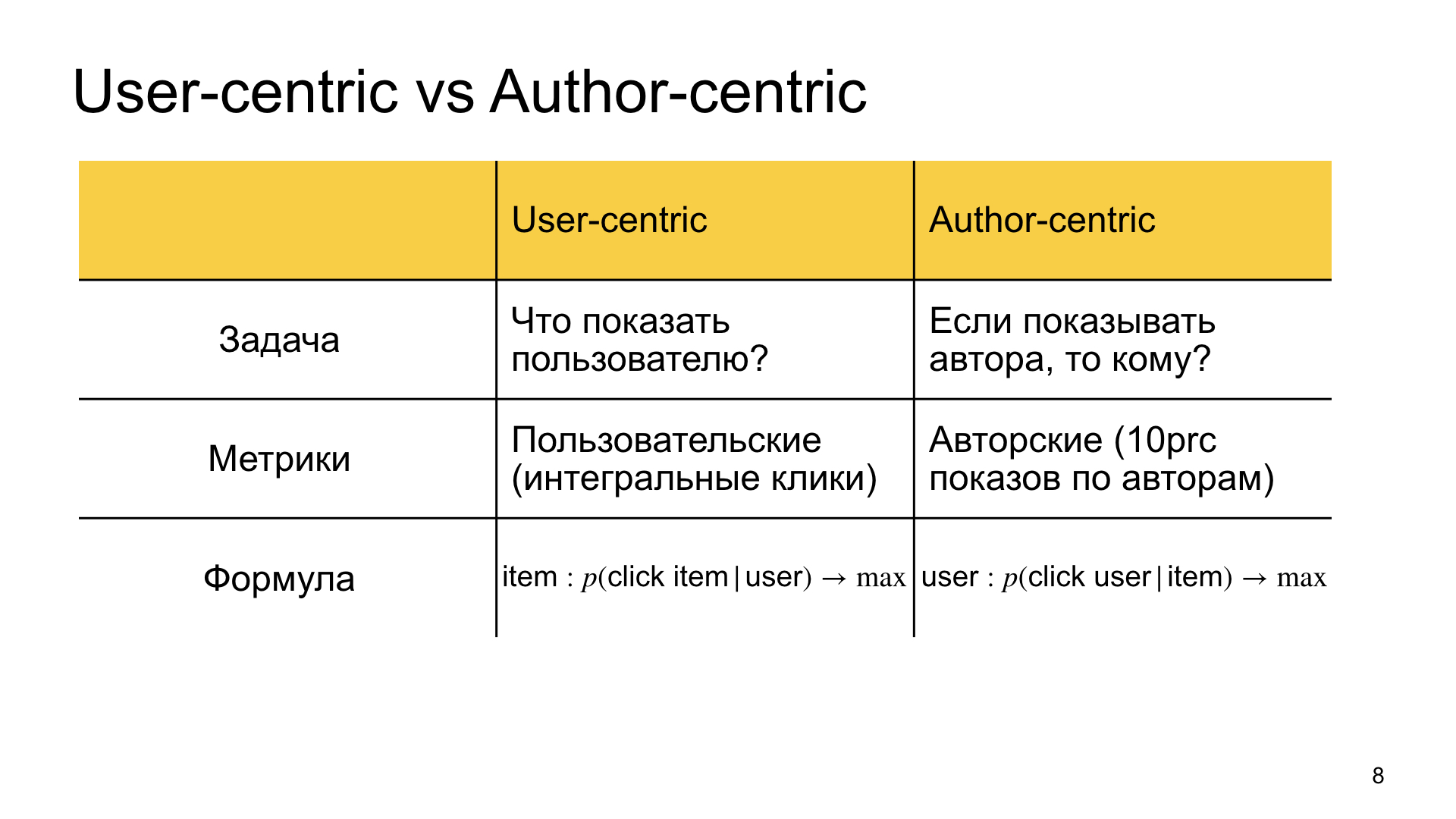
Концептуально разница формулируется так. Мы долго думали и придумали такую немного претенциозную концепцию, назвали ее автороцентричным ранжированием или показами для автора.
Найти материал, который наиболее релевантен пользователю. В обычном ранжировании, которое мы называем пользователецентричным, что нам интересно? В автороцентричном ранжировании мы как бы переворачиваем постановку задачи и говорим, что мы хотим показать данного автора, и вопрос в том, кому его показать, кому он наиболее релевантен. Мы отвечаем на вопрос, что показать пользователю. В первом случае нас больше интересуют пользовательские метрики, то есть интегральные клики, интегральное время в Дзене, и т. Отсюда и разница в метриках. Во втором же случае нас интересуют так называемые авторские метрики. д. Если им живется достаточно хорошо, то и все остальные и подавно будут счастливы. Например, мы измеряем то, насколько хорошо живется в Дзене, например, bottom 10% авторов.

Немного деталей. Как мы это делаем? Для простоты предположим, что она предсказывает вероятность клика пользователя на данный айтем, на данную карточку. Предположим, что у нас есть обычная формула ранжирования. Давайте теперь для каждой статьи зафиксируем ее и применим нашу модель для этой статьи, в идеале — ко всем пользователям, на практике — к какому-то семплу пользователей. Что мы сделаем? Теперь для каждой статьи у нас есть такое распределение, как на графике (слайд выше — прим. И построим распределение наших scores, то есть оценок вероятности кликнуть на статью, для каждой статьи по пользователям. После этого отранжируем статьи для пользователя и выберем топ не просто по вероятности клика, а по перцентили, в которую данный пользователь попадает для данной статьи. ред.). То есть мы оценим вероятность клика, посмотрим, куда пользователь попадает в этом распределении, и отранжируем по данной величине.

Вот у нас те же самые две карточки, одна из них в среднем более кликабельна, 20%, другая менее кликабельна, 1%. Сначала про интуицию того, что произошло. Скажем, 10% против 3%. Теперь, если взять конкретного пользователя, возможна такая ситуация, что у него на более популярную карточку вероятность клика больше, чем на менее популярную. А в другой ситуации наоборот: у него вероятность клика 3%, но в среднем у статьи — 1%. Но так как в среднем вероятность клика на популярную карточку — 20%, а у пользователя — 10%, то он в среднем менее релевантен данной публикации, чем средний пользователь Дзена. И ключевой инсайт здесь в том, что даже когда вероятность клика на статью меньше, с помощью такого фреймворка мы имеем шанс показать менее популярную статью, если пользователь входит в наиболее доверенное ядро для данной публикации. Поэтому он входит в более релевантную для статьи аудиторию, чем остальные пользователи Дзена.

Подробно не буду особо рассказывать, но можно доказать такое утверждение: если хочется, чтобы пользователи приходили к нам более-менее равномерно, то данный score, по которому мы ранжируем, то есть перцентиль, куда попадает каждый пользователь, будет распределен равномерно по пользователям. Тут есть, на самом деле, некоторая математика. Не будет выбросов в десятки миллионов показов против 10 у каких-нибудь менее релевантных карточек. Это значит, что если все статьи ранжировать таким образом, то в среднем все соберут более-менее одинаковое количество показов. Таким образом, балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться правильного соотношения счастья пользователей и счастья авторов.
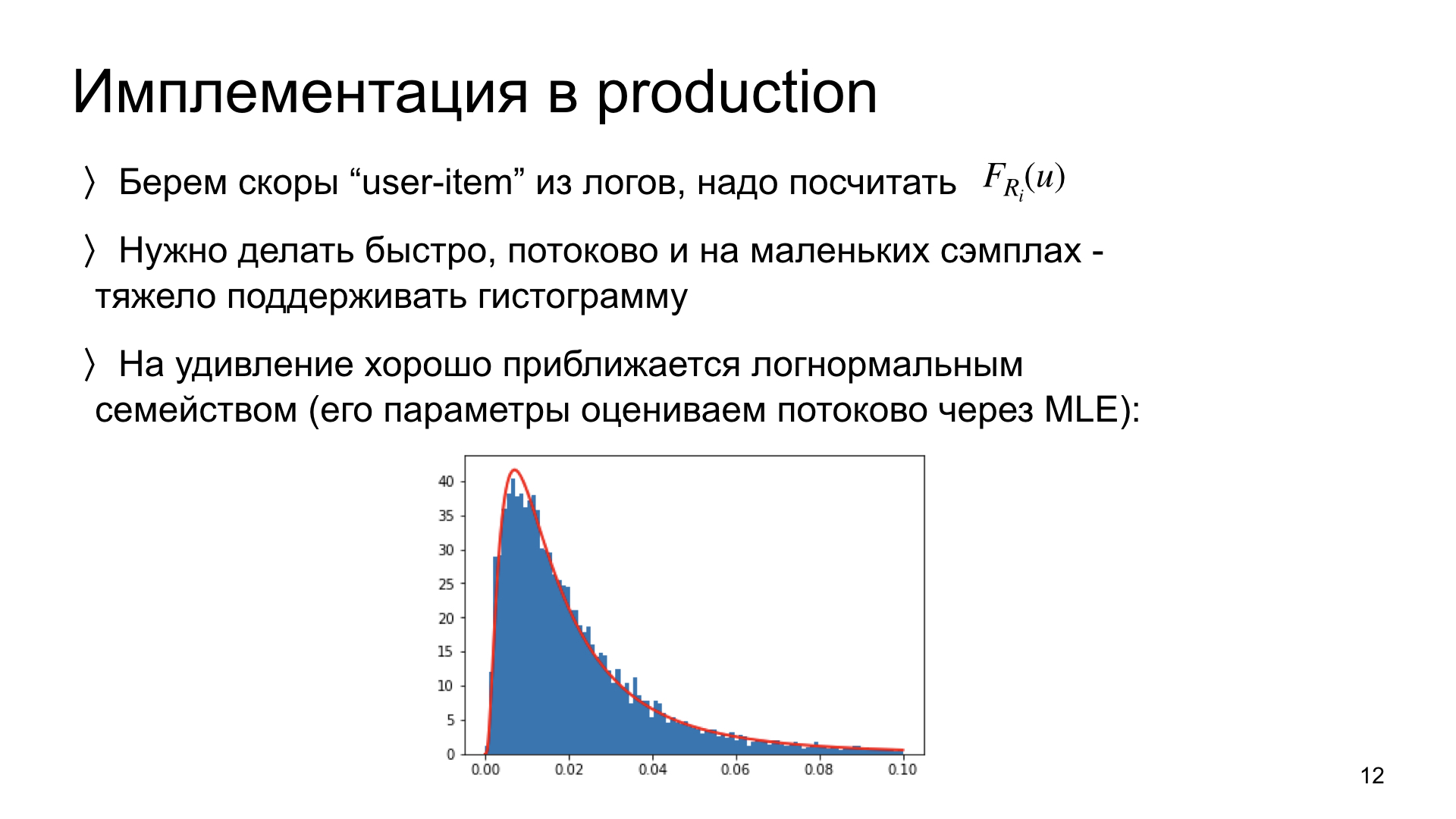
Нам нужно посмотреть на наши логи и из них посчитать данное распределение для каждой статьи. Пару слов о том, как мы это реализовываем в продакшене. То есть в идеале для того, чтобы обновить оценку распределения по новым данным, нам нужно иметь в памяти не все предыдущие данные, а только текущую оценку. Важное ограничение: нам нужно уметь это делать, во-первых, быстро, во-вторых, в потоковом режиме. В идеале нам нужно уметь это делать на маленьких данных. Такая система масштабируется, такая схема работает. Если у какой-нибудь статьи всего 300 показов, то нам нужно уметь за такое количество наблюдений адекватно оценить распределение.
То есть это эмпирическое наблюдение. Мы провели эксперименты и обнаружили, что такие распределения scores на удивление хорошо приближаются к лог-нормальным распределениям. Причем мы можем это делать в потоке, используя только текущую оценку параметров и новые наблюдения. А раз так, то мы вместо того, чтобы оценивать не параметрически всю гистограмму распределения, можем оценить только два параметра данного распределения. Сейчас она у нас находится в продакшене. Такая схема получается очень быстрой и работает очень хорошо.
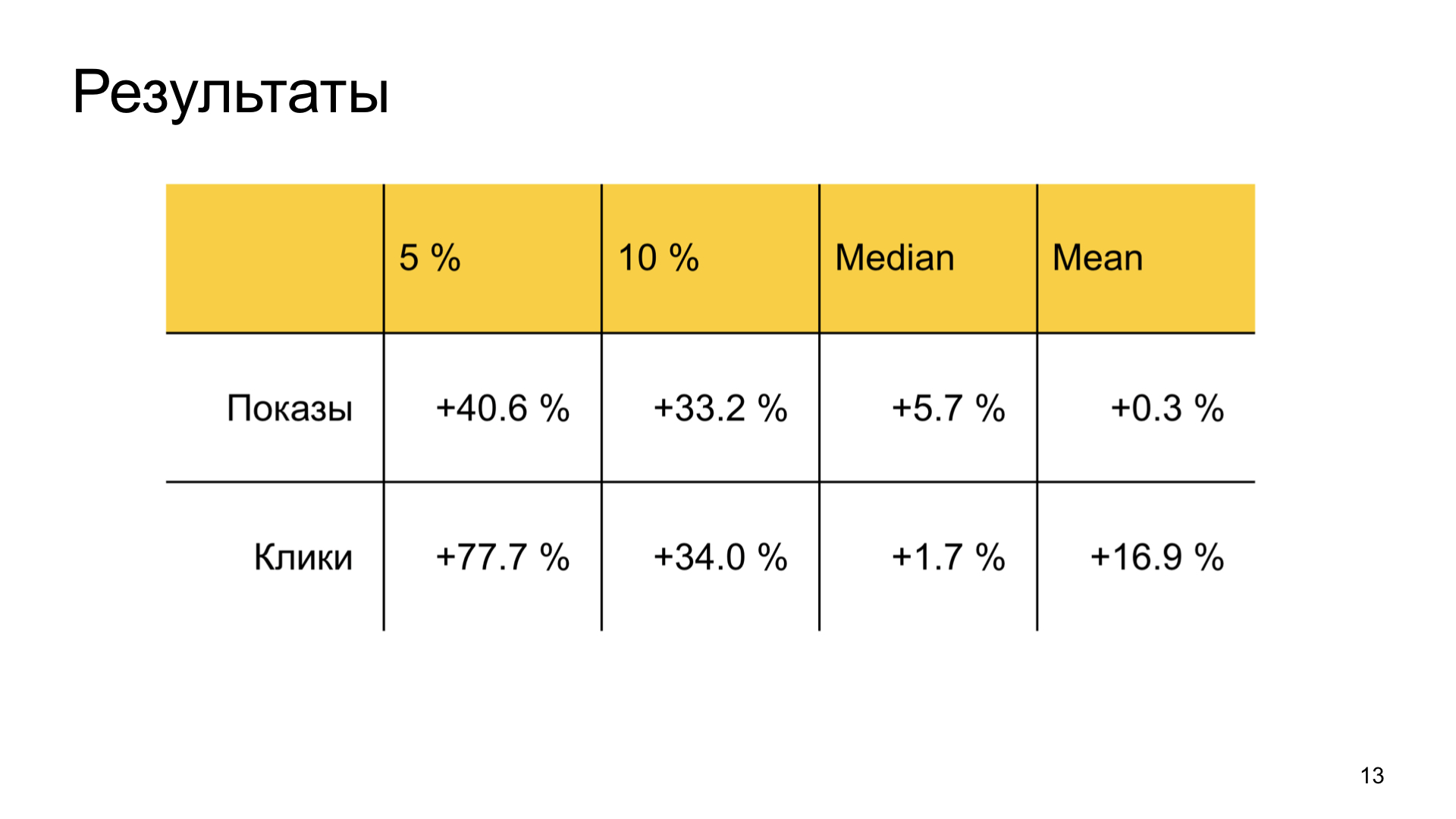
Мы сильно растим счастье обделенных хороших авторов в Дзене и при этом не просаживаем общие пользовательские метрики. Результаты тоже получаются хорошими. То есть бизнес-задача полностью достигается.
Разумеется, этих задач много, и с каждой из них нам нужна ваша помощь. Я сейчас привел только один из примеров задач, которыми у нас можно заниматься. Напоследок скажу пару слов о том, чего же мы ждем от стажеров и чего мы от них не ждем. Очень надеемся, что вы захотите у нас работать. У нет в сервисе все дата-саентисты, все ML-инженеры должны уметь делать полный цикл задач. От стажера мы ждем самого главного — умения писать код. То есть мы ожидаем, что вы умеете писать код на базовом уровне, понимаете подходы, знаете алгоритмы, структуры данных, основы машинного обучения. Они должны уметь и имплементировать свое решение в production, и применять ML.
То есть если вы не знаете, как работают корутины в Python — ничего страшного, мы вас всему научим. Чего мы не ждем от стажеров — так это, в первую очередь, глубокого знания каких-то языков или фреймворков. Мы ждем от вас знаний, желания работать. И мы не ждем от вас большого опыта. Всему научим, и все будет хорошо. Если нет опыта — ничего страшного. Спасибо!





![Фото [Перевод] Gmail исполнилось двадцать лет](http://orion-int.ru/wp-content/uploads/2024/04/perevod-gmail-ispolnilos-dvadcat-let-220x150.jpg.pagespeed.ce.UvOK2tKHyL.jpg)
